自适应滤波器简介
工程应用中为了保证绝对的稳定性,一般使用FIR滤波器来设计自适应滤波器。
自适应滤波器的原理框图如下图所示,其中x(n)为输入信号,wn为FIR滤波器的系数,d(n)为期望信号,e(n)为误差信号。
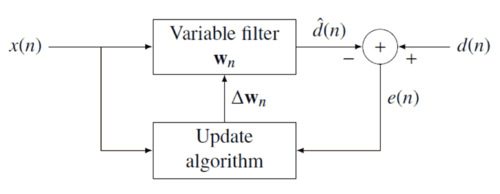
自适应滤波器的运行涉及两个基本过程:滤波过程和自适应过程。滤波过程即输入信号与滤波器系数的卷积过程,用来对一系列输入数据产生输出响应;自适应过程是通过特定的算法以不断缩小响应信号与期望信号的均方误差为目的,来实现对滤波器参数的自适应调节。具体的运行步骤如下:
(1)在自适应滤波器运行之前,已知输入信号 x(n)和期望信号 d(n);
(2)自适应滤波器运行时,FIR滤波器中每次卷积得到的结果d^(n)与d(n)做差即得到一个误差信号e(n);
(3)更新算法使用x(n)和e(n)作为输入,输出Δwn来修正FIR滤波器的参数。
(4)重复b和c的步骤,直到误差信号的均方值小于某一设定的数值,这样就说明得到的FIR滤波器可以应用于实时处理系统中了。
自适应滤波器相关的算法包括最小均方(LMS)算法、归一化最小均方(NLMS)算法、递归最小二乘(RLS)算法等。
LMS
LMS算法的权重更新公式为:(u(n)相当于上面的x(n))
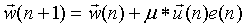
其中初始化参数为:权重向量w可以初始化为零向量,步长μ可以根据运行情况调整。
LMS算法的优点是计算量较小,其缺点是瞬时跟踪能力较弱,抗干扰能力较差。
NLMS
NLMS算法的权重更新公式为:

其中初始化参数为:权重向量w可以初始化为零向量,步长μ可以根据运行情况调整。
NLMS算法的优点是对于能量较大、不是很平稳的信号也有较快的收敛性和较好的平稳性,缺点是相比于LMS增加了额外的乘法计算。
RLS
RLS算法的权重更新公式为:
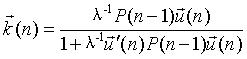
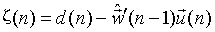
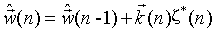
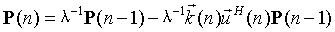
其中初始化参数为:权重向量w可以初始化为零向量,P(0)=δ-1I;δ的值根据输入信号信噪比的不同或实际运行情况进行调整。
RLS算法的优点是收敛速率比一般的LMS算法快一个数量级,且算法的抗干扰效果特别好,在有噪声条件下收敛情况很好,其缺点是迭代方式较复杂、计算量很大。
MATLAB程序
MATLAB程序演示了LMS和RLS算法,并进行了收敛速度与稳定性对比。
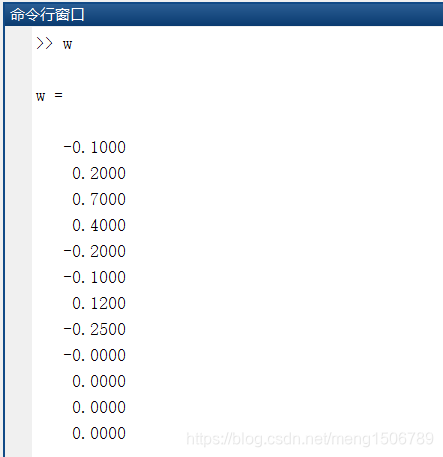
程序中设置了参考滤波器wo的参数为:
wo=[-0.1 0.2 0.7 0.4 -0.2 -0.1 0.12 -0.25 0 0 0 0];
在使用LMS或RLS算法逐渐收敛的过程中,滤波器参数从初始的零向量逐渐趋近wo向量。
clc
clear
close all
dotnumber=1000000;% 数据点数
%构造原始数据
u=wgn(dotnumber,1,0);% wgn(m,n,p)产生一个m行n列的高斯白噪声的矩阵,p以dBW为单位指定输出噪声的强度
noise=wgn(dotnumber,1,-60);
b=1;a=[1 -0.9];
u=filter(b,a,u);% filter(b,a,X) X为输入数据,其中b是分子系数向量,a是分母系数向量 a=1是FIR滤波器
u(dotnumber+1:end)=[];% end是数组的结尾,将从dotnumber+1:end的数据删除
h=[-0.1 0.2 0.7 0.4 -0.2 -0.1 0.12 -0.25].';% 取非共轭转置,下面加点代表非共轭
wo=[h;zeros(4,1)];% 抽头权向量是12阶,后面补零
%构造参考输出
d=filter(h,1,u);% filter(b,a,X) X为输入数据,其中b是分子系数向量,a是分母系数向量 a=1是FIR滤波器
d(dotnumber+1:end)=[];% end是数组的结尾,将从dotnumber+1:end的数据删除
d=d+noise;% 加上测量误差
%初始化
len=12;
w=zeros(len,1);% 设置权值初始值为0
w_error=zeros(dotnumber,1);% 用于记录误差
e=zeros(dotnumber,1);
vector_u=zeros(len,1);% 抽头输入向量为12行的列向量
%% RLS_1
%初始化RLS参数
delta=0.001;% 高SNR时取较小的正常数 小数值收敛快 % 低SNR时取较大的正常数
P=1/delta*eye(len);% eye(n):返回n*n单位矩阵
ramda=1;% ramda=1 无限记忆 当ramda小于1时最终达不到稳态,而且整体误差较大
p_i=eye(1,12);% eye(m,n):返回m*n单位矩阵
k=eye(1,12);
for n=1:dotnumber
vector_u=[u(n);vector_u(1:end-1)];% 抽头输入向量
p_i=P*vector_u;% 先计算pi用以减少后面的计算
k=p_i/(ramda+vector_u.'*p_i);% 更新增益向量k
sai(n)=d(n)-w'*vector_u;% 更新先验估计误差sai
w=w+k*sai(n);% rls 更新抽头权值w
P=(1/ramda).*P-(1/ramda)*k*vector_u.'*P;% 更新逆相关矩阵P
w_error(n)=norm(w-wo)^2;% 计算误差并记录
% norm(A) 返回向量A的2范数,即等价于norm(A,2)。即各元素平方和开根号
end
figure;
plot(10*log10(w_error));
%% RLS_2
%清空上次的计算
w=zeros(len,1);
w_error=zeros(dotnumber,1);
e=zeros(dotnumber,1);
vector_u=zeros(len,1);
%清空上次的RLS参数
delta=2;
P=1/delta*eye(len);
ramda=1;
p_i=eye(1,12);
k=eye(1,12);
for n=1:dotnumber
vector_u=[u(n);vector_u(1:end-1)];
p_i=P*vector_u;
k=p_i/(ramda+vector_u.'*p_i);
sai(n)=d(n)-w'*vector_u;
w=w+k*sai(n);%rls
P=(1/ramda).*P-(1/ramda)*k*vector_u.'*P;
w_error(n)=norm(w-wo)^2;
end
hold on;
plot(10*log10(w_error));
%% LMS_1
%清空上次的计算
w=zeros(len,1);
w_error=zeros(dotnumber,1);
e=zeros(dotnumber,1);
vector_u=zeros(len,1);
%初始化LMS参数
mu=0.003;
for n=1:dotnumber
vector_u=[u(n);vector_u(1:end-1)];
y=vector_u.'*w;
e(n)=d(n)-y;
w=w+mu*e(n)*vector_u;%lms
w_error(n)=norm(w-wo)^2;
end
hold on;
plot(10*log10(w_error));
%% LMS_2
%清空上次的计算
w=zeros(len,1);
w_error=zeros(dotnumber,1);
e=zeros(dotnumber,1);
vector_u=zeros(len,1);
%初始化LMS参数
mu=0.001;
for n=1:dotnumber
vector_u=[u(n);vector_u(1:end-1)];
y=vector_u.'*w;
e(n)=d(n)-y;
w=w+mu*e(n)*vector_u;%lms
w_error(n)=norm(w-wo)^2;
end
hold on;
plot(10*log10(w_error));
legend('RLS 0.001','RLS 2.000','LMS 0.003','LMS 0.001');%改变delta
xlabel('采样点数(迭代次数)');ylabel('系统误差 /dB');
title('自适应滤波器仿真');
运行结果
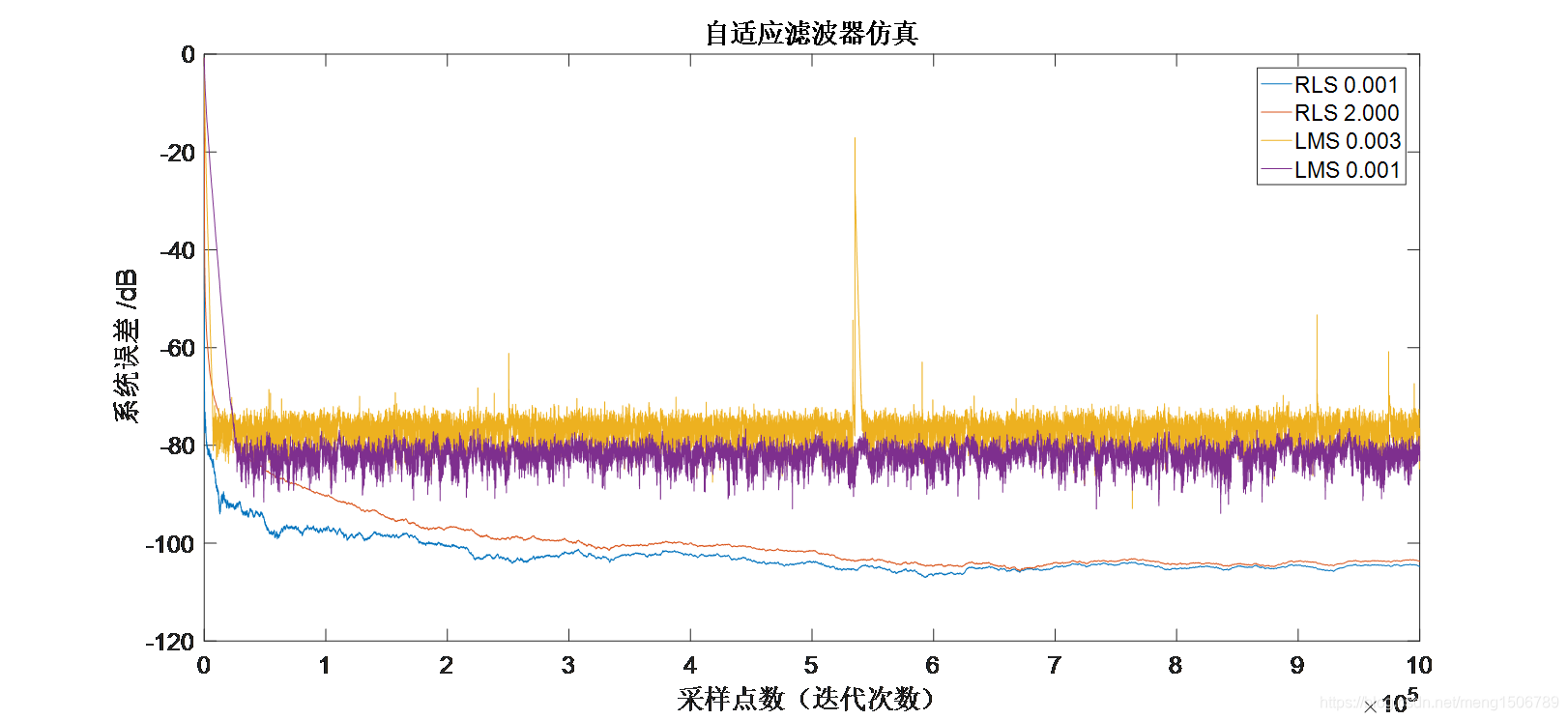
从结果图中可以看到:对于LMS,步长μ越大,收敛速度越快,但同时在达到厚脸极限时也会造成较大的系统误差;RLS相比于LMS,收敛后得到的系统误差更小且波动性更小。