简介
无监督学习是与有监督学习相对应的概念。
一句话解释版本:
无监督学习不知道预测主体,它是在一堆堆数据中不断挖掘并寻找数据之间的关系,而不是通过选取自变量预测因变量。
数据分析与挖掘体系位置
无监督学习的目的性没有有监督学习那么强,但是它也是数据挖掘中关键的一部分,同样属于数据建模下。
它在整个数据分析与挖掘体系中的位置如下图所示。
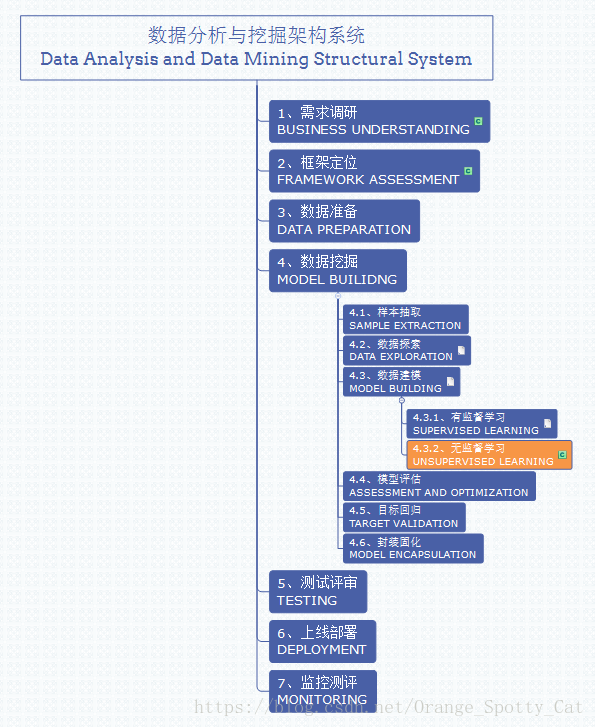
无监督学习的定义
在有监督学习(Supervised Learning)中,我们的样本数据中通常包含p种特征量(features),X1, X2, . . . , Xp。他们有共同的对象(Response),Y。有监督学习的目的简单而言,都是一句话:用X去预测Y。
而在无监督学习(Unsupervised Learning)中,我们的样本一般只有p种特征量(features),X1, X2, . . . , Xp。我们并不关心Y是什么。这也就是说,无监督学习中,我们要预测的东西一般不被关心,也不会出现。无监督学习的目的是探索并发现各种X之间的关系。
举例来说,我们现在有如下的数据,分别是:身高、体重、每天睡眠时间、每天运动时间、以及寿命。如果我们把寿命看作我们想要预测的对象,那么寿命就是上面说的对象,即Y。其余的变量,如身高、体重、每天睡眠时间、每天运动时间就都是特征量,即X。
那么,在有监督学习中,我们研究的目的一般就是各种人的基本特征与寿命之间的关系,即如何通过身高、体重、每天睡眠时间、每天运动时间来预测寿命。
然而,在无监督学习中,我们不研究寿命是受什么因素决定的,我们的兴趣在身高、体重、每天睡眠时间、每天运动时间这些因素上。我们可能会研究这些因素是否都与另外的某种因素共同相关?是否可以用其他的特征量来代替现在有的,以帮助我们进行更好地预测?这些特征量之间是否有群聚关系?是否某几个特征量较其余的更加相似?如果我们更感兴趣的是因素之间的关系,而非因果预测关系,那么很可能我们在做的就是无监督学习。
无监督学习的模型
无监督学习一般包括如下几个被广泛应用的模型与方法:
- 降维分析(Methods of Dimensions Reduction)
- 聚类分析(Methods of Clustering)
- 关联分析(Correlation Analysis)
其中,聚类分析在近期的发展十分迅速,如果了解Python中的sklearn模块,则能够发现降维分析与聚类分析的分支非常广泛。如果将上面的三种模型继续细分可以得到如下各有所长,各有针对性的模型:

上面的三种分析方法中, 降维分析主要针对数据挖掘中的Problem of Dimension。在真实的数据挖掘中,我们拥有的特征量很可能会远远大于我们的观测量,这就造成了数据挖掘中常见的高纬度问题。过高的数据维度使得实际分析的数据精度与可靠性下降,模型的拟合度与可用性降低。 降维分析则是通过一系列数学算法将高纬度数据进行降维处理,提高数据的可用性。
聚类分析则是侧重数据之间的关系,它主要通过衡量数据间的距离、密度等指标,以此定义数据之间的亲密关系,将数据关系近的聚为一类,将数据关系远的聚为另一类。以此实现数据的分群。
关联分析则是通过算法,寻找特征量之间的互动规律。基于数据之间的相关性,关联分析多用于探索特征量之间的相互影响规律。