文章目录
1. 无监督学习基本原理
机器学习或统计学习一般包括监督学习、无监督学习、强化学习
无监督学习:从无标注数据中学习模型的机器学习问题
- 无标注数据是自然得到的数据
- 模型表示数据的
类别、转换或概率 - 本质:学习数据中的统计规律或潜在结构,主要包括 聚类、降维、概率估计
- 基本想法:对给定数据(矩阵数据)进行某种
“压缩”,找到数据的潜在结构,假定损失最小的压缩得到的结果就是最本质的结构 - 考虑发掘数据的纵向结构,对应聚类
- 考虑发掘数据的横向结构,对应降维
- 考虑发掘数据的纵向与横向结构,对应概率模型估计
2. 基本问题
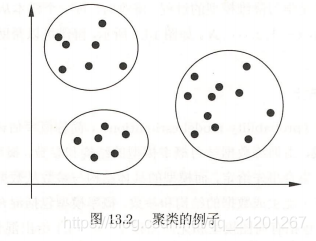
2.1 聚类 Clustering
聚类 是将样本集合中相似的样本(实例)分配到相同的类,不相似的样本分配到不同的类。
- 聚类分 硬聚类(一个样本只属于一个类)和 软聚类(一个样本可属于多个类)
- 聚类方法有 层次聚类 和
均值聚类
2.2 降维 Dimensionality Reduction
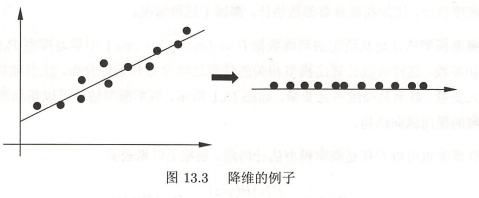
降维 是将样本集合中的样本(实例)从高维空间转换到低维空间。降维可以帮助发现数据中隐藏的横向结构
假设样本 原本存在于低维空间,或近似地存在于低维空间,通过降维可以更好地表示样本数据的结构,更好地表示样本之间的关系
- 降维有
线性降维和非线性降维,降维方法有主成分分析
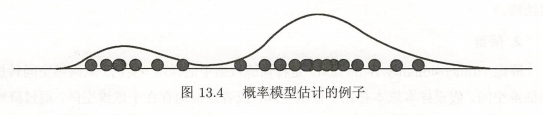
2.3 概率模型估计
假设训练数据由一个概率模型生成,同时利用训练数据学习概率模型的结构和参数
- 概率模型包括
混合模型、概率图模型等 - 概率图模型又包括
有向图模型和无向图模型 - 概率模型估计可以帮助发现数据中
隐藏的横向纵向结构
3. 机器学习三要素
同监督学习一样,无监督学习也有三要素:模型、策略、算法
模型 就是函数 ,条件概率分布 ,或 ,在聚类、降维、概率模型估计中拥有不同的形式
- 聚类 中模型的输出是 类别
- 降维 中模型的输出是 低维向量
- 概率模型估计 中的模型可以是混合概率模型,也可以是有向概率图模型和无向概率图模型
策略 在不同的问题中有不同的形式,但都可以表示为目标函数的优化
- 聚类 中样本与所属类别中心距离的最小化
- 降维 中样本从高维空间转换到低维空间过程中信息损失的最小化
- 概率模型估计 中模型生成数据概率的最大化
算法 通常是迭代算法,通过迭代达到目标函数的最优化,比如,梯度下降法。
- 层次聚类法、k均值聚类 是硬聚类方法
- 高斯混合模型 EM算法是软聚类方法
- 主成分分析、潜在语义分析 是降维方法
- 概率潜在语义分析、潜在狄利克雷分配 是概率模型估计方法
4. 无监督学习方法
4.1 聚类
聚类主要用于数据分析,也可以用于监督学习的前处理
- 可以帮助发现数据中的统计规律
- 数据通常是连续变量表示的,也可以是离散变量表示的
4.2 降维
降维主要用于数据分析,也可以用于监督学习的前处理
- 可以帮助发现
高维数据中的统计规律 - 数据是连续变量表示的
4.3 话题分析
话题分析是文本分析的一种技术
- 给定一个文本集合,话题分析旨在
发现文本集合中每个文本的话题,而话题由单词的集合表示。 - 话题分析方法有
潜在语义分析、概率潜在语义分析、潜在狄利克雷分配
4.4 图分析
图分析 的目的是 发掘隐藏在图中的统计规律或潜在结构
- 链接分析 是图分析的一种,主要是发现 有向图中的重要结点,包括 PageRank 算法
- PageRank 算法最初是为互联网搜索而提出。将互联网看作是一个巨大的有向图,网页是结点,网页的超链接是有向边。PageRank 算法可以算出网页的 PageRank 值,表示其重要度,在搜索引擎的排序中网页的重要度起着重要作用
