Sequence to Sequence (seq2seq) and Attention 原文链接
seq2seq 是序列到序列的应用,为了解决输出和输出不等长的问题,现在已经广泛应用在例如机器翻译,人机问答,图片文字描述等内容生成上。输入与输出的序列长度是可变的!!

encoder-decoder框架:

condetional language models(条件语言模型)
在原先的语言模型上输入与输出是一种类型数据,而在CLM中可以是其他的源信息,例如图片信息,语言,语音信息等。

具体工作流程如下:
将源词和先前生成的目标词输入网络;
从网络解码器获取上下文的向量表示(源和先前的目标);
根据这个向量表示,预测下一个 token的概率分布

decoder 得到的向量通过一个线性层 再经过softmax函数转换成下一个token的概率。
简单模型:用两个RNNs构成的Encoder and Decoder
最简单的编码器-解码器模型由两个 RNN (LSTM) 组成:一个用于编码器,另一个用于解码器。 Encoder RNN读取源句,最终状态作为decoder RNN的初始状态。 希望是最终的编码器状态“编码”了关于源的所有信息,解码器可以根据这个向量生成目标句子。
这个模型可以有不同的修改:例如,编码器和解码器可以有几个层。 例如,在 Sequence to Sequence Learning with Neural Networks论文中使用了这种具有多层的模型 - 这是使用神经网络解决序列到序列任务的首次尝试之一。
在同一篇论文中,作者查看了最后一个编码器状态并可视化了几个示例 - 如下所示。 有趣的是,具有相似含义但结构不同的句子的表示很接近!
cross-entropy loss(交叉熵损失函数)
标准的损失函数为交叉熵损失函数,目标分布为p*, 预测分布为p

由于pi*不等于0,因此我们得到:

在每一步,我们最大化模型分配给正确标记的概率。 查看单个时间步长的插图。

For the whole example, the loss will be −∑t=1->n log(p(yt|y<t,x)). Look at the illustration of the training process (the illustration is for the RNN model, but the model can be different).

Attention 注意力
The Problem of Fixed Encoder Representation
在我们目前看到的模型中,编码器将整个源语句压缩成一个向量。 这很难——源的可能含义的数量是无限的。 当编码器被迫将所有信息放入单个向量(512)中时,它很可能会忘记一些东西。
不仅编码器很难将所有信息放入一个向量中——这对解码器来说也很困难。 解码器只能看到源的一种表示。 但是,在每个生成步骤中,源的不同部分可能比其他部分更有用。 但在目前的情况下,解码器必须从相同的固定表示中提取相关信息——这不是一件容易的事。
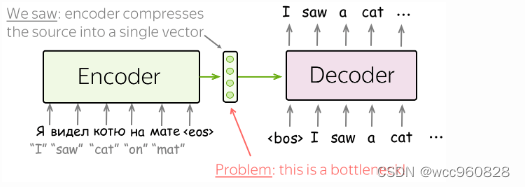
注意机制是神经网络的一部分。 在每个解码器步骤中,它决定哪些源部分更重要。 在此设置中,编码器不必将整个源压缩为单个向量 - 它为所有源标记提供表示(例如,所有 RNN 状态而不是最后一个)。

计算方案如下:

如何计算注意力分数:有以下几种方式


计算注意力分数最流行的方法是:
点积 - 最简单的方法;
双线性函数(又名“Luong attention”)——用于论文 Effective Approaches to Attention-based Neural Machine Translation;
多层感知器(又名“Bahdanau attention”)——原始论文中提出的方法。