Seq2Seq – Attention – Transformer
文章目录
1.前言
Transformer是谷歌在2017年的论文 Attention Is All You Need 中提出的一种模型,可以很好地处理序列相关的问题,如机器翻译。在此之前,对于机器翻译问题一般使用CNN或RNN作为encoder-decoder的模型基础,如使用RNN的Seq2Seq模型。
机器翻译一些模型的提出过程如下[3]:
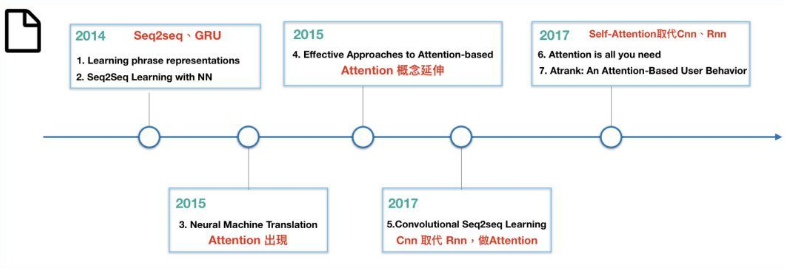
- RNN对于序列问题有很好的效果,最早是使用基于RNN的Seq2Seq模型处理机器翻译问题,但其序列循环使得在训练时非常缓慢
- Facebook将Seq2Seq的RNN替换成CNN,用多个CNN叠加放大上下文,刷新了两项翻译任务记录,并将训练速度大大提高
- Transformer基于Attention机制实现,没有使用CNN或RNN结构,可高度并行,训练快,准确率高
本文将通过对Seq2Seq模型、Attention模型的简单介绍,引入并重点介绍Transformer模型,加深自己对各个模型的理解。
2.Seq2Seq模型
Seq2Seq模型,Sequence-to-Sequence,即序列到序列的过程。
典型的Seq2Seq模型如下,包含编码器Encoder和解码器Decoder两个部分。

Encoder是一个RNN/LSTM模型,将输入的句子编码得到context vector,即
Decoder是Encoder的逆过程,每个状态由之前的状态和context vector决定,即
在这种模型下,所有输入被压缩在一个向量中,导致——
- 无法表达序列信息
- 当句子长度较大时,容易丢失信息
3.Attention模型
3.1简介
2015年提出的Attention模型,使用多个context vector,有效地解决了使用Seq2Seq模型难以处理长句子的问题。
注意力机制(Attention Mechanism)源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息的一部分,同时忽略其他可见的信息。上述机制通常被称为注意力机制。
在机器翻译中,注意力机制衡量输出单词与每个输入单词的关联程度,关联程度更大的输入单词具有更大的权重,使得输出单词可以更关注其对应的语义。比如,当翻译 I eat an apple 时,输出 吃 时应该重点关注 eat 这个单词,即eat的权重应该比其他单词更高。
3.2模型架构
最先的Attention模型[5]架构如下:

-
输入:待翻译的句子
-
Encoder:双向的RNN或LSTM,计算得到每个位置的隐状态,下面只用 表示
-
Decoder:对当前输出位置 ,使用上一个隐状态 与Encoder的结果计算,如下:
- 衡量输出位置 与输入位置 之间的匹配程度, 可以是点积或其他运算——
- 加权求和得到context vector——
- 使用上一个隐状态、上一个输出、context vector更新当前状态——
- 根据当前状态、上一个输出、context vector计算当前输出——
通过为每个输出位置计算一个context vector,使得每个位置的输出可以关注到输入中最相关的部分,效果比传统模型更好。
3.3其他
Attention模型提出后,出现了许多Attention模型的变体,包括——
- Soft Attention、Global Attention、动态 Attention
- 三者是同一种Attention,即上述结构,对输入的每个位置都计算对齐概率
- Hard Attention
- 同样对每个位置计算对齐概率,但只将最高的一个置为1,其余置为0
- local Attention
- 只计算一个窗口内的位置的对齐概率,减少计算量
另外,上述模型计算 时使用的是前一个状态 ,也有一些模型中直接使用当前状态 ,如下[4]:

计算过程为:
4.Transformer
4.1为什么使用Transformer?
RNN:其结构使得其天然适合处理NLP领域的问题,但最大的瓶颈是难以并行化,尽管有一些并行化思路,但仍然只能并行很小一部分。
CNN:卷积核抽取类似n-gram的特征,但难以处理长距离依赖问题,且pooling层会丢失位置信息。通过将CNN层数加深可以提高其处理长距离依赖问题的能力,同时去除pooling层保留位置信息,使得CNN可以更适合处理NLP问题。在并行能力上,CNN各个卷积核之间没有依赖,非常适合并行,因此速度比RNN快得多。
摘录来自[6]中的关于RNN、CNN、Transformer的对比。(此处的RNN和CNN指在RNN和CNN基础上增加Attention机制等改进版)
- 语义特征提取能力:RNN与CNN能力相近,而Transformer要超过两者4-8个百分点
- 长距离特征捕获能力:RNN与Transformer能力相近,CNN则弱得多(尽管已经加深了层数)
- 任务综合特征抽取能力:Transformer 显著强于 RNN 和 CNN,CNN略强于RNN
- 并行计算能力及运行效率:Transformer 和 CNN 差不多,都远远远远强于 RNN
从上面的对比可以看出,Transformer在效果和速度上都具有很好的表现。
4.2模型架构
Transformer模型架构如下[1]:

Encoders由N个Encoder组成,Decoders由N个Decoder组成,图示为 。每个Encoder和Decoder内部简化结构如下:

在了解其内部具体流程之前,先了解下论文中提出的一些概念。
4.2.1 Self-Attention
Attention的目的是要算出一个context vector,原始的Attention模型使用①输出当前位置的隐状态与②输入所有位置的隐状态计算匹配程度,并根据匹配程度对③输入所有位置的隐状态进行加权求和得到context vector。
在Self-Attention中,输入输出都是句子本身,对原始Attention做一个转化——
- 把当前位置看成输出,其映射后的隐状态记为query(上面的①)
- 把当前位置看成输入,其映射后的隐状态记为key(上面的②)
- 把当前位置看成输入,其用于加权求和的隐状态记为value(上面的③)
在NLP的领域中,Key, Value通常就是指向同一个文字隐向量[7],即key=value。
有了上述理解,Self-Attention的过程也就跟原始的Attention模型基本相同,如下[2]:

-
Self-Attention对每个输入(句子)的embedding,计算得到3个向量,分别为query ,key ,value
-
对第 个单词,使用query与所有单词的key点乘计算匹配得分,并除以上述向量维度的平方根 (也就是论文中提出的
scaled dot-Product attention),使得点积结果不会过大,训练过程梯度更稳定
-
对分数进行softmax得到权重,并对value加权求和得到当前单词的向量映射
实际应用时直接使用矩阵进行运算,即
4.2.2 Multi-headed Attention
论文中使用Multi-headed机制进一步完善了Self-Attention层,具体地,对输入的 进行多次不同的映射,相当于把句子投影到不同的子空间(representation subspaces) 中,提高其表达能力。其结构如下[2]:

其工作流程如下[1]:

- 对输入的句子的embedding,映射为 矩阵,即相当于对 做多次不同映射
- 按照self-Attention分别计算得到 ,并使用concat连接结果得到
- 为了使结果与self-Attention的shape一致,再乘上 将其映射为想要的shape
4.2.3 位置编码
上述Attention过程没有考虑到输入序列中单词的顺序,transformer为每个输入单词的词嵌入上添加了一个新向量——位置向量,即embedding_with_time_signal = positional_encoding + embedding。位置向量遵循一定规则生成,此处不涉及。
此外,上述结构的每一层后都要增加一个layer-normalization步骤,如下:

综合上述的各个模块,一个完整的Transformer结构大致如下[1]:

4.3训练过程
了解上述各概念后,梳理一下Transformer的整个训练过程如下:
4.3.1 输入
输入是句子的embedding表示,加上位置向量后输入到第一个Encoder里
4.3.2 Encoders
Encoders包含N个结构相同的Encoder,每个Encoder包含一个Multi-headed Attention层和一个前馈层,包含以下几个步骤:
- Multi-headed Attention,Layer normalization
- Feed forward,Layer normalization
每层的输出和输入具有相同的shape
4.3.3 Decoders
Decoders包含N个结构相同的Decoder,每个Decoder包含一个Multi-headed Attention层、一个Encoder-Decoder Attention层、一个前馈层,训练时是逐个词生成的,即一个句子Decoders要执行多次,包含以下几个步骤:
- 输入是上一个生成的词,初始化为??(之后看代码实现)
- 对输入的单词做Multi-headed Attention,Layer normalization
- 做Encoder-Decoder Attention,与上一步的区别在于query是输入的词,但key和value来自Encoders最后一层的输出
- Feed forward,Layer normalization
- 对输出做线性映射,用softmax生成最可能的词,作为下一轮的输入,直到输出一个特殊的符号
<end of sentence>