seq2seq顾名思义是指由序列生成序列,广泛用于机器翻译领域,其结构是由RNN组成一组编码器和一组解码器。
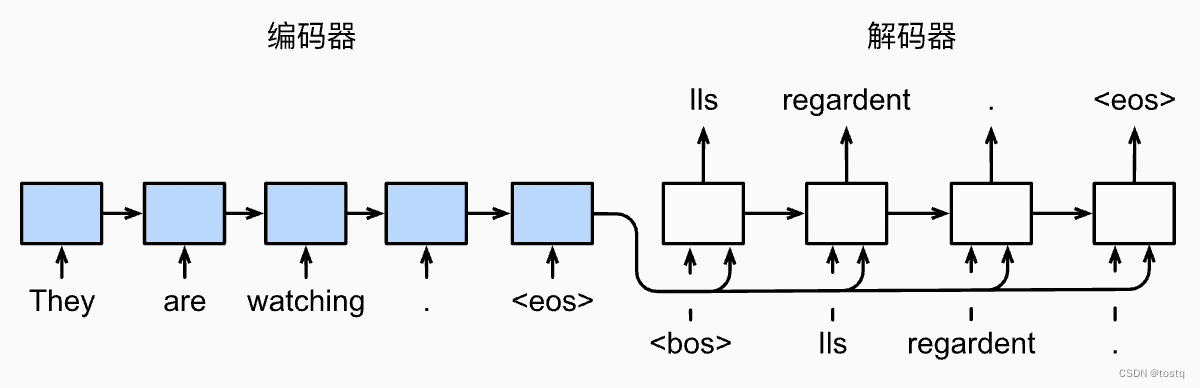
上图中的蓝色模块为编码器,其由一个embedding模块实现词到词向量的变换,再加一个GRU多层循环模块生成隐层向量,其结构如下,其是一个双层的GRU循环网络,其输入为单词的one-hot向量,在将全部的单词输入编码器后,将encoder的最终隐层向量输出给decoder模块。
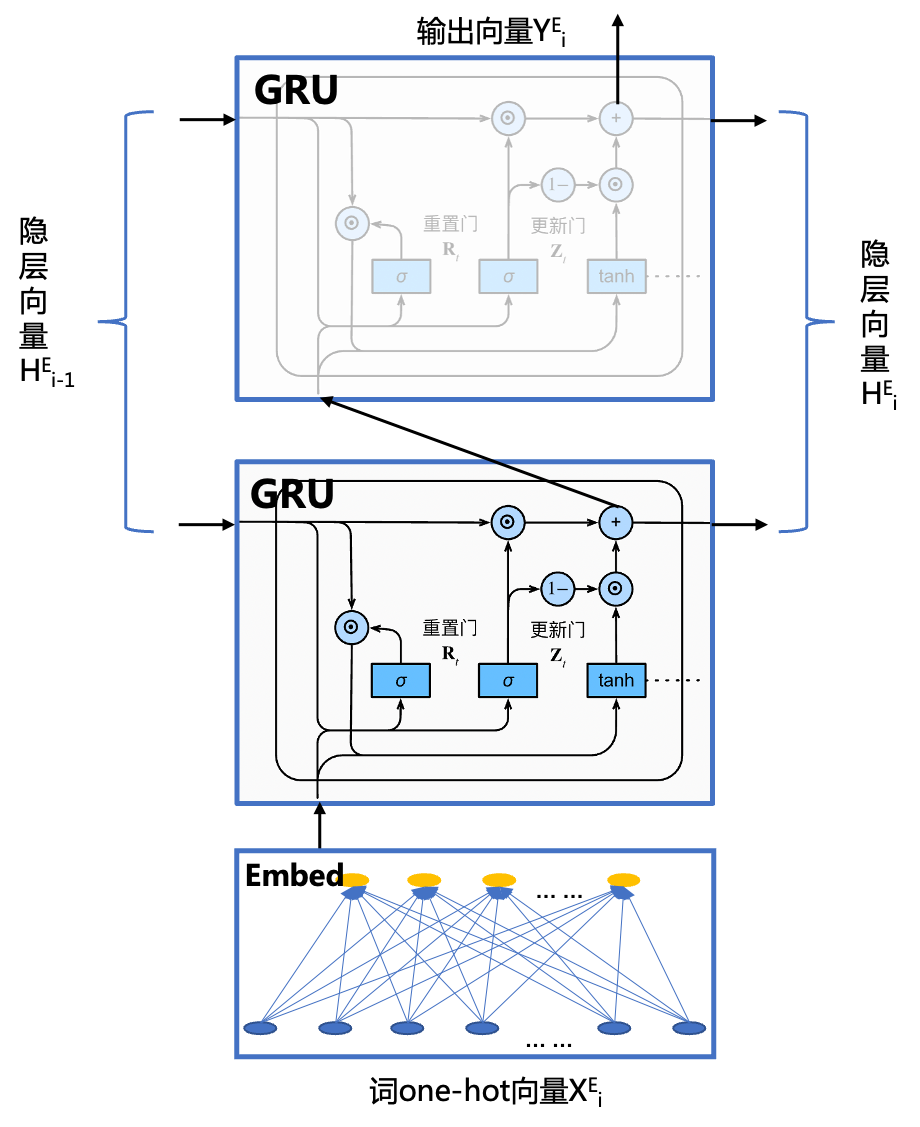
encoder的网络结构由如下paddle代码可以描述:
#@save
class Seq2SeqEncoder(nn.Layer):
"""用于序列到序列学习的循环神经网络编码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
weight_ih_attr = paddle.ParamAttr(initializer=nn.initializer.XavierUniform())
weight_hh_attr = paddle.ParamAttr(initializer=nn.initializer.XavierUniform())
# 嵌入层
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size,
num_hiddens,
num_layers,
direction="forward", # foward指从序列开始到序列结束的单向GRU网络方向,bidirectional指从序列开始到序列结束,又从序列结束到开始的双向GRU网络方向
dropout=dropout,
time_major=True, # time_major为True,则Tensor的形状为[time_steps,batch_size,input_size],否则为[batch_size,time_steps,input_size]
weight_ih_attr=weight_ih_attr,
weight_hh_attr=weight_hh_attr)
def forward(self, X, *args):
# 输出'X'的形状:(batch_size, num_steps, embed_size)
X = self.embedding(X)
# 在循环神经网络模型中,第一个轴对应于时间步
X = X.transpose([1, 0, 2])
# 如果未提及状态,则默认为0
output, state = self.rnn(X)
# PaddlePaddle的GRU层output的形状:(batch_size, time_steps, num_directions * num_hiddens),
# 需设定time_major=True,指定input的第一个维度为time_steps
# state[0]的形状:(num_layers,batch_size,num_hiddens)
return output, state解码器也是由双层的GRU循环神经网络作为主要组成部分,不过其除了输入还有一个embeding模块外,在输出还有一个线性模块将词向量还原one-hot形式,其结构如下图所示,其中初始情况下,解码器的隐层向量设置为编码器最终的输出隐层向量,解码器的输入为编码器的输出向量同上轮解码器的预估输出cocat形成的向量。
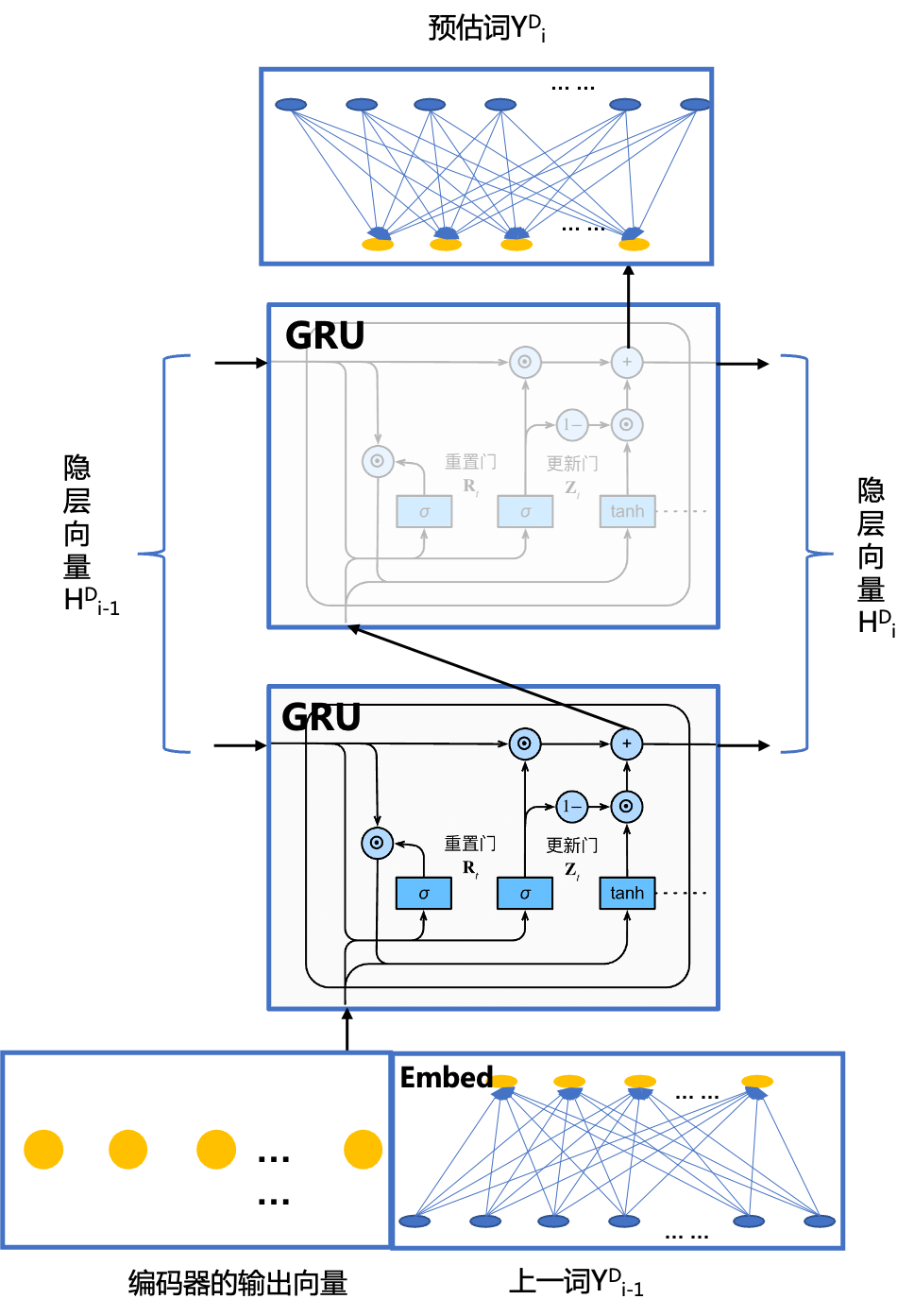
decoder的网络结构由如下paddle代码可以描述:
class Seq2SeqDecoder(nn.Layer):
"""用于序列到序列学习的循环神经网络解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
weight_attr = paddle.ParamAttr(initializer=nn.initializer.XavierUniform())
weight_ih_attr = paddle.ParamAttr(initializer=nn.initializer.XavierUniform())
weight_hh_attr = paddle.ParamAttr(initializer=nn.initializer.XavierUniform())
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout,
time_major=True, weight_ih_attr=weight_ih_attr,weight_hh_attr=weight_hh_attr)
self.dense = nn.Linear(num_hiddens, vocab_size, weight_attr=weight_attr)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, X, state):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X).transpose([1, 0, 2]) # shape: (num_steps,batch_size,embed_size)
# 广播context,使其具有与X相同的num_steps
context = state[-1].tile([X.shape[0], 1, 1])
X_and_context = paddle.concat((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).transpose([1, 0, 2])
# output的形状:(batch_size,num_steps,vocab_size)
# state[0]的形状:(num_layers,batch_size,num_hiddens)
return output, state最终的组成形成seq2seq模型的代码为:
#@save
class EncoderDecoder(nn.Layer):
"""编码器-解码器架构的基类"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)另一个重要问题是seq2seq模型的损失函数。机器翻译的损失函数类似于分类,可以用交叉熵损失函数表示,不过通过mask来剔除同批次下补余的部分,具体损失函数代码如下:
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
"""带遮蔽的softmax交叉熵损失函数"""
def sequence_mask(self, X, valid_len, value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.shape[1]
mask = paddle.arange((maxlen), dtype=paddle.float32)[None, :] < valid_len[:, None]
Xtype = X.dtype
X = X.astype(paddle.float32)
X[~mask] = float(value)
return X.astype(Xtype)
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self, pred, state, label, valid_len):
weights = paddle.ones_like(label)
weights = self.sequence_mask(weights, valid_len)
self.reduction='none'
unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(
pred, label)
weighted_loss = (unweighted_loss * weights).mean(axis=1)
return weighted_loss