视频流采样之实时车牌识别
前言
各位从事安防的童鞋可能都或多或少的涉及到人脸识别、车牌识别、视频结构化等应用,但是这些应用都是基于硬件实现的,比如本文将要提及的车牌识别算法一般都是硬件厂家集成到摄像机中算法,通过对接设备接口来实现车牌的识别,或者说通过厂家的智能分析平台集成的算法来实现人脸和车牌的识别。但是如果是通过摄像机或者厂家平台实现人或车牌的算法存在如下问题:
(1)购买单摄像机成本较高且不能覆盖所有位置,而不同位置都需要专业摄像机,数量庞大
(2)不同厂家的专业摄像机接口不一,开发接入成本较高
(3)厂家算法又不单独对外提供,只能集成到厂家硬件或平台中自己使用,无法做后期其他类型的自定制的应用(如后期图片识别与处理)
所以,针对以上问题,我们如何打破束缚,开发出识别效率高、成本低的应用就是接下来我要解决的问题。
提示:以下是本篇文章正文内容,下面案例可供参考
一、介绍
针对以上问题,为了降低成本而又能独立定制自己的应用,最好的解决办法是直接使用算法,我们有如下解决方案
(1)购买百度、阿里等在线算法,按n元/次进行收费(缺点是必须在线联网且持续性收费)
(2)使用第三方厂家提供的带序列号的离线算法sdk
(3)使用开源TensorFlow自训练ocr识别模型集成或其他开源库来实现
以上3中方案中
第一种:涉及到网络问题,针对很多政府项目或无互联网的项目可能是行不通的;
第二种:使用离线sdk的方式是,算法是按照机器指纹或按加密狗进行收费的,资源不足或数据量较大的情况下集群多机部署可能购买成本也较高。
第三种:也是我希望能长期免费且高效使用的一种方式,这种方式虽然后,但是难点在于要找到一个开源的、稳定的、识别率很高的、识别速度很快的就是一个很大的障碍!
二、paddle引入
在百度飞桨开源之前,我找到很多的开源库,包括TensorFlow自学习、easyLPR等等,不是编译难度非常大、学习训练难度大就是识别速度慢、识别精度不高等问题,每次调研每次都放弃了。
由于项目需要,这次又开始了新的调研,不过网络经过几年的技术革新和迭代,也有很多新的开源项目出现,包括口碑较好的EasyLPR的更新版本识别,我也同样做了测试,得出一下结论
- 识别精度还是不高(一般在80-85%上下浮动),部分车牌不识别
- 对中文识别支持较好,但是英文车牌就很差了,甚至不识别(港牌)
- 识别速度不快,有的可能要1秒或几秒(图片稍大情况)
基于以上情况,我有放弃了它!最终经过多轮搜索和比对找到了飞桨!飞桨不是一个车牌识别库,而是一个适用于任何场景的的模型算法训练使用平台,其自身就集成了很多内置算法模型,包括ocr识别、语音算法、语言翻译等等,这些内置的算法的精度已经是很高很高了,可以和行业顶级算法媲美!
所以后续的车牌识别就是以百度飞桨平台为基础,将飞桨的算法通过自写网络api接口的方式暴露给自己的应用程序进行开发,实现应用与算法的解耦!
三、车牌识别
针对车牌识别应用,我的实现思路和流程如下

其实整个流程就是:
- 管理员动态添加普通摄像机(非车牌识别专业摄像机)到媒体接入服务
- 媒体接入服务通过rtsp协议从摄像机获取到视频流并通过抽帧采样的方式抓取到图片(采样可以是25帧抽1帧或2帧甚至配置为n秒抓取一张图)
- 媒体服务将采样抽取的图片帧通过python的restful api接口上传到百度飞桨平台平台进行识别,并返回结果
- 如果返回的识别结构有车牌且与上一次车牌比较,如果是新车牌则自动上传推送到应用平台
- 应用平台可以通过自己的策略进行定制的业务逻辑处理(如黑名单比对、计费缴费结算、远程抬杠<接入01网络控制器即可>或者将识别结果通过websocket推送到web前端展示)
这里面的核心技术要点是
- 媒体接入服务接入rtsp通信视频流并持续采样抽帧
- 百度非飞桨平台的搭建和部署,并通过编写python脚本对外提供OCR识别服务
- python脚本提供车牌的颜色识别服务并结合ocr识别服务形成车牌识别服务
以上的几个要点这都已经得到解决
-
媒体接入定时采样存储图片到本地
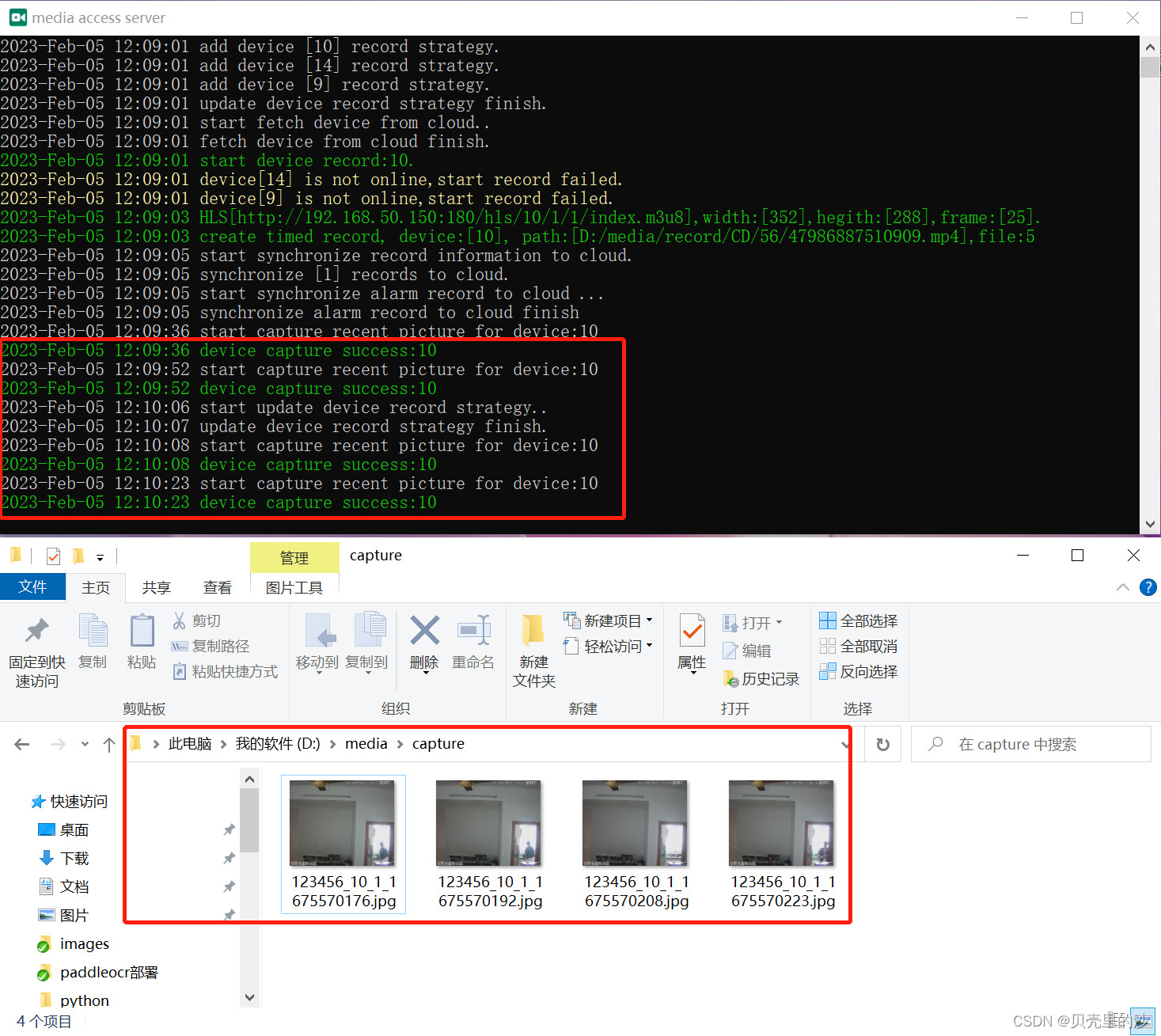
-
百度OCR识别并提供网络接口

访问python的测试demon,测试demon调用车牌识别接口

测试调用返回识别结果
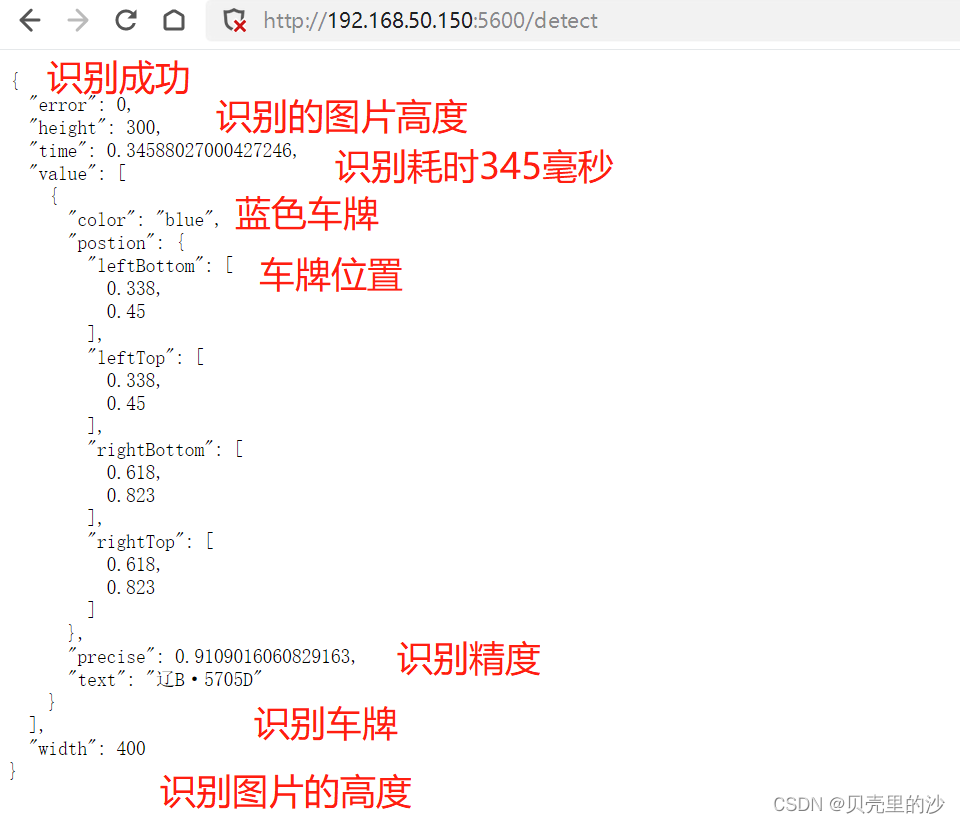
测试其他的图片
识别结果
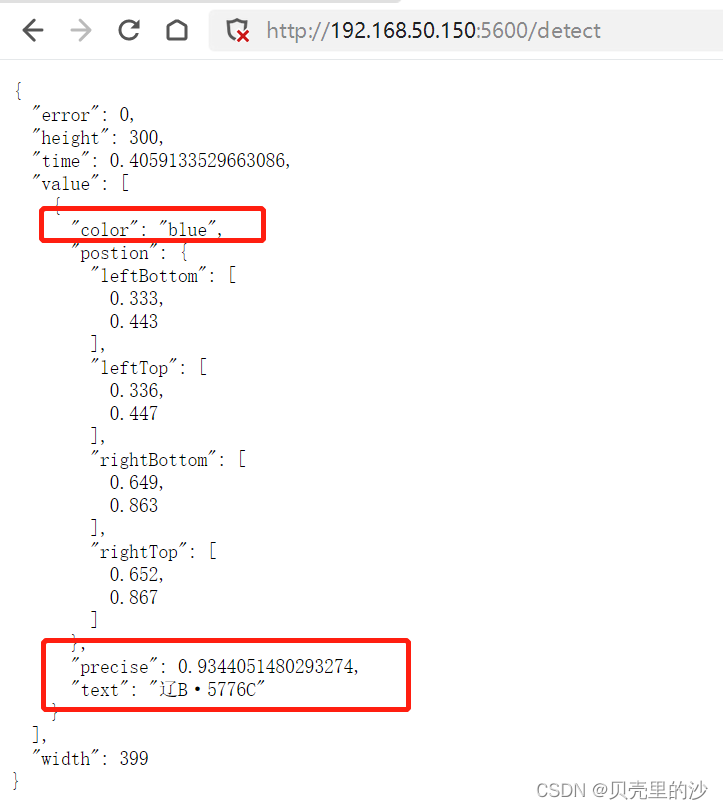
港牌识别结果

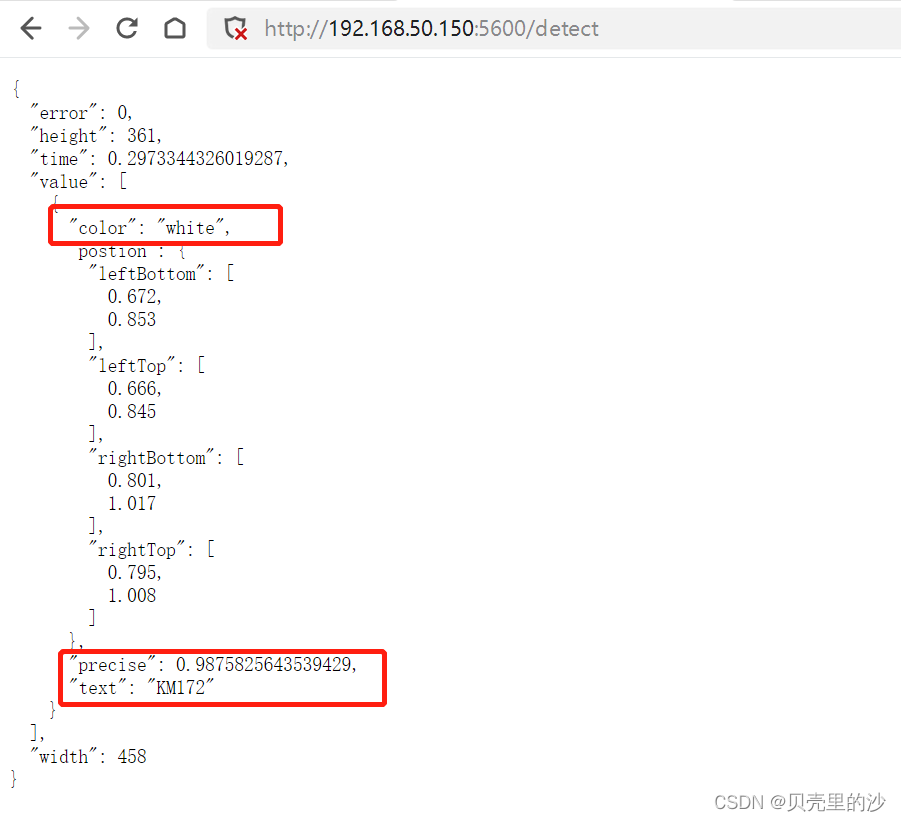
英文港牌车牌识别更高!
- 颜色识别
飞桨只能识别到文字,但是需要集成车牌的识别,所以需要自己额外做颜色识别,这里可以使用opencv来处理
#图片中目标区域颜色的识别
def get_color(frame):
print('识别图片选区颜色')
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
color_dict = getColorList()
#count = 0
maxsum = 0
color = None
#遍历所有颜色匹配red|red2|orange|purple|blue|cyan|white|green
for d in color_dict:
#在后两个参数范围内的值变成255
mask = cv2.inRange(hsv, color_dict[d][0], color_dict[d][1])
#在灰度图片中,像素值大于127的都变成255,[1]表示调用图像,也就是该函数第二个返回值
binary = cv2.threshold(mask, 127, 255, cv2.THRESH_BINARY)[1]
# cv2.imshow("0",binary)
# cv2.waitKey(0)
# count+=1
#使用默认内核进行膨胀操作,操作两次,使缝隙变小,图像更连续
binary = cv2.dilate(binary, None, iterations=2)
#获取该函数倒数第二个返回值轮廓
cnts = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[-2]
#获取该颜色所有轮廓围成的面积的和
sum = 0
for c in cnts:
sum += cv2.contourArea(c)
if sum > maxsum:
maxsum = sum
color = d
if color == 'red2':
color = 'red'
elif color == 'orange':
color = 'yellow'
return color
各位网友如有合作可以联系vx lixiang6153或秋秋941415509
四、完整代码
这里贡献出python端的完整代码,实现了如下功能
- orc文字识别
- 车牌颜色识别
- 图片上传接口提供
具体代码如下所示
import os
import time
import cv2
import collections
from flask import Flask, request, send_from_directory
from werkzeug.utils import secure_filename
from paddleocr import PaddleOCR, draw_ocr
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
#监听地址端口
host = '0.0.0.0'
port = 5600
#上传文件大小限制
app = Flask(__name__)
app.config['MAX_CONTENT_LENGTH'] = 16 * 1024 * 1024
#关闭ascii编码方式-返回中文
app.config['JSON_AS_ASCII'] = False
#允许上传的文件类型和存储位置
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg'])
UPLOAD_FOLDER = './files/'
#文件类型检查函数
def allowed_file(filename):
return '.' in filename and \
filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS
#创建ocr实例
ocr = PaddleOCR(lang="ch")
#获取要识别的颜色列表
import numpy as np
import collections
# 将rgb图像转换为hsv图像后,确定不同颜色的取值范围
def getColorList():
dict = collections.defaultdict(list)
#black
lower_black = np.array([0, 0, 0])
upper_black = np.array([180, 255, 46])
color_list_black = []
color_list_black.append(lower_black)
color_list_black.append(upper_black)
dict['black'] = color_list_black
#white
lower_white = np.array([0, 0, 221])
upper_white = np.array([180, 30, 255])
color_list_white = []
color_list_white.append(lower_white)
color_list_white.append(upper_white)
dict['white'] = color_list_white
#yellow
lower_orange = np.array([11, 43, 46])
upper_orange = np.array([34, 255, 255])
color_list_orange = []
color_list_orange.append(lower_orange)
color_list_orange.append(upper_orange)
dict['yellow'] = color_list_orange
#green
lower_green = np.array([35, 43, 46])
upper_green = np.array([77, 255, 255])
color_list_green = []
color_list_green.append(lower_green)
color_list_green.append(upper_green)
dict['green'] = color_list_green
#blue
lower_blue = np.array([100, 43, 46])
upper_blue = np.array([124, 255, 255])
color_list_blue = []
color_list_blue.append(lower_blue)
color_list_blue.append(upper_blue)
dict['blue'] = color_list_blue
return dict
#图片中目标区域颜色的识别
def get_color(frame):
print('识别图片选区颜色')
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
color_dict = getColorList()
#count = 0
maxsum = 0
color = None
#遍历所有颜色匹配red|red2|orange|purple|blue|cyan|white|green
for d in color_dict:
#在后两个参数范围内的值变成255
mask = cv2.inRange(hsv, color_dict[d][0], color_dict[d][1])
#在灰度图片中,像素值大于127的都变成255,[1]表示调用图像,也就是该函数第二个返回值
binary = cv2.threshold(mask, 127, 255, cv2.THRESH_BINARY)[1]
# cv2.imshow("0",binary)
# cv2.waitKey(0)
# count+=1
#使用默认内核进行膨胀操作,操作两次,使缝隙变小,图像更连续
binary = cv2.dilate(binary, None, iterations=2)
#获取该函数倒数第二个返回值轮廓
cnts = cv2.findContours(binary, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[-2]
#获取该颜色所有轮廓围成的面积的和
sum = 0
for c in cnts:
sum += cv2.contourArea(c)
if sum > maxsum:
maxsum = sum
color = d
if color == 'red2':
color = 'red'
elif color == 'orange':
color = 'yellow'
return color
#转百分比,保留3位小数
def to_percent(pos, img):
return [round(pos[0] / img[0], 3),round(pos[0] / img[1], 3)]
#文件上次处理方法
@app.route('/detect', methods=['POST', 'GET'])
def do_upload():
#post上传
if request.method == 'POST':
#获取上传文件
file = request.files['file']
#被允许上传文件类型
if file and allowed_file(file.filename):
#开始计算时间
old_time=time.time()
#获取实际文件名
filename = secure_filename(file.filename)
#获取保存图片路径
img_path = os.path.join(UPLOAD_FOLDER, filename)
#保存到设定目录中
file.save(img_path)
#识别图片
result = ocr.ocr(img_path)
if len(result) <= 0:
return {
'error':-1, 'description':'图片中未识别到文字'}
#opencv识别颜色
frame = cv2.imread(img_path)
size = [frame.shape[1],frame.shape[0]]
#获取识别结果列表
list = []
for item in result[0]:
#识别选区颜色:[y:y+h, x:x+w]
rect = frame[int(item[0][0][1]):int(item[0][3][1]), int(item[0][0][0]):int(item[0][1][0])]
color = get_color(rect)
json = {
'text':item[1][0],
'color': color,
'precise': item[1][1],
'postion': {
'leftTop': to_percent(item[0][0],size),
'rightTop': to_percent(item[0][1],size),
'rightBottom': to_percent(item[0][2],size),
'leftBottom': to_percent(item[0][3],size)
}
}
list.append(json)
#计算耗时时间
take_time = time.time()-old_time;
#返回成功
return {
'error':0,
'time': take_time,
'width': size[0],
'height': size[1],
'value': list
}
return {
'error':-1, 'description':'不支持的文件类型'}
#get请求获取上传网页
return '''
<!doctype html>
<title>车牌识别</title>
<h1>车牌识别</h1>
<form action="" method=post enctype=multipart/form-data>
<p>
选择车牌图片:<input type=file name=file>
<input type=submit value=开始识别>
</p>
</form>
'''
#下载指定文件
@app.route('/download/<filename>')
def uploaded_file(filename):
return send_from_directory(UPLOAD_FOLDER,filename)
#启用应用程序
if __name__ == '__main__':
app.run(host = host, port = port, debug = True)
以上流程都是可操作且成熟已实现的,如有问题或需要合作,各位可与我取得联系!