用Python中的马尔科夫链进行营销渠道归因 --第一部分:"更简单 "的方法
任何积极开展营销活动的企业都应该对确定哪些营销渠道推动了实际转化率感兴趣。投资回报率(ROI)是一个关键的KPI,这已经不是什么秘密。
在这篇文章中,我们将介绍。
为什么渠道归因很重要? 3种标准归因模型 一个先进的归因模型。马尔科夫链 如何在Python中建立这4种归因模型 本文中的马尔科夫链方法将通过利用R包ChannelAttribution采取一种 "简单 "的方法。关于这个解决方案的完整python实现,请参见本系列的第二部分。
为什么归因很重要? 由于企业可以向客户进行营销的平台越来越多,而且大多数客户都在多个渠道上与你的内容接触,现在决定如何将转换归因于渠道比以往任何时候都更重要。2017年的一项研究表明,92%的消费者第一次访问零售商的网站并不是为了购买(链接)。
为了说明归因的重要性,让我们考虑一个导致转换的用户旅程的简单例子。在这个例子中,我们的用户名叫约翰。

第一天。
约翰对你的产品的认识是由一个YouTube广告引发的,随后访问你的网站,浏览你的产品目录。
经过一段时间的浏览,约翰对你的产品的认识被激发出来,然而他并没有完成购买的打算。
第二天。
第二天,当约翰在他的Facebook上滚动浏览时,他收到了另一个关于你的产品的广告,这促使他回到你的网站,这次约翰完成了购买过程。
在这种情况下,当你想通过营销渠道来计算你的投资回报率时,你将如何把约翰产生的美元归于营销渠道?
传统上,渠道归因是由一些简单而强大的方法来解决的,比如First Touch、Last Touch和Linear。
标准归因模型
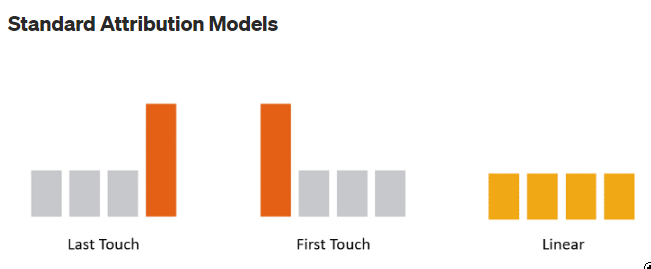
3种标准归因模型
最后接触归因
顾名思义,Last Touch是一种归因方法,任何产生的收入都归于用户最后参与的营销渠道。
虽然这种方法的优点是简单,但你也有过度简化归因的风险,因为最后接触不一定是产生购买的营销活动。
在上面John的例子中,最后接触的渠道(Facebook)可能没有创造100%的购买意向。意识来自于观看YouTube广告的最初火花。
第一次接触归因
购买所产生的收入归属于用户在购买过程中接触到的第一个营销渠道。
就像 "最后一次接触 "方法一样,"第一次接触 "归因有其简单的优势,但你也有可能将你的归因方法过度简化。
线性归因
在这种方法中,归因被平均分配给用户在导致购买的旅程中接触到的所有营销渠道。
这种方法更适合捕捉我们在消费者行为中看到的多渠道接触行为的趋势。然而,它没有区分不同的渠道,而且由于不是所有的消费者与营销工作的接触都是平等的,这是这个模型的一个明显的缺点。
其他值得一提的标准归因方法是时间衰减归因和基于位置的归因。
一个先进的归因模型-马尔科夫链
有了上述3种标准的归因方法,我们就有了容易实施的模型来确定我们的营销渠道的投资回报率。
然而,这3种方法的注意事项是,它们过于简化了。这可能会导致人们对营销渠道所推动的结果过于自信。这种疏忽可能是有害的--误导了未来的商业/营销决策。
为了克服这种疏忽,我们可以考虑采用一种更先进的方法-马尔科夫链。
如果你上过统计学课程,你可能会接触到这个理论。马尔科夫链是以俄罗斯数学家安德烈-马尔科夫的名字命名的,它描述了一个可能事件的序列,其中每个事件的概率只取决于前一个事件所达到的状态。
马尔科夫链,在渠道归因的背景下,给我们提供了一个框架来模拟用户旅程,以及每个渠道如何影响用户从一个渠道到另一个渠道最终购买(或不购买)的因素。
在这篇文章中,我们不会对马尔科夫链理论进行太深入的研究。(如果你有兴趣了解更多幕后的数学/统计学,Setosa.io有一篇很好的阅读。)
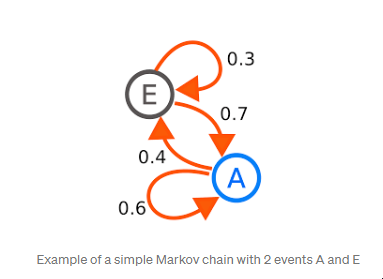
有2个事件A和E的简单马尔可夫链的例子 马尔可夫链的核心概念是,我们可以使用生成的数据来确定在我们的潜在营销渠道事件和转换事件网络中从一个事件到另一个事件的概率。
在下一节,我们将通过Python代码来实现这些归因框架中的任何一个。
如何在Python中构建4种归因模型 如果你想跟着学,我们在这个例子中使用的数据集可以在这里下载。
本文中的马尔科夫链模型是用R语言中的ChannelAttribution包建立的,完整的Python实现见第二部分。
我们的数据集的结构是以参与活动为列,行是参与的渠道,按时间顺序排列。在这种情况下,每个营销渠道都被分配了一个固定的编号,如果某个用户的第n次参与是在该营销渠道进行的,就会显示在第n列。渠道21是一个转换,我们的数据集只包含转换的用户旅程的记录。
我们的数据集的样本 我们要做的第一件事是导入必要的库
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import subprocess
接下来,让我们加载我们的数据集并清理数据点
装入我们的数据
df = pd.read_csv('Channel_attribution.csv')
抓取要迭代的列的列表
cols = df.columns
遍历各列,将所有整数改为str,并删除任何尾部的'.0'。
for col in cols:
df[col] = df[col].astype(str)
df[col] = df[col].map(lambda x: str(x)[:-2] if '. ' in x else str(x))
马尔科夫链框架希望用户的旅程在一个单一的变量中,并以通道1>通道2>通道3>......的形式出现,所以下一个循环完全是这样创建的
创建一个总的路径变量
df['Path'] = ''
for i in df.index:
#df.at[i, 'Path'] = 'Start'
for x in cols:
df.at[i, 'Path'] = df.at[i, 'Path'] + df.at[i, x] + ' > '
由于我们的数据集中的通道21是一个转换事件,我们将把该通道从路径中分离出来,并创建一个单独的转换变量,保存发生的转换数量(在我们的用户旅程级别的数据中仍然只有1)。
在转换过程中分割路径(通道21)
df['Path'] = df['Path'].map(lambda x: x.split(' > 21') [0])
创建转换值,我们可以将其相加,得到每个路径的总转换量
df['转换'] = 1
我们现在几乎完成了最初的数据处理工作。我们的数据仍然包含所有的原始列,所以我们抓取了我们需要前进的列的子集。由于一些用户可能采取了相同的旅程,我们将按照独特的用户旅程来分组我们的数据,我们的转换变量将保存每个相应旅程的转换数量。
# 选择相关的列
# Select relevant columns
df = df[['Path', 'Conversion']]
# 按路径计算转换量的总和
# Sum conversions by Path
df = df.groupby('Path').sum().reset_index()
# 将DF写入CSV,以便在R中执行
# Write DF to CSV to be executed in R
df.to_csv('Paths.csv', index=False)
上面这段代码的最后一行将把我们的数据输出到一个CSV文件中,现在我们已经完成了数据操作。为了透明起见,拥有这些数据可能很方便,在我们的案例中,我们也将使用这个CSV文件来运行马尔科夫链的归因方法。
有几种方法可以做到这一点。由于Python目前还没有为此建立一个库,一种方法是自己在Python中建立实际的马尔科夫链/网络。虽然这可以让你对你的模型有一个完整的概览,但这也是最耗费时间的方法。为了更有效率,我们将利用ChannelAttribution R库,它将马尔科夫链背后的理论集中在一个应用程序中。
我们将使用标准的Python库子进程来运行下面这段R代码,为我们计算我们的马尔科夫网络。
读入必要的库
if(!require(ChannelAttribution)){
install.packages("ChannelAttribution")
library(ChannelAttribution)
}
设置工作目录
setwd <- setwd('C:/Users/Morten/PycharmProjects/Markov Chain Attribution Modeling')
读入由python脚本输出的CSV文件
df <- read.csv('Paths.csv')
只选择必要的列
df <- df[c(1,2)]
。
运行马尔科夫模型函数
M <- markov_model(df, 'Path', var_value = 'Conversion', var_conv = 'Conversion', sep = '>', order=1, out_more = TRUE)
将模型的输出作为一个csv文件输出,以便读回Python中
write.csv(M$result, file = "Markov - Output - Conversion values.csv", row.names=FALSE)
为了可视化的目的,也要输出转换矩阵
write.csv(M$transition_matrix, file = "Markov - Output - Transition matrix.csv", row.names=FALSE)
下一段Python代码将执行我们的R脚本,并载入生成的CSV文件。
定义运行马尔科夫模型的R脚本的路径
path2script = 'C:/Users/Morten/PycharmProjects/Markov Chain Attribution Modeling/Markov.r'
调用R脚本
subprocess.call(['Rscript', '--vanilla', path2script], shell=True)
将CSV文件与R的模型输出一起加载进来
markov = pd.read_csv('Markov - Output.csv')
只选择必要的列并重命名它们
markov = markov[['channel_name', 'total_conversion']]
markov.columns = ['Channel', 'Conversion']
如果你想绕过必须创建一个单独的R脚本来运行Markov计算,那么你可以使用的Python库是rpy2。rpy2允许你导入R库并在Python中直接调用它们。然而,这种方法在我的过程中证明不是很稳定,因此我选择了单独的R脚本方法。
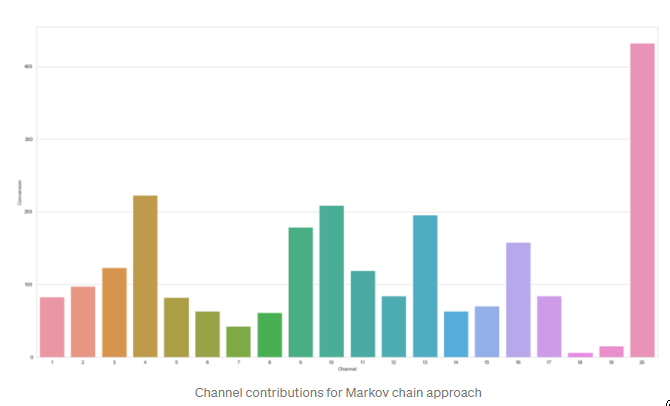
使用马尔科夫链的通道归属可以在下图中看到。这个图表应该告诉你,渠道20推动了很大一部分转化率,而渠道18和19的总转化值归属很低。
马尔科夫链方法的渠道贡献 虽然这个输出可能是你正在寻找的,但围绕着传统方法的输出与我们的马尔科夫链方法相比有很大的价值。
为了计算 "最后接触"、"第一次接触 "和 "线性 "的属性,我们运行以下代码
第一次触摸的归因
df['First Touch'] = df['Path'].map(lambda x: x.split(' > ')[0])
df_ft = pd.DataFrame()
df_ft['Channel'] = df['First Touch']
df_ft['Attribution'] = 'First Touch'
df_ft['Conversion'] = 1
df_ft = df_ft.groupby(['Channel', 'Attribution']).sum().reset_index()
Last Touch Attribution
df['Last Touch'] = df['Path'].map(lambda x: x.split(' > ')[-1])
df_lt = pd.DataFrame()
df_lt['Channel'] = df['Last Touch']
df_lt['Attribution'] = 'Last Touch'
df_lt['Conversion'] = 1
df_lt = df_lt.groupby(['Channel', 'Attribution']).sum().reset_index()
线性归属
channel = []
conversion = []
for i in df.index:
for j in df.at[i, 'Path'].split(' > '):
channel.append(j)
conversion.append(1/len(df.at[i, 'Path'].split(' > ')))
lin_att_df = pd.DataFrame()
lin_att_df['Channel'] = channel
lin_att_df['Attribution'] = 'Linear'
lin_att_df['Conversion'] = conversion
lin_att_df = lin_att_df.groupby(['Channel', 'Attribution']).sum().reset_index()
让我们把所有4种方法合并在一起,评估输出的差异。
将四个数据框合并为一个数据框
df_total_attr = pd.concat([df_ft, df_lt, lin_att_df, markov])
df_total_attr['Channel'] = df_total_attr['Channel'].astype(int)
df_total_attr.sort_values(by='Channel', ascending=True, inplace=True)
将属性可视化
sns.set_style("whiteegrid")
plt.rc('legend', fontsize=15)
fig, ax = plt.subplots(figsize=(16, 10))
sns.barplot(x='Channel', y='Conversion', hue='Attribution', data=df_total_attr)
plt.show()
渠道对所有归因方法的贡献
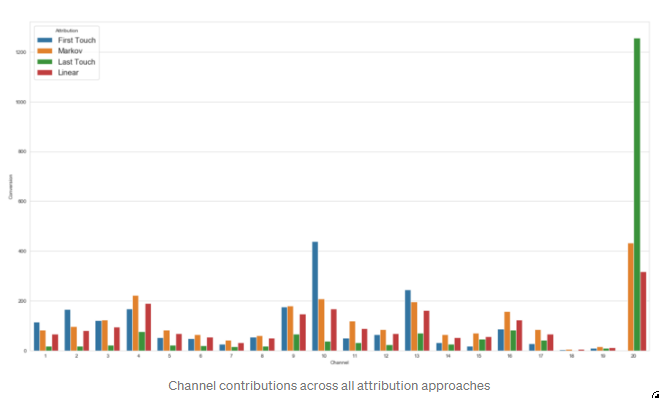
通过观察上图,我们可以很快得出结论:大多数用户的旅程从渠道10开始,以渠道20结束,而没有用户的旅程从渠道20开始。
为了了解不同的渠道是如何影响潜在的用户旅程的,我们可以看一下总的过渡矩阵,它可以用热图来表示
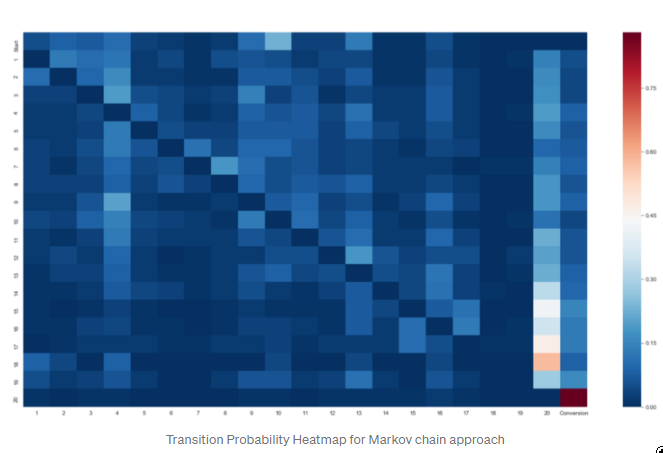
马尔科夫链方法的过渡概率热图
通过运行下面这段代码。
读入过渡矩阵CSV
trans_prob = pd.read_csv('Markov - Output - Transition matrix.csv')
将数据转换为浮点数
trans_prob ['transition_probability'] = trans_prob ['transition_probability'].astype(float)
将开始和转换事件转换为数值,这样我们就可以进行排序和迭代了
trans_prob .replace('(start)', '0', inplace=True)
trans_prob .replace('(conversion)', '21', inplace=True)
获取唯一的原产地通道
channel_from_unique = trans_prob ['channel_from'].unique().tolist()
channel_from_unique.sort(key=float)
获取唯一的目标通道
channel_to_unique = trans_prob ['channel_to'].unique().tolist()
channel_to_unique.sort(key=float)
创建新的矩阵,将原点和目的地通道作为列和索引
trans_matrix = pd.DataFrame(columns=channel_to_unique, index=channel_from_unique)
将概率分配给过渡矩阵中的相应单元格
for f in channel_from_unique:
for t in channel_to_unique:
x = trans_prob [(trans_prob ['channel_from'] == f) & (trans_prob ['channel_to'] == t)]
prob = x['transition_probability'].values
if prob.size > 0:
trans_matrix[t][f] = prob[0]
else:
trans_matrix[t][f] = 0
将所有概率转换为浮点数
trans_matrix = trans_matrix.apply(pd.to_numeric)
重命名我们的开始和转换事件
trans_matrix.rename(index={
'0': 'Start'}, inplace=True)
trans_matrix.rename(columns={
'21': 'Conversion'}, inplace=True)
在热图中显示这个过渡矩阵
sns.set_style("whiteegrid")
fig, ax = plt.subplots(figsize=(22, 12))
sns.heatmap(trans_matrix, cmap="RdBu_r")
plt.show()
结论
不同的营销渠道归因方法将适合不同的企业。在这篇文章中,我们概述了4种可能的方法来评估你的营销支出的有效性。我们探讨了3种方法,它们是固定的,即不依赖于你的数据结构,这可能导致过度自信。另一方面,马尔可夫链方法将通过考虑你的用户旅程数据的结构来寻找渠道归因模型;尽管这种方法更加复杂。
分析马尔科夫链模型的输出将给你一个特定时间点上的营销渠道有效性的 "快照"。通过查看新的营销活动推出前后的数据模型输出,你可能会获得额外的洞察力,给你提供关于活动如何影响每个渠道表现的基本信息。
通过增加更多的颗粒度和运行每日归因模型,你可以使用相关模型评估PPC或营销费用与渠道贡献之间的关系。
虽然在本文介绍的方法中加入更多的复杂性可以增加模型输出的价值,但真正的商业价值将来自于能够解释这些量化的模型结果,并将这些结果与你的业务领域知识和产生你的数据的战略业务举措相结合。
将这些模型结果与你的业务知识相结合,将使你能够最好地将模型结果纳入未来的计划中。
营销渠道归因可能是一项复杂的任务,而且消费者接触到的营销方式比以往任何时候都多。随着技术的进步和更多的渠道可供营销人员使用,准确地确定哪些渠道正在推动最大的投资回报率变得更加重要。
你如何从你的数据中挖掘出有价值的归因信息?
本文由 mdnice 多平台发布