目录
阐述
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。
用一个简单的例子来阐述:
假设我手里有三个不同的骰子。
第一个骰子6个面(称这个骰子为D6),每个面(1,2,3,4,5,6)出现的概率是1/6。
第二个骰子是个四面体(称这个骰子为D4),每个面(1,2,3,4)出现的概率是1/4。
第三个骰子有八个面(称这个骰子为D8),每个面(1,2,3,4,5,6,7,8)出现的概率是1/8。
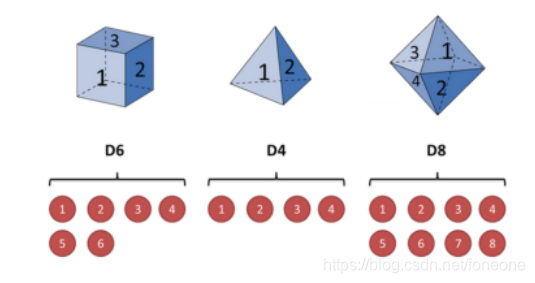
假设开始掷骰子,先从三个骰子里挑一个,挑到每一个骰子的概率都是1/3。然后掷骰子,得到一个数字:1,2,3,4,5,6,7,8中的一个。不停的重复上述过程,会得到一串数字,每个数字都是1,2,3,4,5,6,7,8中的一个。例如可能得到这么一串数字(掷骰子10次):1 6 3 5 2 7 3 5 2 4
这串数字叫做可见状态链(书中的观测数据)。但是在隐马尔可夫模型中,不仅仅有这么一串可见状态链,还有一串隐含状态链(状态序列)。在这个例子里,这串隐含状态链就是你用的骰子的序列。比如,隐含状态链有可能是:D6 D8 D8 D6 D4 D8 D6 D6 D4 D8

一般来说,HMM中说到的马尔可夫链其实是指隐含状态链,因为隐含状态(骰子)之间存在转换概率(transition probability)。
可见状态之间没有转换概率,但是隐含状态和可见状态之间有一个概率叫做输出概率(emission probability)。就我们的例子来说,六面骰(D6)产生1的输出概率是1/6。
采用《统计学习方法》书上的定义,将上述描述定义如下:
Q为所有可能发生的状态序列(共N个),V是所有可能的观测数列集合(共M个)。
I是长度为T的状态序列,O是对应的观测数据序列。
A是状态转移概率矩阵:
其中,,是在时刻t处于状态
的条件下在时刻t+1转移到状态
的概率。
B是观测概率矩阵:
其中,,是在时刻t处于
状态的条件下生成观测序列
的概率。
是初始状态概率向量:
其中,,是时刻t=1处于状态
的概率。
隐马尔可夫模型由初始状态概率向量,状态转移概率矩阵A和观测概率矩阵B决定。
和A决定状态序列,B决定观测序列。因此,隐马尔可夫模型
可以用三元符号表示,即
隐马尔可夫模型有3个基本问题:
(1)概率计算问题,在给定模型和观测序列O的情况下,计算在模型
下观测序列O出现的概率
;知道骰子有几种(隐含状态数量),也知道每种骰子掷出来数字的概率(观测概率矩阵),骰子之间如何转换比如现在是D4,下一个是D4,D6,D8的概率(状态转移概率矩阵),根据掷骰子掷出的结果(观测序列),想知道掷出这个结果(观测序列)的概率。
(2)预测问题(解码问题),已知模型和观测序列O,求给定观测序列条件概率
最大的状态序列I ,即给定观测序列,求最有可能的对应的状态序列;骰子有几种(隐含状态数量),也知道每种骰子掷出来数字的概率(观测概率矩阵),骰子之间如何转换(状态转移概率矩阵),根据掷骰子掷出的结果(观测序列),想知道每次(骰子共掷了10次)掷出来的都是哪种骰子(状态序列)
(3)学习问题,已知观测序列O,估计模型参数参数,使得在该模型下观测序列概率最大
,用极大似然估计的方法估计参数;知道骰子有几种(隐含状态数量),观测到很多次掷骰子的结果(观测序列),想反推出每种骰子掷出来数字的概率(观测概率矩阵),骰子之间如何转换(状态转移概率矩阵)
1.1 观测序列O出现的概率
1.1.1 穷举法(直接计算法)
通过列举所有可能产生观测序列O的状态,对于各个状态下求解产生观测序列的概率。然后对所有可能的概率求和,可以得到。
拿上面的骰子举例子,求最终观测预测为1 6 3 5 2 7 3 5 2 4的概率。
第一步:列举出可能产生此序列的状态,(1)可能序列:D4 D6 D4 D6 D4 D8 D8 D6 D4 D4(2)可能序列:D4 D6 D6 D8 D8 D8 D4 D6 D6 D4....
第二步:计算出产生这些状态的概率,然后在求出这些状态产生1 6 3 5 2 7 3 5 2 4的概率,将对应的状态和产生1 6 3 5 2 7 3 5 2 4的概率相乘(联合概率)
第三步:将所有可能概率求和,得到
上述过程用公式表示为:
状态序列I的概率为:
这个状态下,观测序列O的概率为:
O和I同时出现的概率为:
再对所有可能的状态序列I求和,得到观测序列O的概率
但是这样做工作量很大,是阶的,所以利用前向-后向算法。
1.1.2前向算法
这个前向算法的意思就是每次一个状态一个状态的来,假设初始状态为D4,那么下一个状态为D4,D6,D8,的概率分别为1/3,1/3,1/3,下下一个状态为D4的概率为:D4->D4+D6->D4+D8->D4=(1/3)*(1/3)+(1/3)*(1/3)+(1/3)*(1/3)
以此类推,在上述骰子问题中,第n次转移都是计算前n-1次状态累加而成的,所以避免了求解所有的状态概率,节约时间,所以前向算法的复杂度为,简要说明问题可以看下图。

(第一个状态为D4,第二个状态为D4、D6、D8的概率在第一次的基础上计算,第三次的状态为D4、D6、D8又在前一次的基础上计算)
上述过程,用公式表述如下:
首先定义前向概率:(t时刻的部分观测序列为,且状态为
的概率为前向概率)
可以递推求出前向概率和观测序列
递推算法如下:
1,初值:
2,递推,对于t=1,2,3,...,T-1
3,终止
1.1.3 后向算法
后向算法和前向算法差不多的道理,只不过这是从后往前推导,从最后一个观测序列开始。

定义后向概率:(在t时刻状态为的,从t+1到T的部分观测序列为
的概率为后向概率)
(1)最后时刻的所有状态规定为
(2)对于t=T-1,T-2,...,1
(3)最终求得的观测概率为
1.2 根据观测序列预测状态序列
继续拿上面的骰子举例子,假设最终观测预测为1 6 3 5 2 7 3 5 2 4,求解这个序列所对应的最有可能的状态序列是什么?
1.2.1 维特比算法(动态规划)
维特比算法实际上是用动态规划解马尔科夫模型预测问题,即用动态规划求解概率最大的路径(最优路径)。最优路径求解,必须保证每个路径之间都必须是最优的,否则其中就会有一条路径代替它。
以上面的骰子序列作为例子,假设D4、D6、D8产生1的概率分别为:1/4,1/6,1/8,故1对应的状态序列最优为D4,假设骰子之间转移概率相同,那么6为D6、D8的概率分别为1/6,1/8,因此第二个状态为D6,(如果状态转移概率不同,那么有可能第二个筛子状态为D8的可能性更大),顺着这样的思想依次求解,最终求得最后的状态序列。
上述描述过程,也就是维特比算法的过程,在这个过程中,既求解到了最优路径,又求解到了最大概率。
首先定义两个变量和
,定义在时刻t状态为i的所有单个路径
中概率最大值的为
由上述推导过程可知变量的递推公式为,
定义在时刻t状态为i的所有单个路径中概率最大的路径的第t-1个结点为:
维特比算法过程如下:
(1)初始化(初始状态向量乘以第一个观测):
(2)递推,对于t=2,3,...,T
(说明一下:t-1时刻状态[假设D4]乘以转移概率(0.1,0.2, 0.7)那么t时刻的概率分别为0.1,0.2, 0.7;再用t时刻的状态去乘以观测概率矩阵(0.8,0.1,0.1)这个的联合概率乘积中最大才是t时刻的最终状态,因为可能小状态概率对应大观测概率)
记录当前状态:
(3)终止:
(4)最优路径回溯.对于
求得的最优路径也就是最可能的状态序列为:
解释一下这里为什么是最优路径回溯:
因为记录的是当前t时刻、状态为i时,第t-1个结点是哪个的状态。用骰子距离,假设t-1时刻D4、D6、D8的状态概率分别为(0.1,0.4,0.5),
max[(0.1,0.4,0.5)*(D4->D4的转化概率、D6->D4的转化概率、D8->D4的转化概率)],假设这个过程中,D6->D4转化概率最大,故
D6;当计算t时刻,状态为D6的上一个结点时,同理但是此时
可能等于D8。因此
仅是记录上一结点到这一节点最大的概率。
当通过公式,计算出T时刻,状态为i时,就可以利用公式
,计算出每一次迭代过程存储的最大概率下的上一结点信息,因此这里涉及到一个回溯的过程。
1.3 估计模型参数
用的EM算法。因为状态序列看不见(隐藏变量),只能用观测序列(观测数据)去推导。
先求解函数Q(E步),再极大化求解参数(M步)。
由EM算法的Q函数可以写出如下推导:
由于对于
是一个常数,故(其中
是上一次迭代出来的,是一个常数,
是一个变量):
由于:
故:
至此E步完成。构造出来了Q函数,下面就是对Q函数极大化然后更新参数(M步)。
M步:由于模型中有三个参数要求解,。并且Q函数里面三个参数是求和的形式,所以求解
只取其中一部分就行了。
《统计学习方法》书中给出了的求解,所以我列一个a的求解。
由于(为什么是j不是i呢?可以看一下a状态转移概率矩阵,每一行都是一个状态(t-1时刻)向下一个时刻(t时刻)所有状态转移的概率,所以概率为1)
利用拉格朗日函数求解,构造的拉格朗日函数形式如下:
对上式求导数得,
即
(1)
对上式所有j求和可得:
把上述结果带入(1)可得:
以上述同样的方法也可以求解出其他两个变量:
、
扩展:
(1)给定模型和观测序列O,在时刻t处于状态
的概率,记为:
由前向概率和后向概率定义可知,
故
即利用刻画,单个时刻的状态概率。
(2)给定模型和观测序列O,在时刻t处于状态
的概率,t+1时刻处于
的状态概率为:
利用上述方法有,
因此在利用学习算法(EM)算法求解出各个参数后,
可以进行进一步化简表示,即
(1)
(2)
(3)
故学习问题可以利用骰子模型,这样做实验。
(1)给定初始参数:,
,
(2)
A.开始掷筛子,记录观测序列(1次实验,掷10次),得到10组观测序列如下:
第一组:1,3,5,7,3,1,3,2,6,8
第二组:2,3,6,4,1,8,7,5,3,4
第三组:6,3,1,5,3,2,7,2,1,5
以此类推......
B.利用给定初始参数,计算10组观测序列对应的最可能的状态序列(D4简写为4)如下:
第一组:4,6,4,4,8,4,6,4,6,8
第二组:4,6,8,4,6,8,8,4,4,6
第三组:6,4,4,4,6,4,8,4,4,6
以此类推.....
C.根据B步骤得到的状态序列,和公式(1)(2)(3)更新参数,
,
(3) 重复步骤(2),直至参数稳定在某一数值,或者两次参数更新小于某一接受范围。
上述实验思想原理产生于鲍姆-韦尔奇算法(Baum-Welch Algorithm),每一次迭代都是估计新的模型参数,使得输出的概率最大化,因此这个过程叫做期望最大化(Expectation-Maximization)简称EM。
通过上述实验步骤,就可以利用EM算法,得到HMM的学习参数。
上述实验步骤,是我自己想出来的,不具有特别严谨性。(如有不妥,欢迎指教)
参考文献:
列举的模型来自:https://blog.csdn.net/zxm1306192988/article/details/78595933
公式来自:《统计学习方法》-李航
