本文和大家一起学习一个当下比较流行的网络,但是也是比较基础的-序列网络(SEQ2SEQ),为什么要引入这个网络呢?因为在很多
序列处理的应用的场景中,比如机器翻译,文章摘要提取,评价数据分析等,在NLP中传统的rnn效率太低而且准确度也不够高,所以才
会有它的存在,它的出现很好的解决自然语言使用的难点,目前它可以是一个通用的模型,很多后来的模型都是在此基础之上进行优化
而来的,所以我们需要学好这个网络,OK 那接下来我们就开始学习,因为有了rnn的基础,学它还是比较容易的。。
1 从rnn结构说起
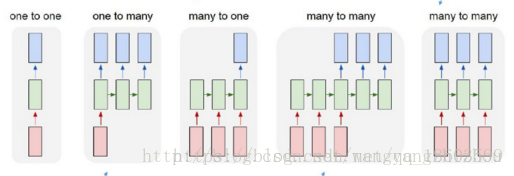
根据输出和输入序列不同数量rnn可以有多种不同的结构,不同结构自然就有不同的引用场合。如下图,
- one to one 结构,仅仅只是简单的给一个输入得到一个输出,此处并未体现序列的特征,例如图像分类场景。
- one to many 结构,给一个输入得到一系列输出,这种结构可用于生产图片描述的场景。
- many to one 结构,给一系列输入得到一个输出,这种结构可用于文本情感分析,对一些列的文本输入进行分类,看是消极还是积极情感。
- many to many 结构,给一些列输入得到一系列输出,这种结构可用于翻译或聊天对话场景,对输入的文本转换成另外一些列文本。
- 同步 many to many 结构,它是经典的rnn结构,前一输入的状态会带到下一个状态中,而且每个输入都会对应一个输出,我们最熟悉的就是用于字符预测了,同样也可以用于视频分类,对视频的帧打标签。
2 seq2seq模型核心思想
seq2seq模型是在2014年,是由Google Brain团队和Yoshua Bengio 两个团队各自独立的提出来[1] 和 [2],他们发表的文章主要关注的是机器翻译相关的问题。而seq2seq模型,简单来说就是一个翻译模型,把一个语言序列翻译成另一种语言序列,整个处理过程是通过使用深度神经网络( LSTM (长短记忆网络),或者RNN (递归神经网络)前面的文章已经详细的介绍过,这里就不再详细介绍) 将一个序列作为输入影射为另外一个输出序列,如下图所示:
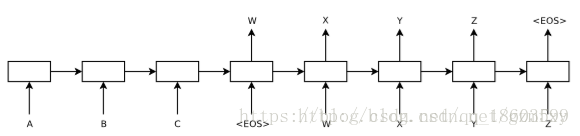

在文章中整个模型图为如下图所示:
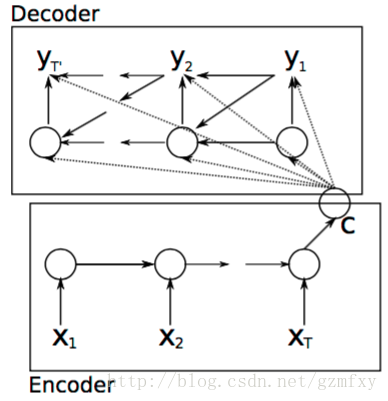
整个模型和第一部分介绍的类似,整个模型分为解码和编码的过程,编码的过程结束后悔输出一个语义向量c,之后整个解码过程根据c进行相应的学习输出。
对于整个编码的过程就是上面第二部分介绍的RNN网络学习的的过程,最后输出一个向量c。而对于解码过程,对应的是另外一个RNN网络,其隐藏层状态在t时刻的更新根据如下方程进行更新:
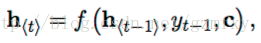
除了新加了c变量以外,其它和RNN原本的函数关系是一样的。类似的条件概率公式可以写为:
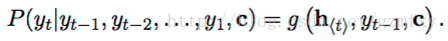
对于整个输入编码和解码的过程中,文行中使用梯度优化算法以及最大似然条件概率为损失函数去进行模型的训练和优化:
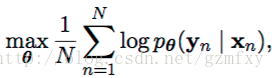
其中sita为相应模型中的参数,(xn, yn)是相应的输入和输出的序列。
我们总结一下,seq2seq具体组成部分
Encoder:编码过程-一个单独的rnn过程
Decoder:解码过程-一个单独的rnn过程
连接两者的中间状态向量-长度是固定的:中间状态维护
切记:rnn不接收可变序列,所以序列的长度一定要一致
接下来在熟悉完理论知识之后我们来做一个实践应用,做一个单词的字母排序,比如输入单词是'acbd',输出单词是'abcd',要让机器学会这种排序算法,就可以使用seq2seq的模型来完成,接下来我们分析一下核心步骤,最后会给予一个能直接运行的完整代码给大家学习
1 数据集的准备,这里有两个文件分别是source.txt和target.txt,对应的分别是输入文件和输出文件
#读取输入文件 with open('data/letters_source.txt', 'r', encoding='utf-8') as f: source_data = f.read() #读取输出文件 with open('data/letters_target.txt', 'r', encoding='utf-8') as f: target_data = f.read()
2 数据集的预处理:填充序列,序列字符和ID的转换
#数据预处理 def extract_character_vocab(data): # 使用特定的字符进行序列的填充 special_words = ['<PAD>', '<UNK>', '<GO>', '<EOS>'] set_words = list(set([character for line in data.split('\n') for character in line])) # 这里要把四个特殊字符添加进词典 int_to_vocab = {idx: word for idx, word in enumerate(special_words + set_words)} vocab_to_int = {word: idx for idx, word in int_to_vocab.items()} return int_to_vocab, vocab_to_int source_int_to_letter, source_letter_to_int = extract_character_vocab(source_data) target_int_to_letter, target_letter_to_int = extract_character_vocab(target_data) # 对字母进行转换 source_int = [[source_letter_to_int.get(letter, source_letter_to_int['<UNK>']) for letter in line] for line in source_data.split('\n')] target_int = [[target_letter_to_int.get(letter, target_letter_to_int['<UNK>']) for letter in line] + [target_letter_to_int['<EOS>']] for line in target_data.split('\n')] print('source_int_head',source_int[:10])
填充字符含义:
- < PAD>: 补全字符。
- < EOS>: 解码器端的句子结束标识符。
- < UNK>: 低频词或者一些未遇到过的词等。
- < GO>: 解码器端的句子起始标识符。
3 创建编码层
# 创建编码层 def get_encoder_layer(input_data, rnn_size, num_layers,source_sequence_length, source_vocab_size,encoding_embedding_size): # Encoder embedding encoder_embed_input = layer.embed_sequence(ids=input_data, vocab_size=source_vocab_size,embed_dim=encoding_embedding_size) # RNN cell def get_lstm_cell(rnn_size): lstm_cell = rnn.LSTMCell(rnn_size, initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2)) return lstm_cell # 指定多个lstm cell = rnn.MultiRNNCell([get_lstm_cell(rnn_size) for _ in range(num_layers)]) # 返回output,state encoder_output, encoder_state = tf.nn.dynamic_rnn(cell=cell, inputs=encoder_embed_input,sequence_length=source_sequence_length, dtype=tf.float32) return encoder_output, encoder_state
参数变量含义:
- input_data: 输入tensor - rnn_size: rnn隐层结点数量 - num_layers: 堆叠的rnn cell数量 - source_sequence_length: 源数据的序列长度 - source_vocab_size: 源数据的词典大小 - encoding_embedding_size: embedding的大小
4 创建解码层
4.1 对编码之后的字符串进行处理,去除最后一个没用的字符串
#对编码数据进行处理,移除最后一个字符 def process_decoder_input(data, vocab_to_int, batch_size): ''' 补充<GO>,并移除最后一个字符 ''' # cut掉最后一个字符 ending = tf.strided_slice(data, [0, 0], [batch_size, -1], [1, 1]) decoder_input = tf.concat([tf.fill([batch_size, 1], vocab_to_int['<GO>']), ending], 1) return decoder_input
4.2 创建解码层
#创建解码层 def decoding_layer(target_letter_to_int, decoding_embedding_size, num_layers, rnn_size, target_sequence_length, max_target_sequence_length, encoder_state, decoder_input): # 1 构建向量 # 目标词汇的长度 target_vocab_size = len(target_letter_to_int) # 定义解码向量的维度大小 decoder_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, decoding_embedding_size])) # 解码之后向量的输出 decoder_embed_input = tf.nn.embedding_lookup(decoder_embeddings, decoder_input) # 2. 构造Decoder中的RNN单元 def get_decoder_cell(rnn_size): decoder_cell = rnn.LSTMCell(num_units=rnn_size,initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2)) return decoder_cell cell = tf.contrib.rnn.MultiRNNCell([get_decoder_cell(rnn_size) for _ in range(num_layers)]) # 3. Output全连接层 output_layer = Dense(units=target_vocab_size,kernel_initializer=tf.truncated_normal_initializer(mean=0.0, stddev=0.1)) # 4. Training decoder with tf.variable_scope("decode"): # 得到help对象 training_helper = seq2seq.TrainingHelper(inputs=decoder_embed_input,sequence_length=target_sequence_length,time_major=False) # 构造decoder training_decoder = seq2seq.BasicDecoder(cell=cell,helper=training_helper,initial_state=encoder_state,output_layer=output_layer) training_decoder_output, _ ,_= seq2seq.dynamic_decode(decoder=training_decoder,impute_finished=True,maximum_iterations=max_target_sequence_length) # 5. Predicting decoder # 与training共享参数 with tf.variable_scope("decode", reuse=True): # 创建一个常量tensor并复制为batch_size的大小 start_tokens = tf.tile(tf.constant([target_letter_to_int['<GO>']], dtype=tf.int32), [batch_size],name='start_tokens') predicting_helper = seq2seq.GreedyEmbeddingHelper(decoder_embeddings,start_tokens,target_letter_to_int['<EOS>']) predicting_decoder = seq2seq.BasicDecoder(cell=cell,helper=predicting_helper,initial_state=encoder_state,output_layer=output_layer) predicting_decoder_output, _ ,_= seq2seq.dynamic_decode(decoder=predicting_decoder,impute_finished=True,maximum_iterations=max_target_sequence_length) return training_decoder_output, predicting_decoder_output
在构建解码这一块使用到了,参数共享机制 tf.variable_scope(""),方法参数含义
参数: - target_letter_to_int: target数据的映射表 - decoding_embedding_size: embed向量大小 - num_layers: 堆叠的RNN单元数量 - rnn_size: RNN单元的隐层结点数量 - target_sequence_length: target数据序列长度 - max_target_sequence_length: target数据序列最大长度 - encoder_state: encoder端编码的状态向量 - decoder_input: decoder端输入
5 构建seq2seq模型,把解码和编码串在一起
#构建序列模型 def seq2seq_model(input_data, targets, lr, target_sequence_length, max_target_sequence_length, source_sequence_length, source_vocab_size, target_vocab_size, encoder_embedding_size, decoder_embedding_size, rnn_size, num_layers): # 获取encoder的状态输出 _, encoder_state = get_encoder_layer(input_data, rnn_size, num_layers, source_sequence_length, source_vocab_size, encoding_embedding_size) # 预处理后的decoder输入 decoder_input = process_decoder_input(targets, target_letter_to_int, batch_size) # 将状态向量与输入传递给decoder training_decoder_output, predicting_decoder_output = decoding_layer(target_letter_to_int, decoding_embedding_size, num_layers, rnn_size, target_sequence_length, max_target_sequence_length, encoder_state, decoder_input) return training_decoder_output, predicting_decoder_output
6 创建模型输入参数
# 创建模型输入参数 def get_inputs(): inputs = tf.placeholder(tf.int32, [None, None], name='inputs') targets = tf.placeholder(tf.int32, [None, None], name='targets') learning_rate = tf.placeholder(tf.float32, name='learning_rate') # 定义target序列最大长度(之后target_sequence_length和source_sequence_length会作为feed_dict的参数) target_sequence_length = tf.placeholder(tf.int32, (None,), name='target_sequence_length') max_target_sequence_length = tf.reduce_max(target_sequence_length, name='max_target_len') source_sequence_length = tf.placeholder(tf.int32, (None,), name='source_sequence_length') return inputs, targets, learning_rate, target_sequence_length, max_target_sequence_length, source_sequence_length
7 训练数据准备和生成
7.1 数据填充
# 对batch中的序列进行补全,保证batch中的每行都有相同的sequence_length def pad_sentence_batch(sentence_batch, pad_int): ''' 参数: - sentence batch - pad_int: <PAD>对应索引号 ''' max_sentence = max([len(sentence) for sentence in sentence_batch]) return [sentence + [pad_int] * (max_sentence - len(sentence)) for sentence in sentence_batch]
7.2 批量数据获取
# 批量数据生成 def get_batches(targets, sources, batch_size, source_pad_int, target_pad_int): ''' 定义生成器,用来获取batch ''' for batch_i in range(0, len(sources) // batch_size): start_i = batch_i * batch_size sources_batch = sources[start_i:start_i + batch_size] targets_batch = targets[start_i:start_i + batch_size] # 补全序列 pad_sources_batch = np.array(pad_sentence_batch(sources_batch, source_pad_int)) pad_targets_batch = np.array(pad_sentence_batch(targets_batch, target_pad_int)) # 记录每条记录的长度 pad_targets_lengths = [] for target in pad_targets_batch: pad_targets_lengths.append(len(target)) pad_source_lengths = [] for source in pad_sources_batch: pad_source_lengths.append(len(source)) yield pad_targets_batch, pad_sources_batch, pad_targets_lengths, pad_source_lengths
到此核心步骤基本上就分析完了,最后还剩训练和预测,在这里把完整的代码给大家展示:
# -*- coding: utf-8 -*- # author jiahp # description train seq2seq model for sort word of key from tensorflow.python.layers.core import Dense import numpy as np import time import tensorflow as tf import tensorflow.contrib.layers as layer import tensorflow.contrib.rnn as rnn import tensorflow.contrib.seq2seq as seq2seq #读取输入文件 with open('data/letters_source.txt', 'r', encoding='utf-8') as f: source_data = f.read() #读取输出文件 with open('data/letters_target.txt', 'r', encoding='utf-8') as f: target_data = f.read() print('source_data_head',source_data.split('\n')[:10]) #数据预处理 def extract_character_vocab(data): # 使用特定的字符进行序列的填充 special_words = ['<PAD>', '<UNK>', '<GO>', '<EOS>'] set_words = list(set([character for line in data.split('\n') for character in line])) # 这里要把四个特殊字符添加进词典 int_to_vocab = {idx: word for idx, word in enumerate(special_words + set_words)} vocab_to_int = {word: idx for idx, word in int_to_vocab.items()} return int_to_vocab, vocab_to_int source_int_to_letter, source_letter_to_int = extract_character_vocab(source_data) target_int_to_letter, target_letter_to_int = extract_character_vocab(target_data) # 对字母进行转换 source_int = [[source_letter_to_int.get(letter, source_letter_to_int['<UNK>']) for letter in line] for line in source_data.split('\n')] target_int = [[target_letter_to_int.get(letter, target_letter_to_int['<UNK>']) for letter in line] + [target_letter_to_int['<EOS>']] for line in target_data.split('\n')] print('source_int_head',source_int[:10]) # 创建模型输入参数 def get_inputs(): inputs = tf.placeholder(tf.int32, [None, None], name='inputs') targets = tf.placeholder(tf.int32, [None, None], name='targets') learning_rate = tf.placeholder(tf.float32, name='learning_rate') # 定义target序列最大长度(之后target_sequence_length和source_sequence_length会作为feed_dict的参数) target_sequence_length = tf.placeholder(tf.int32, (None,), name='target_sequence_length') max_target_sequence_length = tf.reduce_max(target_sequence_length, name='max_target_len') source_sequence_length = tf.placeholder(tf.int32, (None,), name='source_sequence_length') return inputs, targets, learning_rate, target_sequence_length, max_target_sequence_length, source_sequence_length ''' 构造Encoder层 参数说明: - input_data: 输入tensor - rnn_size: rnn隐层结点数量 - num_layers: 堆叠的rnn cell数量 - source_sequence_length: 源数据的序列长度 - source_vocab_size: 源数据的词典大小 - encoding_embedding_size: embedding的大小 ''' # 创建编码层 def get_encoder_layer(input_data, rnn_size, num_layers,source_sequence_length, source_vocab_size,encoding_embedding_size): # Encoder embedding encoder_embed_input = layer.embed_sequence(ids=input_data, vocab_size=source_vocab_size,embed_dim=encoding_embedding_size) # RNN cell def get_lstm_cell(rnn_size): lstm_cell = rnn.LSTMCell(rnn_size, initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2)) return lstm_cell # 指定多个lstm cell = rnn.MultiRNNCell([get_lstm_cell(rnn_size) for _ in range(num_layers)]) # 返回output,state encoder_output, encoder_state = tf.nn.dynamic_rnn(cell=cell, inputs=encoder_embed_input,sequence_length=source_sequence_length, dtype=tf.float32) return encoder_output, encoder_state #对编码数据进行处理,移除最后一个字符 def process_decoder_input(data, vocab_to_int, batch_size): ''' 补充<GO>,并移除最后一个字符 ''' # cut掉最后一个字符 ending = tf.strided_slice(data, [0, 0], [batch_size, -1], [1, 1]) decoder_input = tf.concat([tf.fill([batch_size, 1], vocab_to_int['<GO>']), ending], 1) return decoder_input ''' 构造Decoder层 参数: - target_letter_to_int: target数据的映射表 - decoding_embedding_size: embed向量大小 - num_layers: 堆叠的RNN单元数量 - rnn_size: RNN单元的隐层结点数量 - target_sequence_length: target数据序列长度 - max_target_sequence_length: target数据序列最大长度 - encoder_state: encoder端编码的状态向量 - decoder_input: decoder端输入 ''' #创建解码层 def decoding_layer(target_letter_to_int, decoding_embedding_size, num_layers, rnn_size, target_sequence_length, max_target_sequence_length, encoder_state, decoder_input): # 1 构建向量 # 目标词汇的长度 target_vocab_size = len(target_letter_to_int) # 定义解码向量的维度大小 decoder_embeddings = tf.Variable(tf.random_uniform([target_vocab_size, decoding_embedding_size])) # 解码之后向量的输出 decoder_embed_input = tf.nn.embedding_lookup(decoder_embeddings, decoder_input) # 2. 构造Decoder中的RNN单元 def get_decoder_cell(rnn_size): decoder_cell = rnn.LSTMCell(num_units=rnn_size,initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2)) return decoder_cell cell = tf.contrib.rnn.MultiRNNCell([get_decoder_cell(rnn_size) for _ in range(num_layers)]) # 3. Output全连接层 output_layer = Dense(units=target_vocab_size,kernel_initializer=tf.truncated_normal_initializer(mean=0.0, stddev=0.1)) # 4. Training decoder with tf.variable_scope("decode"): # 得到help对象 training_helper = seq2seq.TrainingHelper(inputs=decoder_embed_input,sequence_length=target_sequence_length,time_major=False) # 构造decoder training_decoder = seq2seq.BasicDecoder(cell=cell,helper=training_helper,initial_state=encoder_state,output_layer=output_layer) training_decoder_output, _ ,_= seq2seq.dynamic_decode(decoder=training_decoder,impute_finished=True,maximum_iterations=max_target_sequence_length) # 5. Predicting decoder # 与training共享参数 with tf.variable_scope("decode", reuse=True): # 创建一个常量tensor并复制为batch_size的大小 start_tokens = tf.tile(tf.constant([target_letter_to_int['<GO>']], dtype=tf.int32), [batch_size],name='start_tokens') predicting_helper = seq2seq.GreedyEmbeddingHelper(decoder_embeddings,start_tokens,target_letter_to_int['<EOS>']) predicting_decoder = seq2seq.BasicDecoder(cell=cell,helper=predicting_helper,initial_state=encoder_state,output_layer=output_layer) predicting_decoder_output, _ ,_= seq2seq.dynamic_decode(decoder=predicting_decoder,impute_finished=True,maximum_iterations=max_target_sequence_length) return training_decoder_output, predicting_decoder_output #构建序列模型 def seq2seq_model(input_data, targets, lr, target_sequence_length, max_target_sequence_length, source_sequence_length, source_vocab_size, target_vocab_size, encoder_embedding_size, decoder_embedding_size, rnn_size, num_layers): # 获取encoder的状态输出 _, encoder_state = get_encoder_layer(input_data, rnn_size, num_layers, source_sequence_length, source_vocab_size, encoding_embedding_size) # 预处理后的decoder输入 decoder_input = process_decoder_input(targets, target_letter_to_int, batch_size) # 将状态向量与输入传递给decoder training_decoder_output, predicting_decoder_output = decoding_layer(target_letter_to_int, decoding_embedding_size, num_layers, rnn_size, target_sequence_length, max_target_sequence_length, encoder_state, decoder_input) return training_decoder_output, predicting_decoder_output # 超参数 # Number of Epochs epochs = 60 # Batch Size batch_size = 128 # RNN Size rnn_size = 50 # Number of Layers num_layers = 2 # Embedding Size encoding_embedding_size = 15 decoding_embedding_size = 15 # Learning Rate learning_rate = 0.001 # 构造graph train_graph = tf.Graph() with train_graph.as_default(): # 获得模型输入 input_data, targets, lr, target_sequence_length, max_target_sequence_length, source_sequence_length = get_inputs() training_decoder_output, predicting_decoder_output = seq2seq_model(input_data, targets, lr, target_sequence_length, max_target_sequence_length, source_sequence_length, len(source_letter_to_int), len(target_letter_to_int), encoding_embedding_size, decoding_embedding_size, rnn_size, num_layers) training_logits = tf.identity(training_decoder_output.rnn_output, 'logits') predicting_logits = tf.identity(predicting_decoder_output.sample_id, name='predictions') masks = tf.sequence_mask(target_sequence_length, max_target_sequence_length, dtype=tf.float32, name='masks') with tf.name_scope("optimization"): # Loss function cost = tf.contrib.seq2seq.sequence_loss( training_logits, targets, masks) # Optimizer optimizer = tf.train.AdamOptimizer(lr) # Gradient Clipping 基于定义的min与max对tesor数据进行截断操作,目的是为了应对梯度爆发或者梯度消失的情况 gradients = optimizer.compute_gradients(cost) capped_gradients = [(tf.clip_by_value(grad, -5., 5.), var) for grad, var in gradients if grad is not None] train_op = optimizer.apply_gradients(capped_gradients) # 对batch中的序列进行补全,保证batch中的每行都有相同的sequence_length def pad_sentence_batch(sentence_batch, pad_int): ''' 参数: - sentence batch - pad_int: <PAD>对应索引号 ''' max_sentence = max([len(sentence) for sentence in sentence_batch]) return [sentence + [pad_int] * (max_sentence - len(sentence)) for sentence in sentence_batch] # 批量数据生成 def get_batches(targets, sources, batch_size, source_pad_int, target_pad_int): ''' 定义生成器,用来获取batch ''' for batch_i in range(0, len(sources) // batch_size): start_i = batch_i * batch_size sources_batch = sources[start_i:start_i + batch_size] targets_batch = targets[start_i:start_i + batch_size] # 补全序列 pad_sources_batch = np.array(pad_sentence_batch(sources_batch, source_pad_int)) pad_targets_batch = np.array(pad_sentence_batch(targets_batch, target_pad_int)) # 记录每条记录的长度 pad_targets_lengths = [] for target in pad_targets_batch: pad_targets_lengths.append(len(target)) pad_source_lengths = [] for source in pad_sources_batch: pad_source_lengths.append(len(source)) yield pad_targets_batch, pad_sources_batch, pad_targets_lengths, pad_source_lengths # 将数据集分割为train和validation train_source = source_int[batch_size:] train_target = target_int[batch_size:] # 留出一个batch进行验证 valid_source = source_int[:batch_size] valid_target = target_int[:batch_size] (valid_targets_batch, valid_sources_batch, valid_targets_lengths, valid_sources_lengths) = next(get_batches(valid_target, valid_source, batch_size, source_letter_to_int['<PAD>'], target_letter_to_int['<PAD>'])) display_step = 50 # 每隔50轮输出loss checkpoint = "model/trained_model.ckpt" # 准备训练模型 with tf.Session(graph=train_graph) as sess: sess.run(tf.global_variables_initializer()) for epoch_i in range(1, epochs + 1): for batch_i, (targets_batch, sources_batch, targets_lengths, sources_lengths) in enumerate( get_batches(train_target, train_source, batch_size, source_letter_to_int['<PAD>'], target_letter_to_int['<PAD>'])): _, loss = sess.run( [train_op, cost], {input_data: sources_batch, targets: targets_batch, lr: learning_rate, target_sequence_length: targets_lengths, source_sequence_length: sources_lengths}) if batch_i % display_step == 0: # 计算validation loss validation_loss = sess.run( [cost], {input_data: valid_sources_batch, targets: valid_targets_batch, lr: learning_rate, target_sequence_length: valid_targets_lengths, source_sequence_length: valid_sources_lengths}) print('Epoch {:>3}/{} Batch {:>4}/{} - Training Loss: {:>6.3f} - Validation loss: {:>6.3f}' .format(epoch_i, epochs, batch_i, len(train_source) // batch_size, loss, validation_loss[0])) # 保存模型 saver = tf.train.Saver() saver.save(sess, checkpoint) print('Model Trained and Saved') #对源数据进行转换 def source_to_seq(text): sequence_length = 7 return [source_letter_to_int.get(word, source_letter_to_int['<UNK>']) for word in text] + [source_letter_to_int['<PAD>']]*(sequence_length-len(text)) # 输入一个单词 input_word = 'acdbf' text = source_to_seq(input_word) checkpoint = "model/trained_model.ckpt" loaded_graph = tf.Graph() #模型预测 with tf.Session(graph=loaded_graph) as sess: # 加载模型 loader = tf.train.import_meta_graph(checkpoint + '.meta') loader.restore(sess, checkpoint) input_data = loaded_graph.get_tensor_by_name('inputs:0') logits = loaded_graph.get_tensor_by_name('predictions:0') source_sequence_length = loaded_graph.get_tensor_by_name('source_sequence_length:0') target_sequence_length = loaded_graph.get_tensor_by_name('target_sequence_length:0') answer_logits = sess.run(logits, {input_data: [text] * batch_size, target_sequence_length: [len(text)] * batch_size, source_sequence_length: [len(text)] * batch_size})[0] pad = source_letter_to_int["<PAD>"] print('原始输入:', input_word) print('\nSource') print(' Word 编号: {}'.format([i for i in text])) print(' Input Words: {}'.format(" ".join([source_int_to_letter[i] for i in text]))) print('\nTarget') print(' Word 编号: {}'.format([i for i in answer_logits if i != pad])) print(' Response Words: {}'.format(" ".join([target_int_to_letter[i] for i in answer_logits if i != pad])))
然后我们看看最终的运行效果:
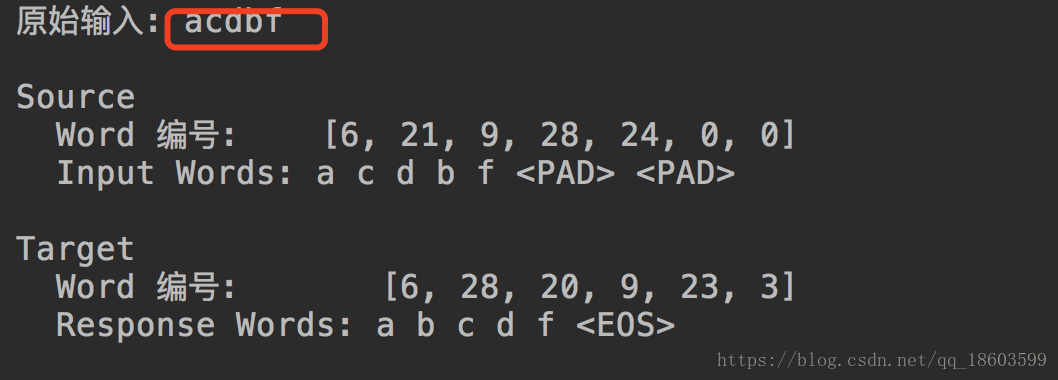
发现机器已经学会对输入的单词进行字母排序了,但是遗憾的是 如果输入字符太长比如 20 甚至30个 大家再测试一下,会发现排序不是那么准确了,原因是因为序列太长了,这也是基础的seq2seq的不足,所以需要优化它,怎么优化呢?就是加上attetion机制,这个会在讲解如何通过seq2seq实现文本摘要的提取会讲解到,OK seq2seq的基础使用就讲完了。。。