本文介绍一个新的网络rnn以及相关的优化lstm和对应的变体网络结构,首先我们介绍一下rnn,它被称为循环网络....
它相比我们之前下学习的cnn是有所不同的,一般牵涉到图片相关的识别应用都是会考虑使用cnn,但是如果现在要是有一个这样的场景,比如我们通常所说的上下文预测,上一句我是'中国',要预测下一句是什么,从正常的角度来说,我们会考虑应该是‘人’的概率比较大。
这种情况如果是cnn就很难实现了,为什么呢?因为这个过程牵涉到‘记忆’功能..CNN是不具备记忆的功能,而rnn是有记忆功能,所以大家要明白各自的使用场景
CNN:图片识别,生成,定位,文本分类
RNN:自然语言处理-和序列相关的以及需要记忆的应用都可以考虑使用该网络。
首先我们学习一下RNN的结构和知识:
RNN( Recurrent Neural Networks循环神经网络)
循环神经网络的主要用途是处理和预测序列数据,在全连接神经网络或卷积神经网络中,网络结果都是从输入层到隐含层再到输出层,层与层之间是全连接或部分连接的,但每层之间的结点是无连接的。考虑这样一个问题,如果要预测句子的下一个单词是什么,一般需要用到当前单词以及前面的单词,因为句子中前后单词并不是独立的,比如,当前单词是“很”,前一个单词是“天空”,那么下一个单词很大概率是“蓝”。循环神经网络的来源就是为了刻画一个序列当前的输出与之前信息的关系。从网络结果上来说,RNN会记忆之前的信息,并利用之前的信息影响后面的输出。也就是说,RNN的隐藏层之间的结点是有连接的,隐藏层的输入不仅包括输入层的输出,还包含上一时刻隐藏层的输出。
典型的RNN结构如下图所示,对于RNN来说,一个非常重要的概念就是时刻,RNN会对于每一个时刻的输入结合当前模型的状态给出一个输出,从图中可以看出,RNN的主体结构A的输入除了来自输入层的Xt,还有一个循环的边来提供当前时刻的状态。同时A的状态也会从当前步传递到下一步。

我们将这个循环展开,可以很清晰地看到信息在隐藏层之间的传递:

链式的特征揭示了 RNN 本质上是与序列和列表相关的。他们是对于这类数据的最自然的神经网络架构。
并且 RNN 也已经被人们应用了!在过去几年中,应用 RNN 在语音识别,语言建模,翻译,图片描述等问题上已经取得一定成功,并且这个列表还在增长。但是从图中可以看出来一个问题,就是后一个记忆的东西都是依赖于前一个,而前一个依赖于前一个的前一个,因为往往真实的应用场景中序列是很长的,这样就会出现一个问题,越到后面的单元记忆到的东西很少,甚至没有.,所有RNN是有一定的缺点,下面我们就介绍一下它的缺点:
长期依赖(Long-Term Dependencies)问题
RNN 的关键点之一就是他们可以用来连接先前的信息到当前的任务上,例如使用过去的视频段来推测对当前段的理解。如果 RNN 可以做到这个,他们就变得非常有用。但是真的可以么?答案是,还有很多依赖因素。
有时候,我们仅仅需要知道先前的信息来执行当前的任务。例如,我们有一个语言模型用来基于先前的词来预测下一个词。如果我们试着预测 “the clouds are in the sky” 最后的词,我们并不需要任何其他的上下文 —— 因此下一个词很显然就应该是 sky。在这样的场景中,相关的信息和预测的词位置之间的间隔是非常小的,RNN 可以学会使用先前的信息。但是同样会有一些更加复杂的场景。假设我们试着去预测“I grew up in France... I speak fluent French”最后的词。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的 France 的上下文的。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大。
不幸的是,在这个间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。
在理论上,RNN 绝对可以处理这样的 长期依赖 问题。人们可以仔细挑选参数来解决这类问题中的最初级形式,但在实践中,RNN 肯定不能够成功学习到这些知识。如果序列过长会导致优化时出现梯度消散的问题。所以需要一个优化的网络,它就是LSTM,它就可以很好的去解决上面说到的问题.
LSTM 网络
Long Short Term Memory 网络—— 一般就叫做 LSTM ——是一种特殊的 RNN 类型,可以学习长期依赖信息。LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。
LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。
LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。LSTM是一种拥有三个“门”结构的特殊网络结构。
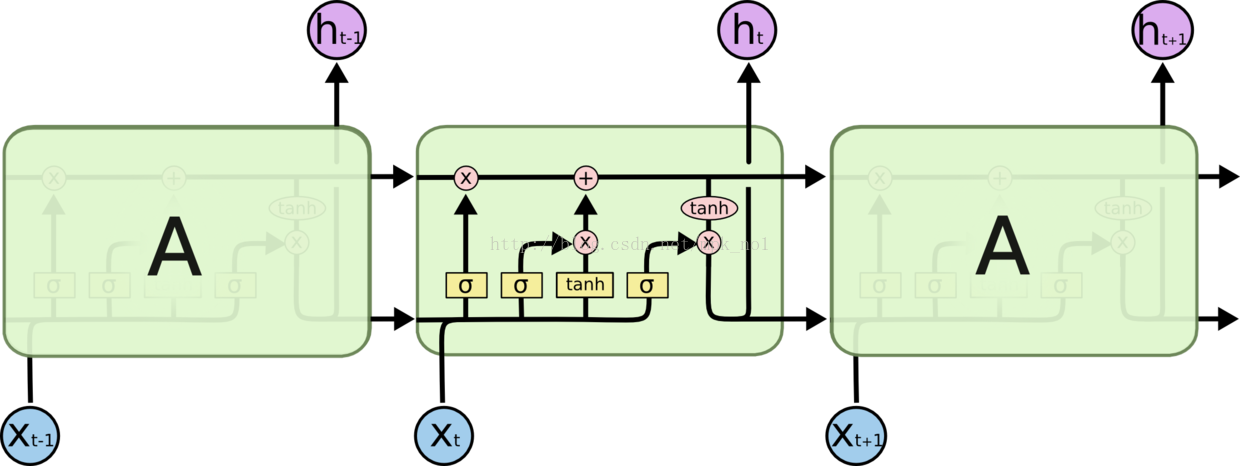
LSTM 靠一些“门”的结构让信息有选择性地影响RNN中每个时刻的状态。所谓“门”的结构就是一个使用sigmod神经网络和一个按位做乘法的操作,这两个操作合在一起就是一个“门”结构。之所以该结构叫做门是因为使用sigmod作为激活函数的全连接神经网络层会输出一个0到1之间的值,描述当前输入有多少信息量可以通过这个结构,于是这个结构的功能就类似于一扇门,当门打开时(sigmod输出为1时),全部信息都可以通过;当门关上时(sigmod输出为0),任何信息都无法通过。
如上图所示,我们用以下几个公式来描述LSTM一个循环体的结构组成:
输入门:
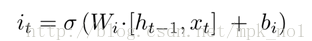
遗忘门:
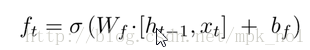
候选记忆单元:
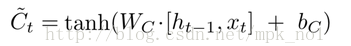
当前时刻记忆单元:
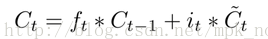
输出门:

输出:
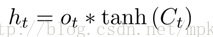
个人感觉lstm的核心点就是一个'门',来有区别的进行记忆和过滤信息的,我们总结一下普通的rnn和lstm的区别,可以这样理解
rnn:没有过滤机制,什么消息都会记忆,然后往后面传递,越到后面记忆的信息越少
lstm:通过门的机制,主要有输入门,输出门,遗忘门来进行信息的筛选,比如可以区别的对待记忆,记忆重要的信息,不重要的消息就被遗忘了,这样的信息是有价值的,对最终的输入也更加有影响
OK,理论知识说的差不多了,那么我们看看如何使用tf来实现的基于rnn模型的创建,尽管tf支持单纯的rnn和lstm,但是我们一般都直接使用lstm,这点是需要注意的
接下来还是以minist为例子来讲解
from tensorflow.examples.tutorials.mnist import input_data import tensorflow as tf import numpy as np #mnist数据存储的位置或待存储的位置,若该位置有数据则直接使用,否则下载 mnist = input_data.read_data_sets('MNIST_data', one_hot=True) #使用循环神经网络来识别手写字体 28*28 #学习 learning_rate = 0.001 #迭代次数 training_iters = 100000 #每次训练样本数量 batch_size = 128 #每迭代多少次开始显示基本信息 display_step = 10 #保持百分比 keep_prob =0.6 #输入层的数量 n_input = 28 #长度 n_steps = 28 tf使用的是BPTT机制-截短 并不是把所有的序列都进行计算 #隐含层的特征数量 n_hidden = 128 #输出的结果分类数量 n_classes = 10 #构建输入 x = tf.placeholder("float",[None,n_steps,n_input]) #构建状态 istate = tf.placeholder("float",[None,2 * n_hidden]) #构建输出 y = tf.placeholder("float",[None,n_classes]) #构建权重 weights ={ 'hidden_weight':tf.Variable(tf.random_normal([n_input,n_hidden])), 'out_weight':tf.Variable(tf.random_normal([n_hidden,n_classes])) } #构建biases biases ={ 'hidden_biases':tf.Variable(tf.random_normal([n_hidden])), 'out_biases': tf.Variable(tf.random_normal([n_classes])) } #构建rnn def rnn_model(_x,_isstate,_weight,_biases): _x = tf.transpose(_x,[1,0,2]) _x = tf.reshape(_x,[-1,n_input])# 维度的转换 #计算输入层到隐含层 直接计算 _x = tf.matmul(_x,_weight['hidden_weight'] + _biases['hidden_biases']) #切割维度 _x = tf.split(_x,n_steps,0) #构建lstm lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(n_hidden,forget_bias=1.0) #构建lstm的droppout lstm_cell_dropout = tf.nn.rnn_cell.DropoutWrapper(lstm_cell,output_keep_prob=keep_prob) #构建双向或者多层循环网络 # layer_num = 2 #要构建的层数 # mlstm_cell =tf.nn.rnn_cell.MultiRNNCell([lstm_cell]*layer_num,state_is_tuple=True) # init_state = mlstm_cell.zero_state(batch_size,tf.float32) # m_outpts,m_state = tf.nn.dynamic_rnn(mlstm_cell,_x,initial_state=init_state) # return m_outpts,m_state #计算rnn outputs ,state,_ = tf.nn.dynamic_rnn(lstm_cell_dropout,_x,initial_state=_isstate) #返回输出值 return tf.matmul(outputs[-1],_weight['out_weight']) + _biases['out_biases'] #计算预测值 y_pred = rnn_model(x,istate,weights,biases) loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y_pred,labels=y)) #学习率自动衰减 rate = tf.train.exponential_decay(1e-2, training_iters, decay_steps=mnist.train.num_examples/batch_size, decay_rate=0.98, staircase=True) optimizer = tf.train.AdamOptimizer(learning_rate=rate).minimize(loss) corr = tf.equal(tf.argmax(y_pred,1),tf.argmax(y,1)) accuracy = tf.cast(corr,tf.float32) init = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) step = 1 # Keep training until reach max iterations while step * batch_size < training_iters: batch_xs, batch_ys = mnist.train.next_batch(batch_size) # Reshape data to get 28 seq of 28 elements batch_xs = batch_xs.reshape((batch_size, n_steps, n_input)) # Fit training using batch data sess.run(optimizer, feed_dict={x: batch_xs, y: batch_ys,istate: np.zeros((batch_size, 2 * n_hidden))}) if step % display_step == 0: # Calculate batch accuracy acc = sess.run(accuracy, feed_dict={x: batch_xs, y: batch_ys,istate: np.zeros((batch_size, 2 * n_hidden))}) # Calculate batch loss loss = sess.run(loss, feed_dict={x: batch_xs, y: batch_ys,istate: np.zeros((batch_size, 2 * n_hidden))}) print( "Iter " + str(step * batch_size) + ", Minibatch Loss= " + "{:.6f}".format(loss) + \ ", Training Accuracy= " + "{:.5f}".format(acc)) step += 1 print( "Optimization Finished!") # Calculate accuracy for 256 mnist test images test_len = 256 test_data = mnist.test.images[:test_len].reshape((-1, n_steps, n_input)) test_label = mnist.test.labels[:test_len] print( "Testing Accuracy:", sess.run(accuracy, feed_dict={x: test_data, y: test_label,istate: np.zeros((test_len, 2 * n_hidden))}))
其实代码并不难,但是上面牵涉到一个新的知识点,就是学习比率这个值,我们知道这个值太大或者太小都不好,太大容易过早训练结束,
太小容易导致梯度消失,导致训练速度非常慢,所以tf中给我们实现了一个优化算法,那就是因子自动衰减,本质是根据指数来的.
这种方法设置它的值,往往比我们手动的指定一个值的效果要好很多.就是下面这段代码
rate = tf.train.exponential_decay(1e-2, training_iters, decay_steps=mnist.train.num_examples/batch_size, decay_rate=0.98, staircase=True)
在整个过程中我们要记住三个变量,因为网络整个过程就是围绕这三个值而来,
init_state:初始化状态都是为0
outputs:下一时刻的输出
h_state:下一个时刻状态
当然业界还有很多lstm的变体网络结构,比如有gru,双向rnn等
GRU网络
GRU可以看成是LSTM的变种,GRU把LSTM中的遗忘门和输入们用更新门来替代。 把cell state和隐状态ht进行合并,在计算当前时刻新信息的方法和LSTM有所不同。 下图是GRU更新ht的过程:
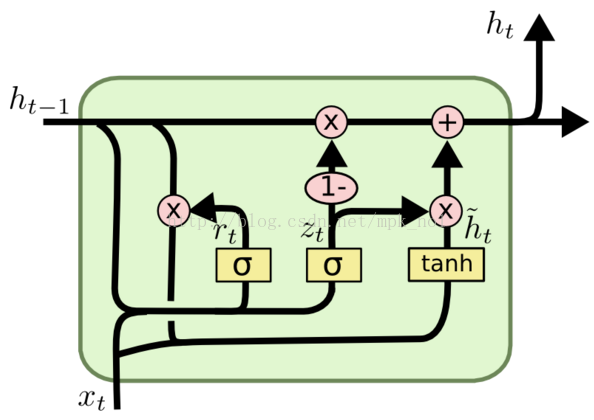
重置门:
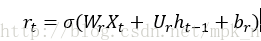
更新门:
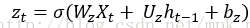
候选记忆单元:
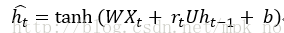
当前时刻记忆单元:
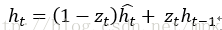
双向RNN
在经典的循环神经网络中,状态的传输是从前往后单向的。然而,在有些问题中,当前时刻的输出不仅和之前的状态有关系,也和之后的状态相关。这时就需要双向RNN(BiRNN)来解决这类问题。例如预测一个语句中缺失的单词不仅需要根据前文来判断,也需要根据后面的内容,这时双向RNN就可以发挥它的作用。
双向RNN是由两个RNN上下叠加在一起组成的。输出由这两个RNN的状态共同决定。
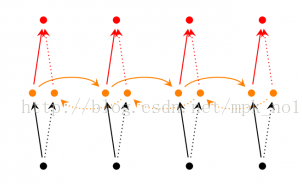
从上图可以看出,双向RNN的主题结构就是两个单向RNN的结合。在每一个时刻t,输入会同时提供给这两个方向相反的RNN,而输出则是由这两个单向RNN共同决定(可以拼接或者求和等)。
同样地,将双向RNN中的RNN替换成LSTM或者GRU结构,则组成了BiLSTM和BiGRU。