序列到序列网络
序列到序列网络(Sequence to Sequence network),也叫做seq2seq网络, 又或者是编码器解码器网络(Encoder Decoder network), 是一个由两个称为编码器解码器的RNN组成的模型。在这里进行介绍的作用是确定变量的名称,为接下来讲注意力机制做铺垫。
自编码器也是seq2seq模型中的一种。在自编码器中,解码器的工作是将编码器产生的向量还原成为原序列。经过压缩之后不可避免的会出现信息的损失,我们需要尽量将这种损失降低(方法是设置合理的中间向量大小和经过多次训练迭代的编码-解码器)。相关理论本身在这里讲得不是很清楚,有兴趣了解更多的同学可以移步数学专题中的信息论。
编码器
把一个不定长的输入序列变换成一个定长的背景变量 c c c,并在该背景变量中编码输入序列信息。编码器可以使用循环神经网络。
在时间步 t t t,循环神经网络将输入的特征向量 x t x_t xt和上个时间步的隐藏状态 h t − 1 h_{t−1} ht−1变换为当前时间步的隐藏状态 h t h_t ht。
h t = f ( x t , h t − 1 ) h_t = f(x_t, h_{t-1}) ht=f(xt,ht−1)
接下来,编码器通过自定义函数 q q q将各个时间步的隐藏状态变换为背景变量
c = q ( h 1 , . . . , h T ) c=q(h_1,...,h_T) c=q(h1,...,hT)
例如,我们可以将背景变量设置成为输入序列最终时间步的隐藏状态 h T h_T hT。
以上描述的编码器是一个单向的循环神经网络,每个时间步的隐藏状态只取决于该时间步及之前的输入子序列。我们也可以使用双向循环神经网络构造编码器。在这种情况下,编码器每个时间步的隐藏状态同时取决于该时间步之前和之后的子序列(包括当前时间步的输入),并编码了整个序列的信息。
解码器
对每个时间步 t ′ t′ t′,解码器输出 y t ′ y_{t′} yt′的条件概率将基于之前的输出序列 y 1 , . . . , y t ′ − 1 y_1,...,y_{t′−1} y1,...,yt′−1和背景变量 c c c(所有时间步共用),即 P ( y t ′ ∣ y 1 , . . . , y t ′ − 1 , c ) P(y_{t′}∣y_1,...,y_{t′−1},c) P(yt′∣y1,...,yt′−1,c)。同时还要考虑上一时间步的隐藏状态 s t ′ − 1 s_{t′−1} st′−1。
s t ′ = g ( y t ′ − 1 , c , s t ′ − 1 ) s_{t'} = g(y_{t′−1}, c, s_{t'-1}) st′=g(yt′−1,c,st′−1)
注意力机制
动机
普通的seq2seq模型到底有什么问题?我们再来回顾一下输出流程。
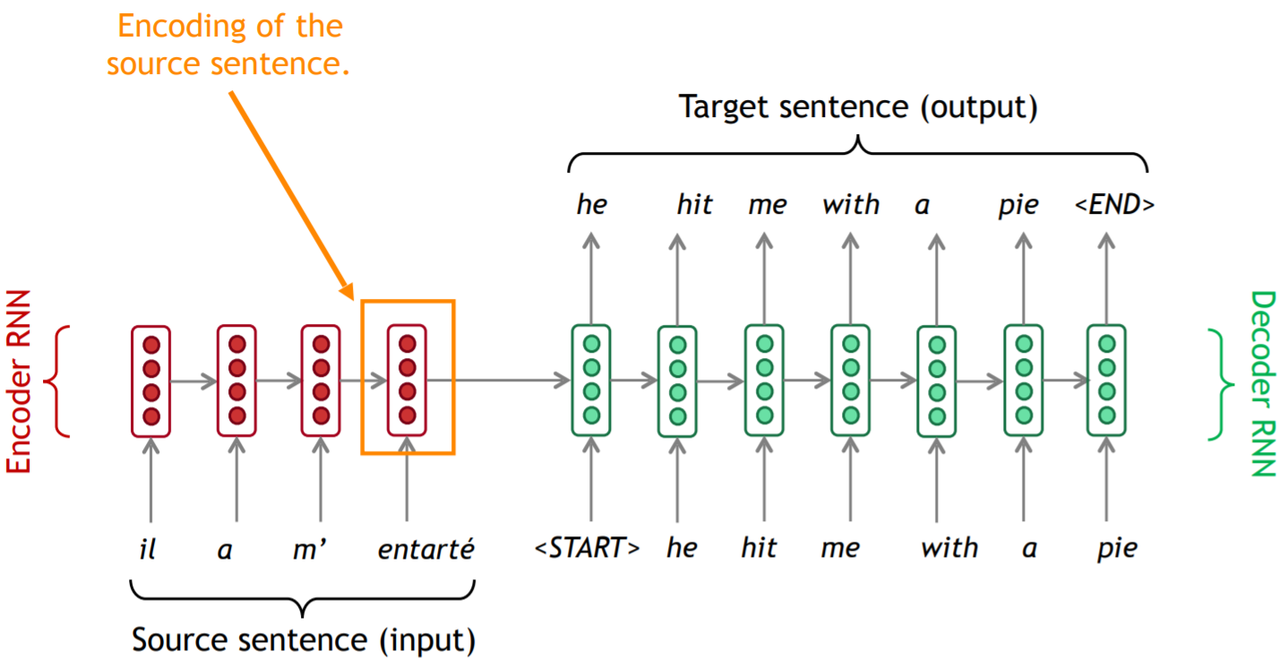
我们发现,解码器过分依赖于编码器在最后时间步生成的向量。这个向量需要包括源序列所有的信息,否则解码器将难以产生准确的输出。这个要求对于最后时间步生成的向量而言实在太高了。这个问题被称为信息瓶颈(information bottleneck)。
实际上,解码器在生成输出序列中的每一个词时可能只需利用输入序列某一部分的信息。为了让模型在不同时间步能够根据信息的有用程度分配权重,我们引入注意力机制。注意力机制的核心思想是解码器在每个时间步上使用直连接通向编码器以便其专注于源序列的部分内容。
过程
我们先通过图片形式展示过程。
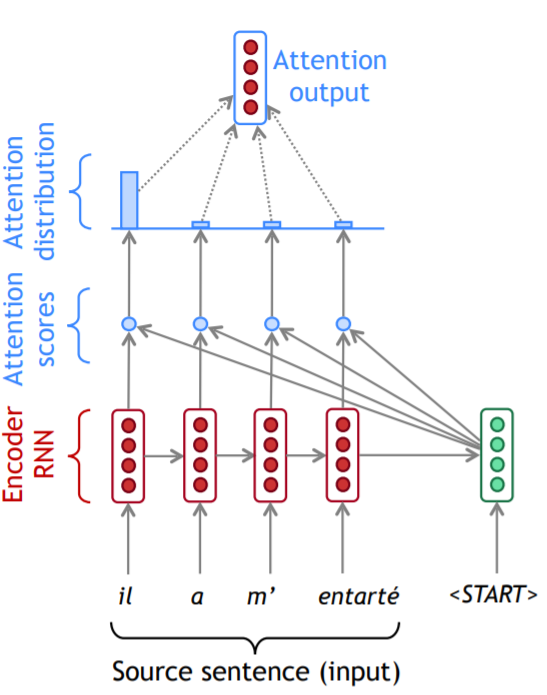
在注意力得分(attention scores)那个区域的小圆圈代表向量点乘,使用softmax函数将注意力得分转换成注意力分布(attention distribution)。我们可以看到,在第一步,大部分注意力被分配给了源序列的第一个单词。通过加权相加的方法得到了编码器的一个隐状态。将编码器产生的隐状态和解码器的隐状态进行叠加,就可以产生解码器在该时间步的输出。

有时,我们将注意力在上一步的输出当成输入,与当前的解码器隐状态一起进行训练,产生当前时间步的输出。例如这里的"he"就是上一步解码器的输出。
从另一个角度理解,对于普通的解码器,我们每一个时间步可以使用相同的背景变量。而在引入注意力机制之后,我们必须给每一个时间步不同的背景变量。
s t ′ = g ( y t ′ − 1 , c t ′ , s t ′ − 1 ) s_{t'} = g(y_{t′−1}, c_{t'}, s_{t'-1}) st′=g(yt′−1,ct′,st′−1)

我们用 h 1 , . . . , h N ∈ R h h_1, ..., h_N \in R^{h} h1,...,hN∈Rh来表示编码器的隐状态(hidden states),用 s t ′ ∈ R h s_{t'} \in R^{h} st′∈Rh来表示解码器在时间步 t ′ t' t′的隐状态。我们可以计算注意力得分(attention scores)
e t ′ = [ s t ′ T h i , . . . , s t ′ T h N ] ∈ R N e_{t'} = [s_{t'}^Th_i,...,s_{t'}^Th_N] \in R^N et′=[st′Thi,...,st′ThN]∈RN
使用softmax得到在时间步 t ′ t' t′的注意力分布(attention distribution)
α t ′ = s o f t m a x ( e t ′ ) ∈ R N \alpha_{t'} = softmax(e_{t'}) \in R^N αt′=softmax(et′)∈RN
利用分布计算加权总合得到注意力输出向量(attention output) a a a,有时候也叫做上下文向量(context vector) c c c,
a t ′ = c t ′ = ∑ i = 1 N α i , t ′ h i ∈ R h a_{t'} = c_{t'} = \sum_{i=1}^N \alpha_{i,t'}h_i \in R^{h} at′=ct′=i=1∑Nαi,t′hi∈Rh
最后,我们将该向量与解码器当前的隐状态进行拼接
[ a t ′ ; s t ′ ] ∈ R 2 h [a_{t'}; s_{t'}] \in R^{2h} [at′;st′]∈R2h
拓展
优点
- 解决了信息瓶颈的问题
- 缓解了梯度消失的问题
- 在一定程度上提供了可解释性
- 解决了软对齐问题(模型自己学习的,不需要人工调控)
注意力机制不光应用在机器翻译,还在很多其他领域有用武之地。
注意力机制的更通用的定义:给定一组值向量(values)和一个查询向量(query),注意力是一种根据查询向量对值向量计算加权和的技术。我们有时候会说查询关注这些值(query attends to the values)。例如,在seq2seq+attention模型中,每一个解码器的隐状态(query)都会关注所有编码器的隐状态(values)。
我们用 h 1 , . . . , h N ∈ R d 1 h_1, ..., h_N \in R^{d_1} h1,...,hN∈Rd1来表示values,用 s ∈ R d 2 s \in R^{d_2} s∈Rd2来表示query。注意力的计算过程如下:
- 计算注意力得分(attention scores), e ∈ R N e \in R^N e∈RN
- 进行softmax操作,将得分转换成注意力分布, α = s o f t m a x ( e ) ∈ R N \alpha = softmax(e) \in R^N α=softmax(e)∈RN
- 利用分布计算加权总合得到输出向量(attention output) a a a,有时候也叫做上下文向量(context vector), a = ∑ i = 1 N α i h i ∈ R d 1 a = \sum_{i=1}^N \alpha_ih_i \in R^{d_1} a=∑i=1Nαihi∈Rd1
计算注意力得分的方法
计算注意力得分的方式有很多种。
点乘注意力
英文是basic dot-product attention。使用前提是 d 1 = d 2 d_1 = d_2 d1=d2。
e i = s T h i e_i = s^Th_i ei=sThi
乘法注意力
英文是multiplicative attention。权重矩阵 W ∈ R d 2 ∗ d 1 W \in R^{d_2*d_1} W∈Rd2∗d1。
e i = s T W h i e_i = s^TWh_i ei=sTWhi
加法注意力
英文是additive attention。权重矩阵 W 1 ∈ R d 3 ∗ d 1 W_1 \in R^{d_3*d_1} W1∈Rd3∗d1, W 2 ∈ R d 2 ∗ d 1 W_2 \in R^{d_2*d_1} W2∈Rd2∗d1,权重向量 v ∈ R d 3 v \in R^{d_3} v∈Rd3。我们用 d 3 d_3 d3表示注意力维度(attention dimensionality),这是一个超参数。
e i = v T t a n h ( W 1 h i + W 2 s ) e_i = v^Ttanh(W_1h_i + W_2s) ei=vTtanh(W1hi+W2s)
矢量化计算
可以对注意力机制采用更高效的矢量化计算。我们再引入与值项一一对应的键项(key) K K K。
我们考虑编码器和解码器的隐藏单元个数均为 h h h的情况。假设我们希望根据解码器单个隐藏状态 s t ′ − 1 ∈ R h s_{t′−1} \in R^h st′−1∈Rh和编码器所有隐藏状态 [ h 1 , . . . , h N ] ∈ R h [h_1, ..., h_N] \in R^{h} [h1,...,hN]∈Rh来计算背景向量 c t ′ ∈ R h c_{t′} \in R^h ct′∈Rh。 我们可以将查询项矩阵 Q ∈ R 1 × h Q \in R^{1×h} Q∈R1×h设为 s t ′ − 1 T s_{t′−1}^T st′−1T,并令键项矩阵 K ∈ R T × h K \in R^{T×h} K∈RT×h和值项矩阵 V ∈ R T × h V \in R^{T×h} V∈RT×h相同且第 t t t行均为 h t T h_t^T htT。此时,我们只需要通过矢量化计算
s o f t m a x ( Q K T ) V softmax(QK^T)V softmax(QKT)V
即可算出转置后的背景向量 c t ′ T c_{t′}^T ct′T。当查询项矩阵 Q Q Q的行数为 n n n时,上式将得到 n n n行的输出矩阵。输出矩阵与查询项矩阵在相同行上一一对应。
Reference
-
Natural Language Processing with Deep Learning, Stanford CS244n, 2019 winter, Chris Manning