时间序列预测可以根据短期预测,长期预测,以及具体场景选用不同的方法,如ARMA、ARIMA、神经网络预测、SVM预测、灰色预测、模糊预测、组合预测法等等。所谓没有最好的模型,只有最适合的模型。至于哪一种模型能针对特定预测问题达到最高的精度,需要通过实验来证明。本文通过生成的随机数利用tensorflow的seq2seq模型进行单变量时间序列预测实验,目的是理解seq2seq的模型基础架构以及验证模型在非线性数据上的表达能力。这里暂时不考虑带Attention机制的模型,具体可以参考Neural Machine Translation By Jointly Learning to Align and Translate。
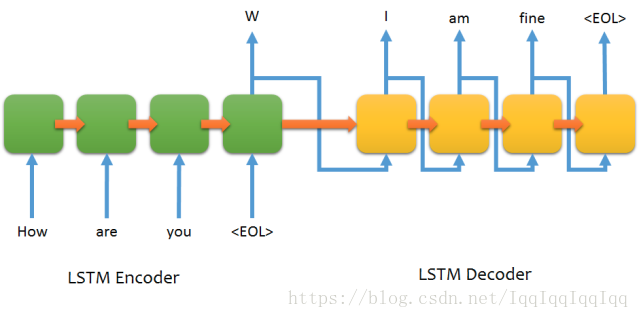
最基础的Seq2Seq模型包含了三个部分,即Encoder、Decoder以及连接两者的中间状态向量,Encoder通过学习输入,将其编码成一个固定大小的状态向量S,继而将S传给Decoder,Decoder再通过对状态向量S的学习来进行输出。下图是encoder与decoder均基于LSTM的模型。
首先我们导入需要的包:
import tensorflow as tf
import numpy as np
import random
import math
from matplotlib import pyplot as plt
import os
import copy1.数据准备
首先,我们生成一系列没有噪音的样本:
x = np.linspace(0, 30, 105)
y = 2 * np.sin(x)
l1, = plt.plot(x[:85], y[:85], 'y', label = 'training samples')
l2, = plt.plot(x[85:], y[85:105], 'c--', label = 'test samples')
plt.legend(handles = [l1, l2], loc = 'upper left')
plt.show()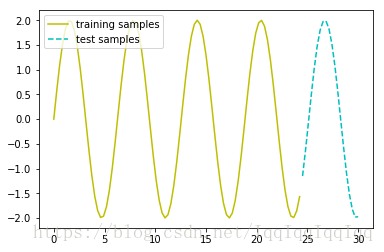
为了模拟真实世界的数据,我们添加一些随机噪音:
train_y = y.copy()
noise_factor = 0.5
train_y += np.random.randn(105) * noise_factor
l1, = plt.plot(x[:85], train_y[:85], 'yo', label = 'training samples')
plt.plot(x[:85], y[:85], 'y:')
l2, = plt.plot(x[85:], train_y[85:], 'co', label = 'test samples')
plt.plot(x[85:], y[85:], 'c:')
plt.legend(handles = [l1, l2], loc = 'upper left')
plt.show()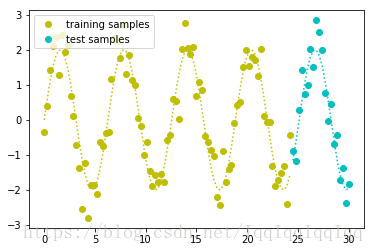
然后,我们设置输入输出的序列长度,并生成训练样本和测试样本:
input_seq_len = 15
output_seq_len = 20
x = np.linspace(0, 30, 105)
train_data_x = x[:85]
def true_signal(x):
y = 2 * np.sin(x)
return y
def noise_func(x, noise_factor = 1):
return np.random.randn(len(x)) * noise_factor
def generate_y_values(x):
return true_signal(x) + noise_func(x)
def generate_train_samples(x = train_data_x, batch_size = 10, input_seq_len = input_seq_len, output_seq_len = output_seq_len):
total_start_points = len(x) - input_seq_len - output_seq_len
start_x_idx = np.random.choice(range(total_start_points), batch_size)
input_seq_x = [x[i:(i+input_seq_len)] for i in start_x_idx]
output_seq_x = [x[(i+input_seq_len):(i+input_seq_len+output_seq_len)] for i in start_x_idx]
input_seq_y = [generate_y_values(x) for x in input_seq_x]
output_seq_y = [generate_y_values(x) for x in output_seq_x]
#batch_x = np.array([[true_signal()]])
return np.array(input_seq_y), np.array(output_seq_y)input_seq, output_seq = generate_train_samples(batch_size=10)
对含有噪音的数据进行可视化:
results = []
for i in range(100):
temp = generate_y_values(x)
results.append(temp)
results = np.array(results)
for i in range(100):
l1, = plt.plot(results[i].reshape(105, -1), 'co', lw = 0.1, alpha = 0.05, label = 'noisy training data')
l2, = plt.plot(true_signal(x), 'm', label = 'hidden true signal')
plt.legend(handles = [l1, l2], loc = 'lower left')
plt.show()
2.建立基本的RNN模型
2.1参数设置
## Parameters
learning_rate = 0.01
lambda_l2_reg = 0.003
## Network Parameters
# length of input signals
input_seq_len = 15
# length of output signals
output_seq_len = 20
# size of LSTM Cell
hidden_dim = 64
# num of input signals
input_dim = 1
# num of output signals
output_dim = 1
# num of stacked lstm layers
num_stacked_layers = 2
# gradient clipping - to avoid gradient exploding
GRADIENT_CLIPPING = 2.5 2.2 模型架构
这里的seq2seq模型基本与tensorflow在github中提供的模型一致。
def build_graph(feed_previous = False):
tf.reset_default_graph()
global_step = tf.Variable(
initial_value=0,
name="global_step",
trainable=False,
collections=[tf.GraphKeys.GLOBAL_STEP, tf.GraphKeys.GLOBAL_VARIABLES])
weights = {
'out': tf.get_variable('Weights_out', \
shape = [hidden_dim, output_dim], \
dtype = tf.float32, \
initializer = tf.truncated_normal_initializer()),
}
biases = {
'out': tf.get_variable('Biases_out', \
shape = [output_dim], \
dtype = tf.float32, \
initializer = tf.constant_initializer(0.)),
}
with tf.variable_scope('Seq2seq'):
# Encoder: inputs
enc_inp = [
tf.placeholder(tf.float32, shape=(None, input_dim), name="inp_{}".format(t))
for t in range(input_seq_len)
]
# Decoder: target outputs
target_seq = [
tf.placeholder(tf.float32, shape=(None, output_dim), name="y".format(t))
for t in range(output_seq_len)
]
# Give a "GO" token to the decoder.
# If dec_inp are fed into decoder as inputs, this is 'guided' training; otherwise only the
# first element will be fed as decoder input which is then 'un-guided'
dec_inp = [ tf.zeros_like(target_seq[0], dtype=tf.float32, name="GO") ] + target_seq[:-1]
with tf.variable_scope('LSTMCell'):
cells = []
for i in range(num_stacked_layers):
with tf.variable_scope('RNN_{}'.format(i)):
cells.append(tf.contrib.rnn.LSTMCell(hidden_dim))
cell = tf.contrib.rnn.MultiRNNCell(cells)
def _rnn_decoder(decoder_inputs,
initial_state,
cell,
loop_function=None,
scope=None):
"""RNN decoder for the sequence-to-sequence model.
Args:
decoder_inputs: A list of 2D Tensors [batch_size x input_size].
initial_state: 2D Tensor with shape [batch_size x cell.state_size].
cell: rnn_cell.RNNCell defining the cell function and size.
loop_function: If not None, this function will be applied to the i-th output
in order to generate the i+1-st input, and decoder_inputs will be ignored,
except for the first element ("GO" symbol). This can be used for decoding,
but also for training to emulate http://arxiv.org/abs/1506.03099.
Signature -- loop_function(prev, i) = next
* prev is a 2D Tensor of shape [batch_size x output_size],
* i is an integer, the step number (when advanced control is needed),
* next is a 2D Tensor of shape [batch_size x input_size].
scope: VariableScope for the created subgraph; defaults to "rnn_decoder".
Returns:
A tuple of the form (outputs, state), where:
outputs: A list of the same length as decoder_inputs of 2D Tensors with
shape [batch_size x output_size] containing generated outputs.
state: The state of each cell at the final time-step.
It is a 2D Tensor of shape [batch_size x cell.state_size].
(Note that in some cases, like basic RNN cell or GRU cell, outputs and
states can be the same. They are different for LSTM cells though.)
"""
with variable_scope.variable_scope(scope or "rnn_decoder"):
state = initial_state
outputs = []
prev = None
for i, inp in enumerate(decoder_inputs):
if loop_function is not None and prev is not None:
with variable_scope.variable_scope("loop_function", reuse=True):
inp = loop_function(prev, i)
if i > 0:
variable_scope.get_variable_scope().reuse_variables()
output, state = cell(inp, state)
outputs.append(output)
if loop_function is not None:
prev = output
return outputs, state
def _basic_rnn_seq2seq(encoder_inputs,
decoder_inputs,
cell,
feed_previous,
dtype=dtypes.float32,
scope=None):
"""Basic RNN sequence-to-sequence model.
This model first runs an RNN to encode encoder_inputs into a state vector,
then runs decoder, initialized with the last encoder state, on decoder_inputs.
Encoder and decoder use the same RNN cell type, but don't share parameters.
Args:
encoder_inputs: A list of 2D Tensors [batch_size x input_size].
decoder_inputs: A list of 2D Tensors [batch_size x input_size].
feed_previous: Boolean; if True, only the first of decoder_inputs will be
used (the "GO" symbol), all other inputs will be generated by the previous
decoder output using _loop_function below. If False, decoder_inputs are used
as given (the standard decoder case).
dtype: The dtype of the initial state of the RNN cell (default: tf.float32).
scope: VariableScope for the created subgraph; default: "basic_rnn_seq2seq".
Returns:
A tuple of the form (outputs, state), where:
outputs: A list of the same length as decoder_inputs of 2D Tensors with
shape [batch_size x output_size] containing the generated outputs.
state: The state of each decoder cell in the final time-step.
It is a 2D Tensor of shape [batch_size x cell.state_size].
"""
with variable_scope.variable_scope(scope or "basic_rnn_seq2seq"):
enc_cell = copy.deepcopy(cell)
_, enc_state = rnn.static_rnn(enc_cell, encoder_inputs, dtype=dtype)
if feed_previous:
return _rnn_decoder(decoder_inputs, enc_state, cell, _loop_function)
else:
return _rnn_decoder(decoder_inputs, enc_state, cell)
def _loop_function(prev, _):
'''Naive implementation of loop function for _rnn_decoder. Transform prev from
dimension [batch_size x hidden_dim] to [batch_size x output_dim], which will be
used as decoder input of next time step '''
return tf.matmul(prev, weights['out']) + biases['out']
dec_outputs, dec_memory = _basic_rnn_seq2seq(
enc_inp,
dec_inp,
cell,
feed_previous = feed_previous
)
reshaped_outputs = [tf.matmul(i, weights['out']) + biases['out'] for i in dec_outputs]
# Training loss and optimizer
with tf.variable_scope('Loss'):
# L2 loss
output_loss = 0
for _y, _Y in zip(reshaped_outputs, target_seq):
output_loss += tf.reduce_mean(tf.pow(_y - _Y, 2))
# L2 regularization for weights and biases
reg_loss = 0
for tf_var in tf.trainable_variables():
if 'Biases_' in tf_var.name or 'Weights_' in tf_var.name:
reg_loss += tf.reduce_mean(tf.nn.l2_loss(tf_var))
loss = output_loss + lambda_l2_reg * reg_loss
with tf.variable_scope('Optimizer'):
optimizer = tf.contrib.layers.optimize_loss(
loss=loss,
learning_rate=learning_rate,
global_step=global_step,
optimizer='Adam',
clip_gradients=GRADIENT_CLIPPING)
saver = tf.train.Saver
return dict(
enc_inp = enc_inp,
target_seq = target_seq,
train_op = optimizer,
loss=loss,
saver = saver,
reshaped_outputs = reshaped_outputs,
)2.3模型训练
在这里设置了batch size为16,迭代次数为100。
total_iteractions = 100
batch_size = 16
KEEP_RATE = 0.5
train_losses = []
val_losses = []
x = np.linspace(0, 30, 105)
train_data_x = x[:85]
rnn_model = build_graph(feed_previous=False)
saver = tf.train.Saver()
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(total_iteractions):
batch_input, batch_output = generate_train_samples(batch_size=batch_size)
feed_dict = {rnn_model['enc_inp'][t]: batch_input[:,t].reshape(-1,input_dim) for t in range(input_seq_len)}
feed_dict.update({rnn_model['target_seq'][t]: batch_output[:,t].reshape(-1,output_dim) for t in range(output_seq_len)})
_, loss_t = sess.run([rnn_model['train_op'], rnn_model['loss']], feed_dict)
print(loss_t)
temp_saver = rnn_model['saver']()
save_path = temp_saver.save(sess, os.path.join('./', 'univariate_ts_model0'))
print("Checkpoint saved at: ", save_path)可见输出的loss呈降低的趋势:
57.3053
32.0934
52.935
37.3215
37.121
36.0812
24.0727
27.5016
27.8621
29.2104
25.2804
26.4493
24.8914
26.5799
24.9871
22.0373
24.2079
23.1084
24.7991
24.0452
25.4788
23.0237
22.9508
25.1181
27.6942
20.5367
21.2899
28.4336
21.9943
21.8568
26.5138
22.5602
21.1466
22.0203
25.0466
21.0588
23.0585
22.5311
26.1076
21.897
20.694
21.459
21.1082
20.9176
21.8146
21.0299
22.3609
20.4057
21.0788
23.2162
24.8537
22.1202
20.7458
22.5411
21.4423
23.8266
23.3528
22.5934
20.2631
21.4907
19.6011
20.5983
23.4366
25.6377
23.4134
20.6773
18.802
25.341
22.935
21.8413
22.1599
23.4422
24.0427
22.8963
22.336
20.397
22.0162
21.2389
20.5336
21.0605
22.8863
22.3839
22.1059
22.0032
20.505
23.4216
26.9626
22.8875
21.9535
22.4898
20.1734
19.936
19.7218
22.7191
20.2067
19.4964
24.0207
21.0039
22.38
20.1875
Checkpoint saved at: ./univariate_ts_model03.预测
我们将模型用在测试集中进行预测
test_seq_input = true_signal(train_data_x[-15:])
rnn_model = build_graph(feed_previous=True)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
saver = rnn_model['saver']().restore(sess, os.path.join('./', 'univariate_ts_model0'))
feed_dict = {rnn_model['enc_inp'][t]: test_seq_input[t].reshape(1,1) for t in range(input_seq_len)}
feed_dict.update({rnn_model['target_seq'][t]: np.zeros([1, output_dim]) for t in range(output_seq_len)})
final_preds = sess.run(rnn_model['reshaped_outputs'], feed_dict)
final_preds = np.concatenate(final_preds, axis = 1)得到的预测效果如下:
l1, = plt.plot(range(85), true_signal(train_data_x[:85]), label = 'Training truth')
l2, = plt.plot(range(85, 105), y[85:], 'yo', label = 'Test truth')
l3, = plt.plot(range(85, 105), final_preds.reshape(-1), 'ro', label = 'Test predictions')
plt.legend(handles = [l1, l2, l3], loc = 'lower left')
plt.show()
references:
https://weiminwang.blog/2017/09/29/multivariate-time-series-forecast-using-seq2seq-in-tensorflow/
http://baijiahao.baidu.com/s?id=1571869641858839&wfr=spider&for=pc
https://blog.csdn.net/leadai/article/details/78809788
https://www.zhihu.com/question/21229371
https://blog.csdn.net/thriving_fcl/article/details/74853556