文本聚类,是一个无监督学习里面非常重要的课题,无论是在风控还是在其他业务中,通过对大规模文本数据的分析,找出里面的聚集观点,有助于发现新的问题或者重点问题。
通过对评论文本的分析,我们可以发现消费者关注的产品或服务痛点
通过对店铺商品标题的文本聚类,可以知道店铺主要集中卖什么类型的商品
通过对来电语音转文本聚类,可以知道公司售后业务的典型问题或者新问题的爆发
... ...
通过对新闻文本的聚类,可以知道大家最近都在讨论什么主题
通过对昵称聚类,可以发现批量注册用户团伙
文本聚类方法非常多,我们今天讨论DBSCAN,也是一个非常经典的算法,我们上期讲过的算法,本文本进行简短的回顾,并用一个评价数据的聚类,来进行实战应用,下面就是发现的一个簇的文本。
好像不卫生吃了拉肚子,口感不好。
味道不行 吃了拉肚子
别买 不卫生吃了拉肚子
菜品不新鲜,吃了拉肚子
鸭脚变味了,吃了拉肚子
吃了拉肚子 有点不新鲜了
就是不知道怎么回事我吃了拉肚子
一、算法概述
DBSCAN是一个出现得比较早(1996年),比较有代表性的基于密度的聚类算法,DBSCAN是英文Density-Based Spatial Clustering of Applications with Noise 的缩写,意思为:一种基于密度,同时对于有噪声(即孤立点或异常值)的数据集也有很好的鲁棒的空间聚类算法。DBSCAN将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
在聚类问题中,如果数据集的各类呈球形分布,可以采用kmeans聚类算法,如果各类数据呈非球形分布(如太极图、笑脸图等),采用kmeans算法效果将大打折扣,这种情况使用DBSCAN聚类算法更为合适,如下图所示,我们的文本聚类,恰好是一些不标准的分布,且事先不确定类别数量,因此用这个算法也是很合适的。

二、 基本概念
DBSCAN的基本概念可以用1个思想,2个参数,3种类别,4种关系来总结。
1、1个核心思想
该算法最核心的思想就是基于密度,直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。
可以简单的理解该算法是基于密度的一种生长,和病毒的传染差不多,只要密度够大,就能传染过去,遇到密度小的,就停止传染,如下图所示。
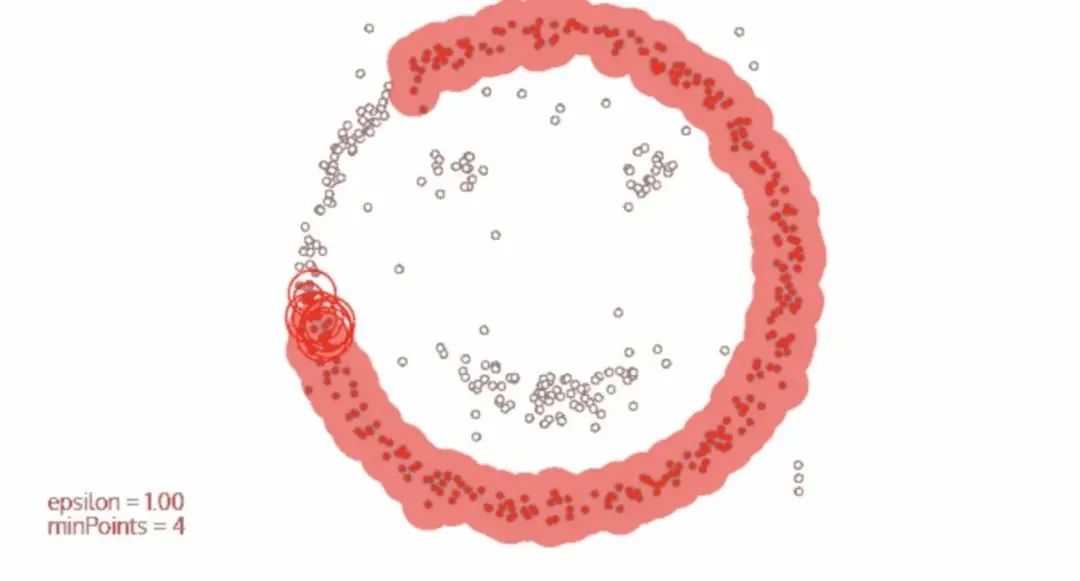
可视化的网站:https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
2、2个算法参数,邻域半径R、最少点数目MinPoints
这两个算法参数实际可以刻画什么叫密集:当邻域半径R内的点的个数大于最少点数目R时,就是密集。
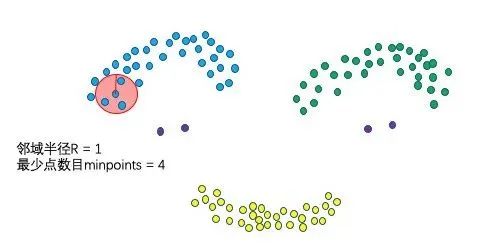
这两个参数恰好对应sklearn.cluster.DBSCAN算法中的两个参数为:min_samples 和 eps:eps表示数据点的邻域半径,如果某个数据点的邻域内至少有min_sample个数据点,则将该数据点看作为核心点,如果某个核心点的邻域内有其他核心点,则将它们看作属于同一个簇。如果将eps设置得非常小,则有可能没有点成为核心点,并且可能导致所有点都被标记为噪声。如果将eps设置为非常大,则将导致所有点都被划分到同一个簇。如果min_samples设置地太大,那么意味着更少的点会成为核心点,而更多的点将被标记为噪声。如下所示,指定半径r的点内有满足条件的个点,则可以认为该区域密集
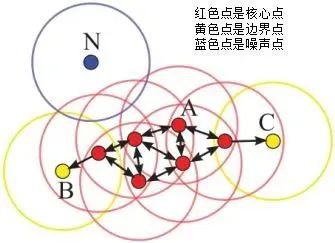
3、3种点的类别,核心点、边界点、噪声点
我们可以简单理解:邻域半径R内样本点的数量大于等于minpoints的点叫做核心点,不属于核心点但在某个核心点的邻域内的点叫做边界点,既不是核心点也不是边界点的是噪声点。
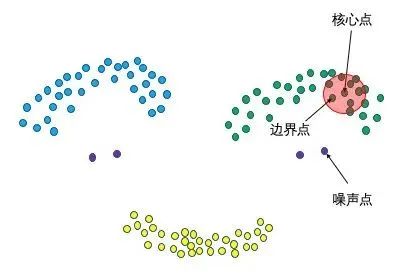
我们可以看看,更具体的定义如下:
核心点:对某一数据集D,若样本p的![]() -领域内至少包含MinPts个样本(包括样本p),那么样本p称核心点。
-领域内至少包含MinPts个样本(包括样本p),那么样本p称核心点。
即:
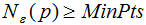
称p为核心点,其中![]() -领域
-领域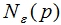 的表达式为:
的表达式为:
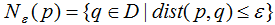
边界点:对于非核心点的样本b,若b在任意核心点p的![]() -领域内,那么样本b称为边界点。
-领域内,那么样本b称为边界点。
即:

称b为边界点。
噪声点:对于非核心点的样本n,若n不在任意核心点p的![]() -领域内,那么样本n称为噪声点。
-领域内,那么样本n称为噪声点。
即:

称n为噪声点。
假设MinPts=4,如下图的核心点、非核心点与噪声的分布:
4、4种点的关系,密度直达、密度可达、密度相连、非密度相连。
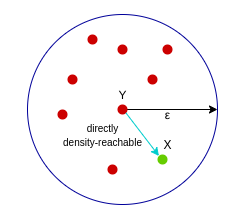
密度直达:样本X在核心样本Y的邻域内,则称Y到X是密度直达的,注意这个关系是单向的,反向不一定成立
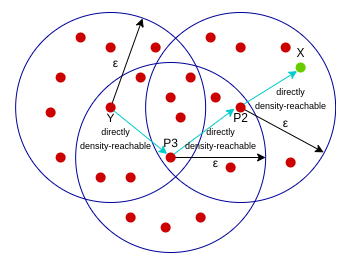
密度可达:核心样本Y到核心样本P3是密度直达的,核心样本P3到核心样本P2是密度直达的,核心样本P2到样本X是密度直达的,像这种通过P3和P2的中转,在样本Y到样本X建立的关系叫做密度可达。
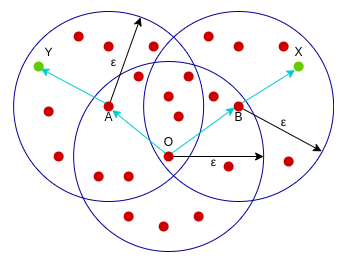
密度相连:核心样本O到样本Y是密度可达的,同时核心样本O到样本X是密度可达的,这样的关系,我们可以说样本X和样本Y是密度相连的。
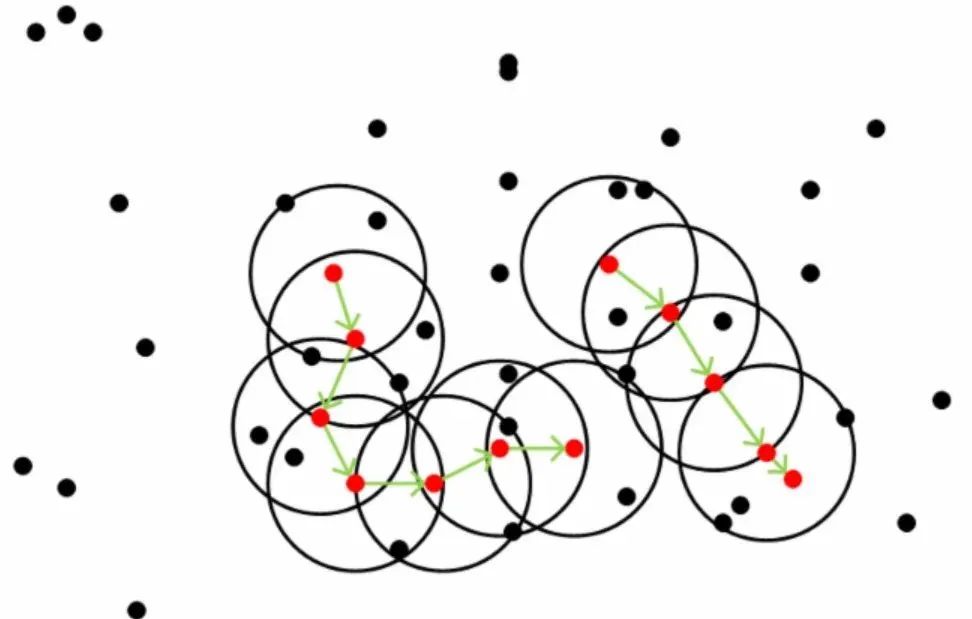
对于一系列密度可达的点而言,其邻域范围内的点都是密度相连的,下图所示是一个minPoints为5的领域,红色点为core ponit, 绿色箭头连接起来的则是密度可达的样本集合,在这些样本点的邻域内的点构成了一个密度相连的样本集合,这些样本就属于同一个cluster
三、算法思想
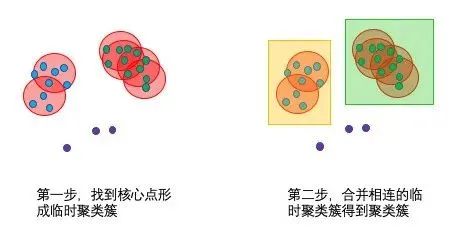
DBSCAN的算法步骤比较简单,主要分成两步。
1、寻找核心点形成临时聚类簇
扫描全部样本点,如果某个样本点R半径范围内点数目>=MinPoints,则将其纳入核心点列表,并将其密度直达的点形成对应的临时聚类簇。
2、合并临时聚类簇得到聚类簇
对于每一个临时聚类簇,检查其中的点是否为核心点,如果是,将该点对应的临时聚类簇和当前临时聚类簇合并,得到新的临时聚类簇。
重复此操作,直到当前临时聚类簇中的每一个点要么不在核心点列表,要么其密度直达的点都已经在该临时聚类簇,该临时聚类簇升级成为聚类簇。
继续对剩余的临时聚类簇进行相同的合并操作,直到全部临时聚类簇被处理。反复寻找这些核心点直接密度可达或密度可达的点,将其加入到相应的类,对于核心点发生密度可达状况的类,给予合并(组建好各个家庭后,如果家庭中长辈之间有亲戚关系,则把家庭合并为一个大家族)
四、sklearn算法介绍
https://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html
1、基本用法
sklearn.cluster.DBSCAN(eps=0.5, *,
min_samples=5,
metric='euclidean',
metric_params=None,
algorithm='auto',
leaf_size=30,
p=None,
n_jobs=None
)2、核心参数
eps: float,ϵ-邻域的距离阈值
min_samples:int,样本点要成为核心对象所需要的 ϵ-邻域的样本数阈值
3、其他参数
metric:度量方式,默认为欧式距离,可以使用的距离度量参数有:
-
欧式距离 “euclidean”
曼哈顿距离 “manhattan”
切比雪夫距离“chebyshev”
闵可夫斯基距离 “minkowski”
带权重闵可夫斯基距离 “wminkowski”
标准化欧式距离 “seuclidean”
马氏距离“mahalanobis”
自己定义距离函数
algorithm:近邻算法求解方式,有四种:
-
“brute”蛮力实现
“kd_tree” KD树实现
“ball_tree”球树实现
“auto”上面三种算法中做权衡,选择一个拟合最好的最优算法。
leaf_size:使用“ball_tree”或“kd_tree”时,停止建子树的叶子节点数量的阈值
p:只用于闵可夫斯基距离和带权重闵可夫斯基距离中p值的选择,p=1为曼哈顿距离, p=2为欧式距离。如果使用默认的欧式距离不需要管这个参数。
n_jobs:CPU并行数,若值为 -1,则用所有的CPU进行运算
4、属性
core_sample_indices_: 核心点的索引,因为labels_不能区分核心点还是边界点,所以需要用这个索引确定核心点
components_:训练样本的核心点
labels_:每个点所属集群的标签,也就是聚类的编号,-1代表噪声点
5、算法案例
from sklearn.cluster import DBSCAN
import numpy as np
X = np.array([[1, 2], [2, 2], [2, 3],
[8, 7], [8, 8], [25, 80]])
clustering = DBSCAN(eps=3, min_samples=2).fit(X)
clustering.labels_
array([ 0, 0, 0, 1, 1, -1])0,,0,,0:表示前三个样本被分为了一个群
1, 1:中间两个被分为一个群
-1:最后一个为异常点,不属于任何一个群
五、文本聚类实战
数据简介:O2O商铺食品安全相关评论发现
数据地址:https://tianchi.aliyun.com/dataset/dataDetail?dataId=129832
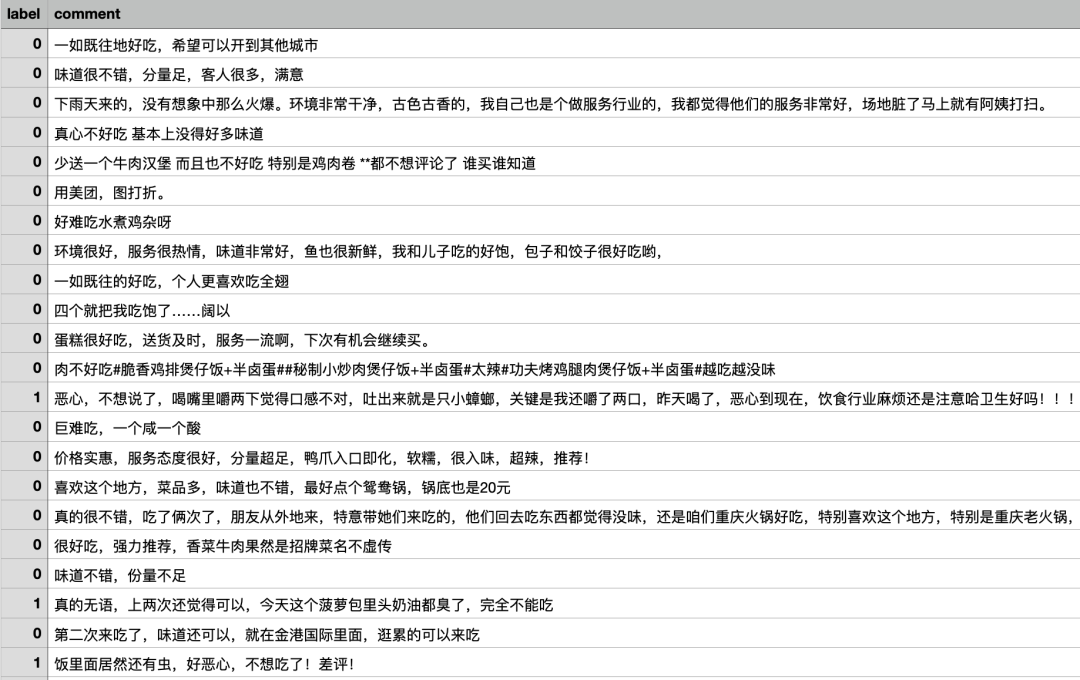
部分数据内容:
1、基础数据的读取
读取基础数据
# 加载所需要的包
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
import os
import jieba
# 设置工作空间 & 读取数据
os.chdir('/Users/wuzhengxiang/Documents/DataSets/评价数据')
train = pd.read_csv('train.csv',sep='\t')
# 查看数据大小和形状
train.shape
(10000, 2)
# 查看下前10条数据
train.head(10)
Out[2]:
label comment
0 0 一如既往地好吃,希望可以开到其他城市
1 0 味道很不错,分量足,客人很多,满意
2 0 下雨天来的,没有想象中那么火爆。环境非常干净,古色古香的,我自己也是个做服务行业的,我都觉得...
3 0 真心不好吃 基本上没得好多味道
4 0 少送一个牛肉汉堡 而且也不好吃 特别是鸡肉卷 **都不想评论了 谁买谁知道
5 0 用美团,图打折。
6 0 好难吃水煮鸡杂呀
7 0 环境很好,服务很热情,味道非常好,鱼也很新鲜,我和儿子吃的好饱,包子和饺子很好吃哟,
8 0 一如既往的好吃,个人更喜欢吃全翅
9 0 四个就把我吃饱了……阔以2、文本向量化
用结巴分词进行分词,并将文本转换成向量,我们这里用的tf-idf 转化,用到了2元的ngram,可以提高文本聚类的稳定性。
#进行分字处理 用结巴分词
data = train['comment'].apply(lambda x:' '.join(jieba.lcut(x)) )
# 看看前几条分词的结果
for i in data.head():
print(i)
一如既往 地 好吃 , 希望 可以 开 到 其他 城市
味道 很 不错 , 分量 足 , 客人 很多 , 满意
下雨天 来 的 , 没有 想象 中 那么 火爆 。环境 非常 干净 , 古色古香 的 , 我 自己 也 是 个 做 服务行业 的 , 我 都 觉得 他们 的 服务 非常 好 , 场地 脏 了 马上 就 有 阿姨 打扫 。
真心 不 好吃 基本上 没 得 好多 味道
少送 一个 牛肉 汉堡 而且 也 不 好吃 特别 是 鸡肉 卷 * * 都 不想 评论 了 谁 买 谁 知道
# 进行向量转化
vectorizer_word = TfidfVectorizer(max_features=800000,
token_pattern=r"(?u)\b\w+\b",
min_df = 5,
#max_df=0.1,
analyzer='word',
ngram_range=(1,2)
)
vectorizer_word = vectorizer_word.fit(data)
tfidf_matrix = vectorizer_word.transform(data)
#查看词典的大小
len(vectorizer_word.vocabulary_)
6968
#查看词典里面的词-部分词语
vectorizer_word.vocabulary_
{...
'骗人 的': 6878,
'的 可能': 4971,
'我点 了': 3629,
'煮 了': 4706,
'了 只有': 886,
'一个 人': 92,
'人 都': 1078,
'不够 吃': 378,
'点餐 的': 4648,
'的 朋友': 5068,
'他们 家': 1134,
'蛋炒饭': 5878,
'银耳汤': 6677,
'好吃 实惠': 2725,
'里面 还有': 6645,
'还有 免费': 6328,
'免费 的': 1371,
...}3、DBSCAN训练
有了词向量,我们进行聚类模型的训练,DBSCAN主要的两个参数,我们可以进行调整,获取不同的聚类效果。
# 设置下最大可展示的行
pd.set_option('display.max_rows', 1000)
# 进行模型训练
from sklearn.cluster import DBSCAN
clustering = DBSCAN(eps=0.95, min_samples=5).fit(tfidf_matrix)
# 我们看看分了所少个群,每个群的样本数是多少
len(pd.Series(clustering.labels_).value_counts())
42
pd.Series(clustering.labels_).value_counts()
-1 9008
0 631
5 28
8 27
6 23
14 19
7 16
...
28 10
1 10
12 10
3 9
29 84、聚类结果分析
有了分群的结果,我们看看数据准不准,这个群,一看都是吃拉肚子的,我们可以通过这个数据,看看有没有聚集性,如果都是评价的一个商家,那这个商家可能存在严重的食品安全问题,如果是一个消费者或者一群有关系的消费者,那么这个可能是恶意差评,专门靠这一类评价敲诈商家,因此,有了大规模的这种文本挖掘,我们可以发现平台很多隐藏的问题,作为感知或者原因归因,都是非常好的算法。
# 分群标签打进原来的数据
train['labels_'] = clustering.labels_
# 抽取编号为5的群看看 可以看到,这个群都是吃拉肚子的反馈,聚类效果还是非常可以的
for i in train[train['labels_']==5]['comment']:
print(i)
吃了拉肚子。一点当地重庆味道都没有
吃了拉肚子 弄得不卫生
吃了拉肚子 特别不卫生
吃了拉肚子,确实卫生不好
我吃了拉肚子mmp
吃了拉肚子
不干净,吃了拉肚子,还发烧了
老样子,吃了拉肚子
鱼不新鲜,吃了拉肚子……
吃了拉肚子,一上午都在医院
好像拉肚子了拉肚子
太辣,吃了拉肚子
吃了拉肚子,现在都十二点多了,还疼的睡不着。
我吃了拉肚子……
吃了拉肚子。不是正宗湖北油闷味道。。。
不新鲜,吃了拉肚子
泡椒猪肝吃了拉肚子
吃了拉肚子,快要拉死人了。
好像不卫生吃了拉肚子,口感不好。
味道不行 吃了拉肚子
别买 不卫生吃了拉肚子
菜品不新鲜,吃了拉肚子
鸭脚变味了,吃了拉肚子
吃了拉肚子 有点不新鲜了
就是不知道怎么回事我吃了拉肚子
吃了拉肚子,味道怪怪的
吃了拉肚子!拉肚子!
吃了拉肚子,真蛋疼我们再多抽几个群看看,下面这个是比较好评的
# 抽取编号为5的群看看 可以看到,这个群都是好评的
for i in train[train['labels_']==5]['comment']:
print(i)
上菜快,味道不错
环境还不错,上菜速度快,服务态度好
环境好,上菜速度快,味道特别好吃,去吃了很多次了
菜品很不错,上菜速度快,环境不错
便宜,味道好,上菜快,环境好,
菜品丰富不错,环境好,上菜速度快。
还不错,上菜速度快,口味也合适,可以试一试,经常去
味道好 上菜速度快 环境也不错
口味不错,上菜速度快,推荐品尝
菜品新鲜,味道不错,上菜速度快。
经常去,味道不错,上菜速度快。
服务很好,上菜速度快。味道不错。
环境很好,上菜速度快。下次还来。
很好,速度快,环境也不错,,,我们看看这个14群,里面的描述关键词 肉是臭的,作为一个平台运营者,通过这种评价聚类,就可以找出这种用坏肉的商家,进行一定的处罚,提高消费者体验。
train['labels_'] = clustering.labels_
for i in train[train['labels_']==14]['comment']:
print(i)
排骨汤都是臭的。
难吃,肉是臭的!!!!!!!
肉是臭的还卖无语了
海南小台农芒 500g 打开一个居然是臭的
肉是臭的,吃得一嘴恶心!
为什么我总感觉肉是臭的 拿给狗狗吃了 不敢吃
难吃,牛肉是臭的
nbsp;卤蛋是臭的!!!!
肉是臭的,失望透顶
今天的肉是臭的,不好吃鱼香肉丝木桶饭#
肉是臭的就算了,平菇也是臭的,以后不会再点了
肉是臭的 就这样做生意?
肉是坏的,不好吃
肉是臭的,我吃了一口,全吐了
难吃 肉是臭的。
鸡肉竟然是臭的!!!!
肉是臭的。不好吃。
味道还可以!但是!鸡肉居然是臭的!是臭的!
猪脚都是臭的。在找几个看看,有钢丝球系列,也要复购N次的
train['labels_'] = clustering.labels_
for i in train[train['labels_']==16]['comment']:
print(i)
饭里面居然有钢丝球的钢丝
肉里面居然有钢丝球的钢丝……太恶心了
要吃死人嘛,都有钢丝球。
凉糕里面居然都有钢丝球
里面有钢丝球丝丝。#小炒肉#
train['labels_'] = clustering.labels_
for i in train[train['labels_']==22]['comment']:
print(i)
不错,经常来的,吃了N次了,爽歪歪
它家团了N次,味道好,服务态度也好
去吃了n次了真心不错,和姐妹聚餐可以
去了很多很多次了,一如既往的好,,希望再多一点菜品!!
味道好,服务也好,吃了N次了。
去了N次了。一如既往的好。加油
吃了N次了,一如既往的好吃,辣得过瘾,肉肉好多哟,味道好吃通过上面的案例,我们可以看到,文本聚类能够将同类问题进行归纳,能够放大隐藏的风险,如果扩大计算规模,我们可以发现更多的问题和风险,加上时间维度,是一个非常高效且有效的隐藏问题挖掘方法。
我们仅仅用了字的相似,并没有用语义相识,我们把文本的向量换成词向量,就可以得到语义相识了,后面有空再写。
推荐阅读:
我的2022届互联网校招分享
我的2021总结
浅谈算法岗和开发岗的区别
互联网校招研发薪资汇总
2022届互联网求职现状,金9银10快变成铜9铁10!!
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步
发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书