一、优化算法的一般途径
- 尝试获取更多的训练集
- 尝试选择更少的特征(特征选择?)
- 尝试获取新的特征
- 尝试增加模型的复杂度(如线性回归则增加参数的非线性程度,如神经网络则增加隐藏层的层数和隐藏层的每层的个数?)
- 尝试减小正则化参数
- 尝试减小正则化参数
那么在实际项目中,我们应该使用何种方法才可以把时间用在刀刃上,选择正确的方向进行行算法的优化呢?下边就是优化算法的一般方法。
二、算法诊断
- 通过算法诊断希望能达到了解算法哪里出了问题,以及要想改进算法的效果,什么样的改进才是有意义的。
- 为了评估算法的性能,我们一般讲数据集分为三部分:训练集、验证集、测试机。可以按照3:1:1的比例进行划分。
- 训练误差/验证误差/测试误差
- 模型选择:可以选择使交叉验证误差最小的那个模型
- 选择模型复杂度:当算法运行不好时,主要是源于以下两种情况:过拟合、欠拟合。在算法优化过程中需要搞清楚自己的算法是属于过拟合还是欠拟合。当弄清楚了对于优化算法非常重要。
如下图所示:如果验证误差和训练误差都很大,那么模型就处于过拟合状态;如果验证误差很大(远远大于训练误差),但是训练误差却很小,那么模型处于过拟合状态。
这里横坐标是多项式的次数,其实横坐标也可以是其他的变量。
- 选择正则化参数lamda:
选定一系列lamda值,算出相应的参数值,然后算出训练误差和和验证误差,选择验证误差最小的那个lamda值。
如图所示,是lamda指变化时训练误差和验证误差的曲线
可以看出,当lamda很小时,模型处于过拟合,当lamda很大时,模型处于欠拟合。 - 学习曲线
利用学习曲线判断算法是处于过拟合 、欠拟合,还是二者皆有。
a.一般的学习曲线
b.欠拟合的学习曲线:如果模型处于欠拟合状态,那么随着训练样本的增加,验证误差并不会下降,图像呈水平变化,那么可以知道增加训练样本,对于优化算法并没有明显的帮助。
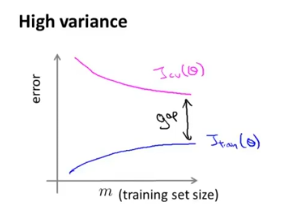
c.过拟合的学习曲线:如果模型处于过拟合,那么验证误差和训练误差之间有着较大的距离,当增大训练集大小事,验证误差减小,可以改善算法。
- 算法优化方式选择:
a.欠拟合:增加特征数量、增加模型复杂度、减小lamda
b.过拟合:增加训练集、减小特征数量、增加lamda - 神经网络结构的选择:
选择更复杂的神经网络比简单的神经网络表现好,如果担心过拟合,可以通过正则化来实现;当不知道选择几层隐藏层时,可以进行不同的尝试,选择验证集表现最好的那个模型。


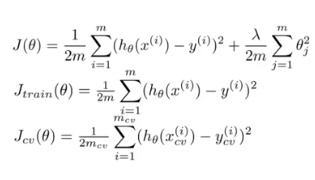



注:此为吴恩达机器学习的学习笔记。