机器学习(ML)正在形成自己的风格,人们越来越认识到ML可以在数据挖掘、自然语言处理、图像识别和专家系统等广泛的关键应用中发挥关键作用。ML在所有这些领域以及更多领域提供了潜在的解决方案,并将成为我们未来文明的支柱。
什么是机器学习?
[机器学习是]一个研究领域,它使计算机无需显式编程就能学习。
一个定义是:如果计算机程序在T上的性能(用P表示)随着经验E的提高而提高,那么它就可以从经验E中学习一些关于任务T和性能度量P的经验E。
如果你想让你的程序来预测,例如,在一个繁忙的十字路口交通模式(任务T),您可以运行它通过机器学习算法与数据过去的交通模式(E)经验,如果它成功地“学”,它将会做得更好在预测未来交通模式(性能指标P)。
ML可以解决单靠数值手段无法解决的问题。
一个主要的区别就是有监督/无监督学习。
**有监督学习:**该程序是在一组预先定义的“训练示例”上“训练”的,当给出新数据时,这些示例有助于它得出准确的结论。
**无监督学习:**程序得到一堆数据,必须从中找到模式和关系。
有监督机器学习
在大多数监督学习应用程序中,最终的目标是开发一个微调的预测函数h(x)(有时被称为“假设”)。“学习”包括使用复杂的数学算法来优化这个函数,这样,给定关于某个领域的输入数据x(例如,房子的平方英尺),它将准确地预测一些有趣的值h(x)(例如,该房子的市场价格)。
就像这样
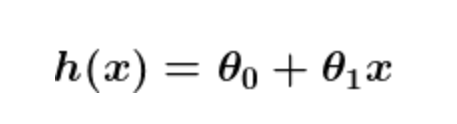
其中含两个常量,我们要找到这两个准确的值去让我们的预测器更加正确。
优化预测器h(x)的过程就是使用训练例子去训练的过程。
机器学习例子
为了便于说明,我们在本文中坚持使用简单的问题,但是在真实世界中,我们的问题会更复杂。
在这个平面屏幕上,我们最多可以画出一个三维数据集的图像,但是ML问题通常处理数百万维的数据,以及非常复杂的预测函数。ML可以解决单靠数值手段无法解决的问题。
ML的目标绝不是做出“完美”的猜测,因为ML处理的领域中不存在这样的东西。我们的目标是做出足够有用的猜测。