写在前面:本文是作者学习路上的笔记总结。
若干文字方面的内容摘自各大网站,包括百度、知乎、CSDN等,作为学习笔记分享给大家,非商用 侵删。
文章实验部分为作者实验真实实验数据,可供小伙伴参考。
一、引言
卷积神经网络可以处理图像以及一切可以转化成类似图像结构的数据。相比传统算法和其它神经网络,卷积神经网络能够高效处理图片的二维局部信息,提取图片特征,进行图像分类。通过海量带标签数据输入,用梯度下降和误差反向传播的方法训练模型。
二、卷积神经网络的结构
卷积神经网络的一般结构为卷积层、激活层、池化层和全连接层,有些还包含其他层,如正则化层、高级层等。卷积神经网络基本结构如图所示。下面对常用层的结构、原理等进行详细说明。

2.1卷积层
卷积神经网络中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法最佳化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。


2.2激活函数
激活函数对于人工神经网络模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用。它们将非线性特性引入到我们的网络中。在神经元中,输入的inputs通过加权,求和后,还被作用了一个函数,这个函数就是激活函数。引入激活函数是为了增加神经网络模型的非线性。

2.3池化层
池化是卷积神经网络中另一个重要的概念,它实际上是一种形式的降采样。有多种不同形式的非线性池化函数,而其中“最大池化Max pooling”是最为常见的。它是将输入的图像划分为若干个矩形区域,对每个子区域输出最大值。直觉上,这种机制能够有效地原因在于,在发现一个特征之后,它的精确位置远不及它和其他特征的相对位置的关系重要。池化层会不断地减小数据的空间大小,因此参数的数量和计算量也会下降,这在一定程度上也控制了过拟合。通常来说,CNN的卷积层之间都会周期性地插入池化层。
池化层通常会分别作用于每个输入的特征并减小其大小。最常用形式的池化层是每隔2个元素从图像划分出的区块,然后对每个区块中的4个数取最大值。这将会减少75%的数据量。


2.4全连接层
卷积神经网络中的全连接层等价于传统前馈神经网络中的隐含层。全连接层位于卷积神经网络隐含层的最后部分,并只向其它全连接层传递信号。特征图在全连接层中会失去空间拓扑结构,被展开为向量并通过激励函数 。
按表征学习观点,卷积神经网络中的卷积层和池化层能够对输入数据进行特征提取,全连接层的作用则是对提取的特征进行非线性组合以得到输出,即全连接层本身不被期望具有特征提取能力,而是试图利用现有的高阶特征完成学习目标。

三、卷积神经网络YOLOv5
目标检测架构分为两种,一种是two-stage,一种是one-stage,区别就在于 two-stage 有region proposal过程,类似于一种海选过程,网络会根据候选区域生成位置和类别,而one-stage直接从图片生成位置和类别。今天提到的 YOLO就是一种 one-stage方法。YOLO是You Only Look Once的缩写,意思是神经网络只需要看一次图片,就能输出结果。YOLO 一共发布了五个版本,其中 YOLOv1 奠定了整个系列的基础,后面的系列就是在第一版基础上的改进,为的是提升性能。
而今天我介绍的是当下YOLO最新的卷积神经网络YOLOv5!6月9日,Ultralytics公司开源了YOLOv5,离上一次YOLOv4发布不到50天。而且这一次的YOLOv5是完全基于PyTorch实现的!在我们还对YOLOv4的各种高端操作、丰富的实验对比惊叹不已时,YOLOv5又带来了更强实时目标检测技术。按照官方给出的数目,现版本的YOLOv5每个图像的推理时间最快0.007秒,即每秒140帧(FPS),但YOLOv5的权重文件大小只有YOLOv4的1/9。
YOLOv5有4个版本性能如图所示:


- 实验训练
我首先在轻薄笔记本HUAWEI MateBook 14上进行YOLOv5的训练。
实验平台:CPU:Intel core i7(10th) GPU:Nvidia Geforce MX-250
训练参数:Epoch : 100 img_size : 224*224 batch_size : 16
实验结果:
综合性能指标: 
混淆矩阵是对分类问题的预测结果的总结。使用计数值汇总正确和不正确预测的数量,并按每个类进行细分,这是混淆矩阵的关键所在。混淆矩阵显示了分类模型的在进行预测时会对哪一部分产生混淆。它不仅可以让我们了解分类模型所犯的错误,更重要的是可以了解哪些错误类型正在发生。
本次实验生成混淆矩阵:

实验生成的LABELS以及其相关曲线:


Precision是从预测结果角度出发,描述了二分类器预测出来的正例结果中有多少是真实正例,即该二分类器预测的正例有多少是准确的。“分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例”,衡量的是一个分类器分出来的正类的确是正类的概率。
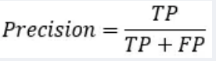

而Recall是从真实结果角度出发,描述了测试集中的真实正例有多少被二分类器挑选了出来,即真实的正例有多少被该二分类器召回。“分类器认为是正类并且确实是正类的部分占所有确实是正类的比例”,衡量的是一个分类能把所有的正类都找出来的能力。
实验P曲线与R曲线:


Precision和Recall通常是一对矛盾的性能度量指标。一般来说,Precision越高时,Recall往往越低。原因是,如果我们希望提高Precision,即二分类器预测的正例尽可能是真实正例,那么就要提高二分类器预测正例的门槛,例如,之前预测正例只要是概率大于等于0.5的样例我们就标注为正例,那么现在要提高到概率大于等于0.7我们才标注为正例,这样才能保证二分类器挑选出来的正例更有可能是真实正例;而这个目标恰恰与提高Recall相反,如果我们希望提高Recall,即二分类器尽可能地将真实正例挑选出来,那么势必要降低二分类器预测正例的门槛,例如之前预测正例只要概率大于等于0.5的样例我们就标注为真实正例,那么现在要降低到大于等于0.3我们就将其标注为正例,这样才能保证二分类器挑选出尽可能多的真实正例。
实验PR曲线:


F1分数(F1-score)是分类问题的一个衡量指标。一些多分类问题常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
对于某个分类,综合了Precision和Recall的一个判断指标,F1-Score的值是从0到1的,1是最好,0是最差。简而言之就是想同时控制recall和precision来评价模型的好坏。

图为实验F1得分曲线:

下面是最终模型对验证集的实验效果图:

对实验结果的分析可知,训练出的模型已具有一定的成效了。但受限于轻薄笔记本的显卡性能差距,我下一步用服务器进行更深入的训练。对不同的参数进行实验,不断调整改进YOLOv5网络结构选择最优的实验参数,得到更完美的训练结果模型。
备注:目前服务器训练mAP已达93.5%(未完成)