计算机视觉工程师在面试过程中主要考察三个内容:图像处理、机器学习、深度学习。然而,各类资料纷繁复杂,或是简单的知识点罗列,或是有着详细数学推导令人望而生畏的大部头。为了督促自己学习,也为了方便后人,决心将常考必会的知识点以通俗易懂的方式设立专栏进行讲解,努力做到长期更新。此专栏不求甚解,只追求应付一般面试。希望该专栏羽翼渐丰之日,可以为大家免去寻找资料的劳累。每篇介绍一个知识点,没有先后顺序。想了解什么知识点可以私信或者评论,如果重要而且恰巧我也能学会,会尽快更新。最后,每一个知识点我会参考很多资料。考虑到简洁性,就不引用了。如有冒犯之处,联系我进行删除或者补加引用。在此先提前致歉了!
| 卷积神经网络 | Convolutional Neural Network | CNN | 分类 |
|---|---|---|---|
| 全卷积神经网络 | Fully Convolutional Network | FCN | 分割 |
原理
比如1000分类任务
CNN输出的是1000x1
每个维度代表图像属于对应类别的概率
FCN输出的是1000xHxW
H和W代表输入图像的高和宽
相当于对每一个像素进行1000分类
从而实现了图像分割
上采样与反卷积
网络中需要卷积和池化提取和选择特征
然而,卷积和池化是一个下采样的过程
所以,提取的特征的宽和高小于输入图像
为了输出的宽和高恢复到和输入相同
需要进行上采样
FCN中用到的上采样方法是反卷积(转置卷积)
注:上采样是目的,反卷积是方法,两者不可混为一谈
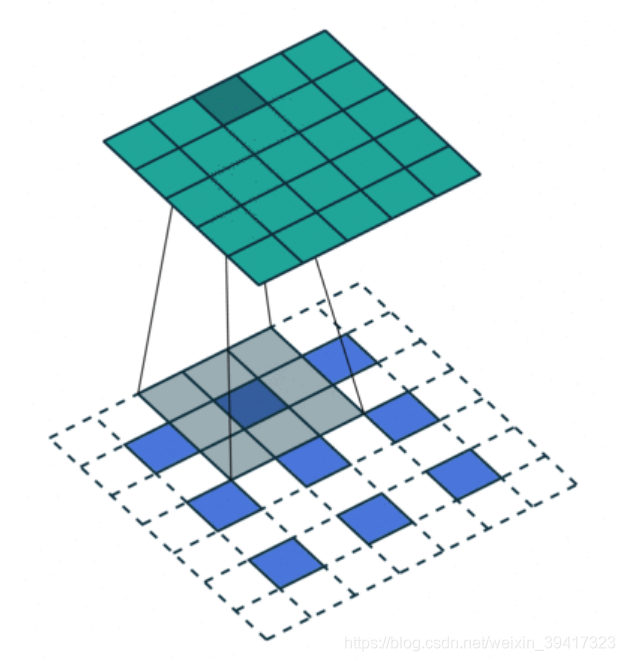
反卷积的过程
蓝色是反卷积输入
灰色是反卷积卷积核
绿色是输出
白色是填充
可以看出,经过反卷积,输出相比输入变大了
实现了上采样
注:卷积的stride指的是滑动的步长,反卷积的stride指的是填充的大小或者相邻像素的距离,下图中的stride是2
输入的图像大小是任意的?
这句话是不严格的
应该是:输入图像的大小可以是超过最小尺寸的任意大小
(当然,太大也不太好,仅仅是可以)
举个极端反例
输入图像是2x2的,网络中的池化层就没得池化了。。。
输入图像的大小可以是超过最小尺寸的任意大小
FCN使用卷积取代了CNN中的全连接
这也是FCN名字的含义
在CNN中,使用全连接
输出固定,网络的结构也是固定的,所以输入大小固定
在FCN中,使用全卷积
反卷积对feature map维度的恢复与卷积的下采样是对称的
举个例子(以下指的是宽和高的大小)
feature map = input/5/3/2
output = feature map x5 x3 x2 = input
feature map的大小不需要固定,所以不需要输入的大小是固定的
跳级结构skips
直观感受
用15x15的feature map反卷积成255x255的图像
这是十分粗糙的,所以结果也不精确
所以使用网络中间尺寸大一些的特征也进行反卷积
将反卷积的结果相加,得到精确一些的结果
如图所示
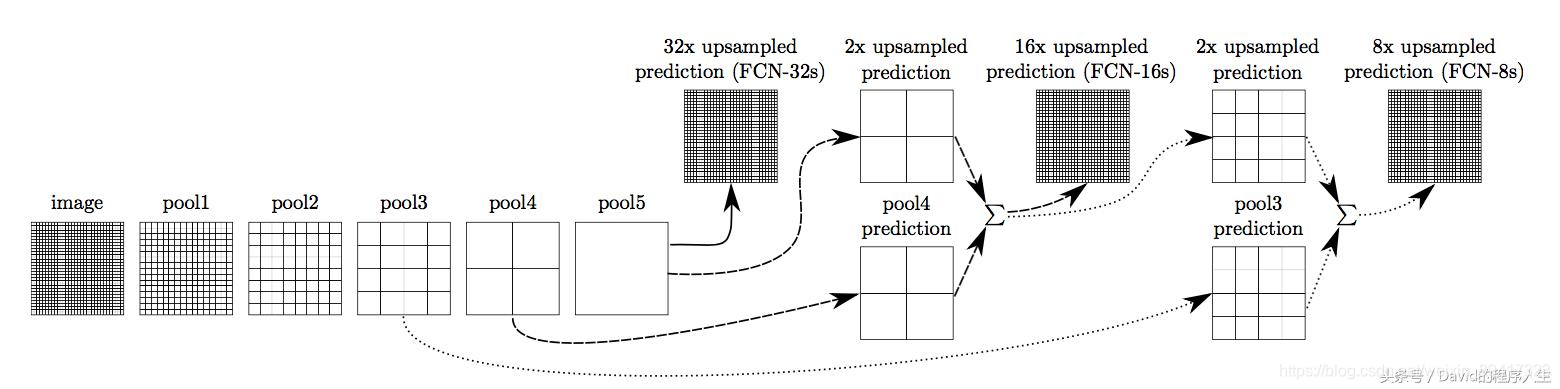
可以看出,结果精确了一些:

为什么跳级结构中是求和而不是取最大值?
求和更容易求导,从而反向传播。
CNN强行实现图像分割的方法
对图像进行滑动
比如每个窗口30x30
对每个窗口进行分类
进而判定窗口中心像素的类别
从而实现图像分割
缺点:
滑动窗口重叠过多,重复计算太多,计算量大
感受野太小
(FCN的感受野是基于整个图像的,上述做法只基于30x30)
FCN缺点
全篇看下来,FCN更像是凭感觉设计出来的优秀黑箱子
还是缺乏十分严谨的数学支撑,属于深度学习的固有属性吧
所以精确度肯定无法达到很高的水准
没有了全连接层,削弱了特征之间的组合关系
具体到分割任务,就是削弱了像素之间空间位置的联系
完
欢迎讨论 欢迎吐槽
