文章目录
1 所属领域:属于水文水资源和数据挖掘交叉领域
【所实话,这个专利的名字个人认为不好】
【这个发明旨在,设计一种进行区域降雨相似的分析方法,研究降雨区域相似】
主要考虑的是雨量站的降雨特征,具体考虑的是哪些特征,需要往下看。
现实意义:为补齐雨量站缺失数据、水文站点的合理布局提供支撑(科学依据)
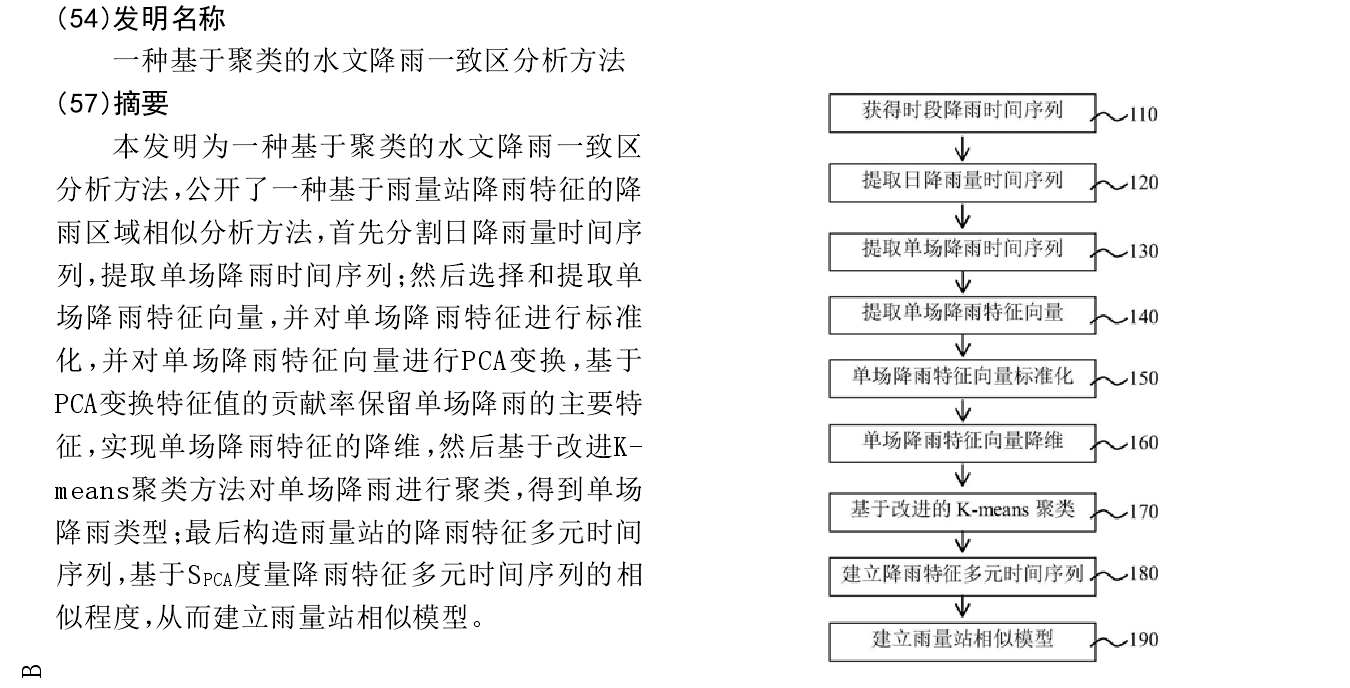
2 步骤分析
2.1 根据单场降雨分割规则进行分割,获得单场降雨时间序列
从几年的雨量站的数据中,划分出来N个单场降雨的序列(因为有很多时候是没有下雨的)
2.2 统计单场降雨时间序列的特征量,将每场降雨用一个n维特征向量表示
{p, d, a, dmax, dmin, p127, dp127, p50, dp50}
2.3 使用主成分变换,保留特征值贡献率超过阈值的维度,记为p个维度
就是从n个维度中,进行主成分分析,保留p个特征值贡献度大的维度
2.4 使用改进K-means方法对单场降雨向量进行聚类
2.5 基于雨量站所有汛期的降雨类型特征向量,建立基于监测时间的降雨特征序列
2.6 采用相似度量建立相似性模型,计算两个雨量站之间的S_pca距离
3 背景技术
- 缺失资料站点的数据补齐
- 选择多少年的雨量数据?
- 站点的合理规划。①取出冗余站点:如果地理位置相近的两个站点降雨相似度极高,可以考虑去除一个站点(如果距离较远则不考虑)
- 对相似类型的降雨站点进行分类
4 建立相似性模型
【个人感觉:这篇专利写的不行…在前面的发明声明部分,并没有看懂究竟是如歌构建相似性模型的,继续往下看…】

“本发明对降雨特征进行了精心的挑选”
——对不起。我要开始diss了
兄弟,借鉴是可以的,不过别说的好像是你的成果一样,抄同校的,三年前的发明专利,是不是有点过分了啊…!
而且我还是先学习的2012年的专利,再看到你的,可以点一下下面的链接进去看一下…
精心选择…我真是感觉到非常的无语…
https://blog.csdn.net/weixin_42521185/article/details/124959089
4.1 言归正传,讲一下这个过程
其实大的框架是没有改变的,还是要去做 K-means 聚类,然后统计所有类的降雨的场次,假设有K个类,类1有a场降雨,类2有b场降雨,类3有c场降雨…类K有k场降雨。
雨量站就可以用k维的向量表示出来,[a, b, c, d…k]
扫描二维码关注公众号,回复:
14220868 查看本文章

任意两个雨量站算相似度,用什么余弦相似度算一下,这个专利应该是在这个地方去做创新的…就是换了一种相似度的度量方式。