版权声明: https://blog.csdn.net/leida_wt/article/details/83056357
先导
1.pandas 依赖numpy包
2.pandas 以dataframe 和 series两种对象承载数据,前者是二维的,后者一维的
3.pandas 对dataframe 的操作逻辑是返回新的操作过的dataframe ,
所以这样才可更新数据操作:
df=df.drop(columns=[‘B’, ‘C’])
或
df.drop(columns=[‘B’, ‘C’],inplace=True)
两者等价
4.dataframe 和 series均重载了内部magic function,可想列表一样索引
5.print(df.head())来获取表结构
总结下,pandas的工作流程大致如下
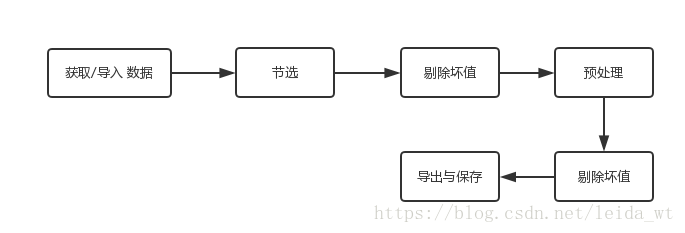
1.获取导入数据
从字典构建pd数据结构
df = {
'a': [1, 2, 3],
'b': [2, 3, 4]
}
df = pd.DataFrame(df)
print(df.head())
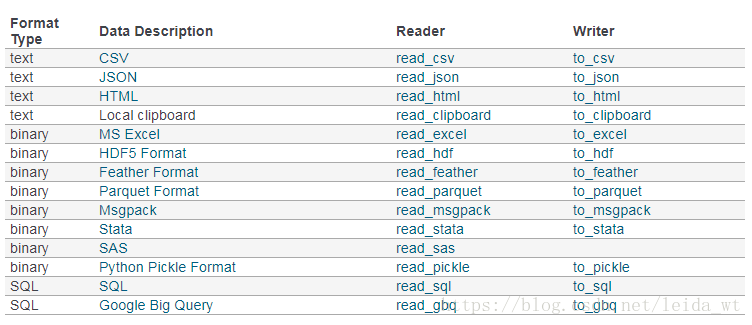
从文件构建pd数据结构
df = pd.read_csv('./data.csv')
df = pd.read_html('https://simple.wikipedia.org/wiki/List_of_U.S._states')
#从二进制pickle文件,重要
datas = pd.read_pickle('all_state_data.pickle')
#...
all导入函数如下
2.节选
#节选行
df=df[1:3]
#matlab方式选行列
df.ix[:,0:2]
df.ix[1:3,3:4]
#节选某些行(下为meters<1000的)
df = df[(df['meters'] < 1000)]
#删除某列
df = df.drop('AL', axis=1)
df = df.drop(columns=['a','b'])
3.剔除坏值
#直接删除含有NaN行
df.dropna(inplace=True)
#NaN用前填补
df.fillna(method='ffill',inplace=True)
#NaN用后填补
df.fillna(method='bfill',inplace=True)
#NaN填值定值
df.fillna(value=-99999,inplace=True)
#替换值
df.replace([np.inf, -np.inf], np.nan, inplace=True)
4.预处理
结构
#设置索引行为a
df.set_index('a', inplace=True)
#重置索引名a->b
df = df.rename(columns={'a': 'b'})
#添加新行c
df['c']=df['a']+df['b']
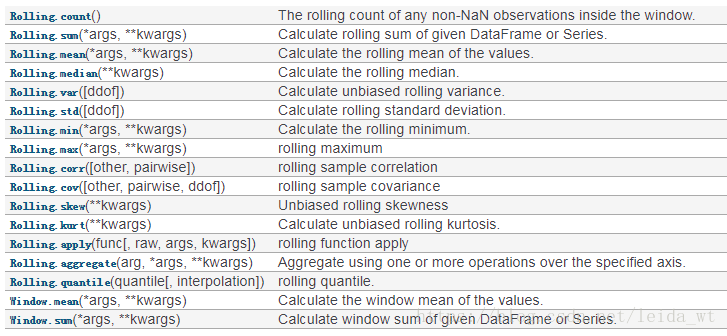
滑动窗类统计
形如df.rolling(xxx).xxx()
rolling填滑动窗统计
自定义函数
def handle(n):
return n**2
df['meters'] = df['meters'].apply(handle)
print(df)
5.导出
绘图
这时需另行引入matplotlib
import matplotlib.pyplot as plt
from matplotlib import style
style.use('fivethirtyeight')
df.plot.line()
plt.show()
所有绘图类型
导出到文件
形如
datas.to_pickle(‘datas.pickle’)
函数表见导入部分
pickle形式存为二进制流,最高效
