(1)数据的升序与降序
import pandas
food_info = pandas.read_csv(r"E:\PyCharm\food_info.csv")
food_info.sort_values("Sodium_(mg)", inplace= True) #对某列数据按照升序进行排列, ascending默认值为True(升序)
food_info.sort_values("Sodium_(mg)", inplace= True, ascending = False) #ascending对数据按照降序排列
print(food_info["Sodium_(mg)"])
(2)泰坦尼克船员获救信息分析
import pandas as pd
import numpy as py
titanic_survival = pd.read_csv(r".....文件地址....")
age = titanic_survival["Age"] #获取名字为Age的列
age_is_null = pd.isnull(age) #判断列中的数值是否为空,空[true], 非空[false]
age_null_true = age[age_is_null] #找出为空的列并显示出来
age_null_count = len(age_null_true) #显示出多少列为空
文件中有缺失值的话,没办法进行平均值求和或其它一些操作,所以要对缺失值进行处理
如:
mean_age = sum(titanic_survival["Age"]) / len(titanic_survival["Age"]) #打印出的结果为nan
处理方法
good_ages = titanic_survival["Age"][age_is_null == false] #取出年龄不为空的值
corrent_mean_age = sum(good_ages) / len(good_ages) #然后计算平均值
另一种计算平均值的方法
correct_mean_age = titanic_survival["Age"].mean()
(3)计算不同仓的船员的票价平均数
passenger_classes = [1,2,3] #不同仓的等级
fares_by_class = {} #一个不同仓等级和该等级的平均价为的一个空子典
for this_class in passenger:
pclass_row = titanic_survival[titanic_survival["Pclass"] == this_class ] #找出某等级仓的所有列
pclass_fares = pclass_row["Fare"] #找到某等仓的名称为Fare列的所有数据
fare_for_class = pclass_fares.mean() #求出某等仓名称为Fare列的平均值
fares_by_class[this_class] = fare_for_class #把船舱等级和该等级的平均数加入到字典当中。
print(fares_by_class)
![]()
(4)不同仓的人的获救平均数
passenger_survival = titanic_survival.pivot_table(index="Pclass", values="Survived", aggfunc=np.mean) #aggfunc默认为求均值方法
以Pclass为索引计算不同Pclass的人数获救概率(Survived为0或1,表示是否获救),结果如下:

(5)计算不同仓的年龄平均值
passenger_age = titanic_survival.pivot_table(index="Pclass", values="Age")
结果如下: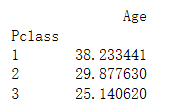
(6)以登陆码头(C,Q,S码头)为索引计算码头收的总金额,同时计算该码头获救人数
port_stats = titanic_survival.pivot_table(index="Embarked", values=["Fare", "Survival"], aggfunc=np.sum)
结果为:
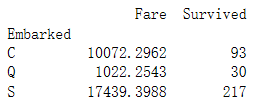
(7)把缺失值丢掉
new_titanic_survival = titanic_survival.dropna(axis=0, subset=["Age", "Pclass"])
把列Age和Pclass列中的值为空的行丢掉
(8)找出某行某列的某个数据
row_index_83_age = titanic_survival.loc[83, "Age"] #找出第83行,Age列的数据