这篇博客将介绍如何使用OpenCV在图像和视频流中执行基于深度学习的超级分辨率。
深度神经网络中有与超分辨率相关的
- 预训练好的模型
- 与OpenCV兼容
超分辨率是指放大图像后,图像的质量基本没有损失,依然清晰。
OpenCV的超分辨率功能实际上“隐藏”在一个名为dnn_superres的子模块中,该子模块位于一个名为DnnSuperResImpl_create的模糊函数中。需要opencv版本4.3+以上;
1. 效果图
对图像中的灯笼和鱼区域进行超像素化

原图 VS 双三次差值后图 VS EDSR效果图如下:
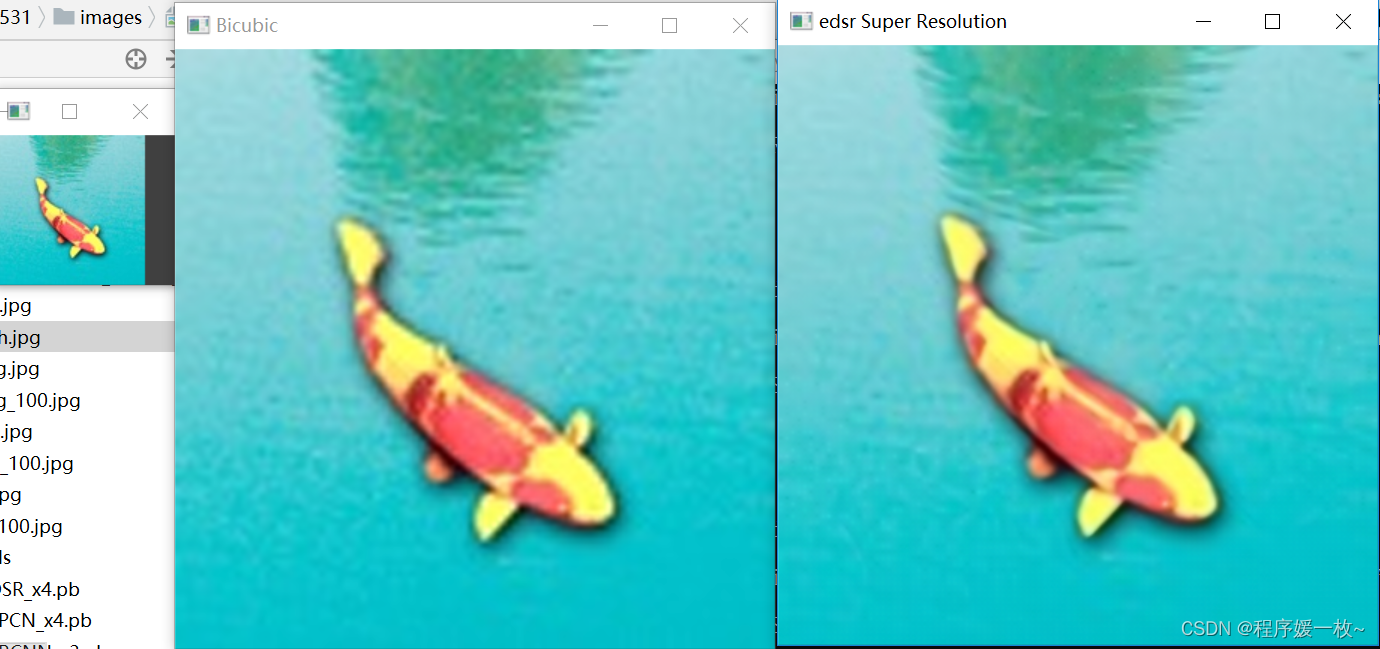 可以看到中间应用双三次插值,大小调整后质量较低。水纹鱼有些模糊。在右侧应用超分辨率深度学习模型的输出图:清晰、易于阅读,并显示最小的调整伪影迹象。
可以看到中间应用双三次插值,大小调整后质量较低。水纹鱼有些模糊。在右侧应用超分辨率深度学习模型的输出图:清晰、易于阅读,并显示最小的调整伪影迹象。
差别就像白天和黑夜。
EDSR超分辨率模型的缺点是速度有点慢。 标准的双三次插值可以获取100x100px的图像,并以大于1700帧/秒的速率将