超分辨率技术(Super-Resolution)是指从观测到的低分辨率图像重建出相应的高分辨率图像,在监控设备、卫星图像和医学影像等领域都有重要的应用价值。SR可分为两类:从多张低分辨率图像重建出高分辨率图像和从单张低分辨率图像重建出高分辨率图像。基于深度学习的SR,主要是基于单张低分辨率的重建方法,即Single Image Super-Resolution (SISR)。
几个较新的基于深度学习的SR方法,包括SRCNN,DRCN, ESPCN,VESPCN和SRGAN等。
1,SRCNN
Super-Resolution Convolutional Neural Network (SRCNN, PAMI 2016, 代码)是较早地提出的做SR的卷积神经网络。该网络结构十分简单,仅仅用了三个卷积层。
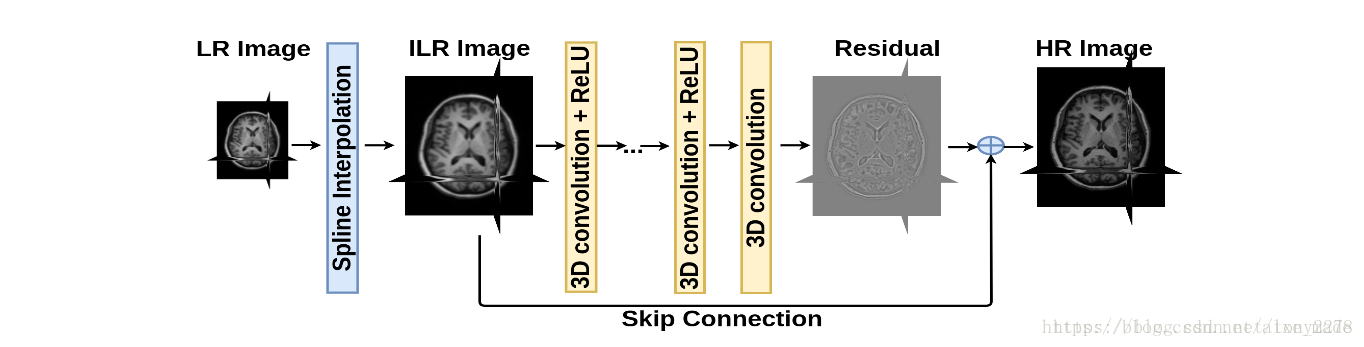
该方法对于一个低分辨率图像,先使用双三次(bicubic)插值将其放大到目标大小,再通过三层卷积网络做非线性映射,得到的结果作为高分辨率图像输出。作者将三层卷积的结构解释成与传统SR方法对应的三个步骤:图像块的提取和特征表示,特征非线性映射和最终的重建。三个卷积层使用的卷积核的大小分为为9x9, 1x1和5x5,前两个的输出特征个数分别为64和32. 该文章分别用Timofte数据集(包含91幅图像)和ImageNet大数据集进行训练。相比于双三次插值和传统的稀疏编码方法,SRCNN得到的高分辨率图像更加清晰......
深度学习应用到图像超分辨率重建
基于CNN的超分辨率重建方法
主要是用caffe实现论文中(SRCNN)所叙述的深度卷积网络,该网络可以用于实现图像的超分辨率。
超分辨率图像重建有单帧和多帧之分,文章中作者描述的是通过一张低分辨率图像得到一张高分辨率图像。
超分辨率有一个基本的问题,低分辨率图像和高分辨率图像含有的信息量不同。
如果单纯通过插值方法不会提升低分辨率图像的信息量,但是这样做人的视觉上看上去图像也会变清晰。
提升信息量有其他的方法,系统学习大量低分辨率到高分辨率的映射,这些映射也会作为一部分信息参与到高分辨率图像的重建。
也就是说,高分辨率图像不仅具有低分辨率图像的信息,同时还具有训练时大量图像的信息,因此这种情况下高分辨率图像的信息量有所提升。
SRCNN是稀疏编码方法进行超分辨率的一种改良。在这之前的超分辨率方法中,人们将注意力放在学习和优化低分辨率和高分辩率字典中,
或者以其他方法对其进行建模。SRCNN将整个步骤融合成了一个深度卷积网络,这个网络直接将低分辨率图像转换为高分辨率图像,
在训练过程中并不直接学习低分辨率和高分辩率字典,而是将整个网络作为一个整体进行训练,整个过程中只需要少许预处理。
SRCNN的运作方式如下:网络预先设定好上采样率upscale,然后输入一个低分辨率图像x。
首先进行预处理,将低分辨率图像进行插值upscale倍得到图像y,然后输入网络之中,目标是从Y中得到图像f(y),f是srcnn的映射,要求f(y)尽可能接近原始图像x的真实高分辨率版本。
因此srcnn的关键是学习这个映射方式f,f包含三个步骤:
......