目录
一、帧对齐简介
在进行视频超分辨率、压缩视频增强等任务的时候,我们通常会把目标帧和参考帧进行帧对齐,而帧对齐分为两种:显式帧对齐(光流估计+运动补偿)、隐式帧对齐(可变性卷积、3D卷积、循环神经网络等,这里只讲可变性卷积)。
二、显式帧对齐:光流估计+运动补偿
给定两个输入图像(前一帧:图1-后一帧:图2),我们的目标是找到每个像素的运动向量,光流就是前后两帧的运动矢量。而光流估计就是估计前后两帧的运动矢量。运动矢量就是我们物理上的“速度”。
其简单的计算过程就是:输入(两帧图像)-> 输出(光流),如图3所示。

图1

图2

图3
如下面两帧图像I和J,存像素点的移动,即上一帧I中红色像素点d在下一帧J中,其位置会有些轻微的变动,则该变动即为位移向量,也就是像素点的光流。(如图4)
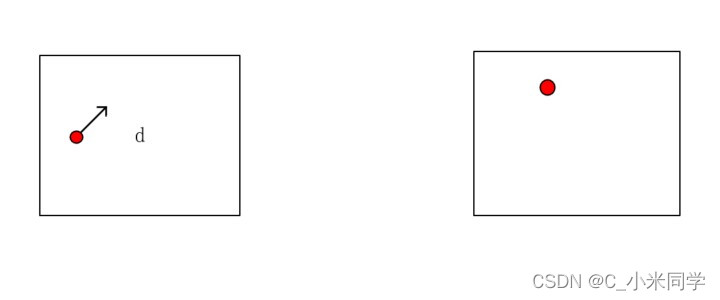
图4
传统的光流估计需要满足一下三个条件:
1.相邻帧之间的亮度恒定
2.相邻视频帧的取帧时间连续,或者相邻帧之间物体的运动比较“微小”
3.保持空间一致性,也就是同一子像素的像素点具有相同的运动
而深度学习的光流估计很大程度上打破这中束缚,可以完全实现端到端的训练、预测,目前比较流行的网络Spynet(如图5所示),该网络在时间推理和性能上都达到了很不错的效果。
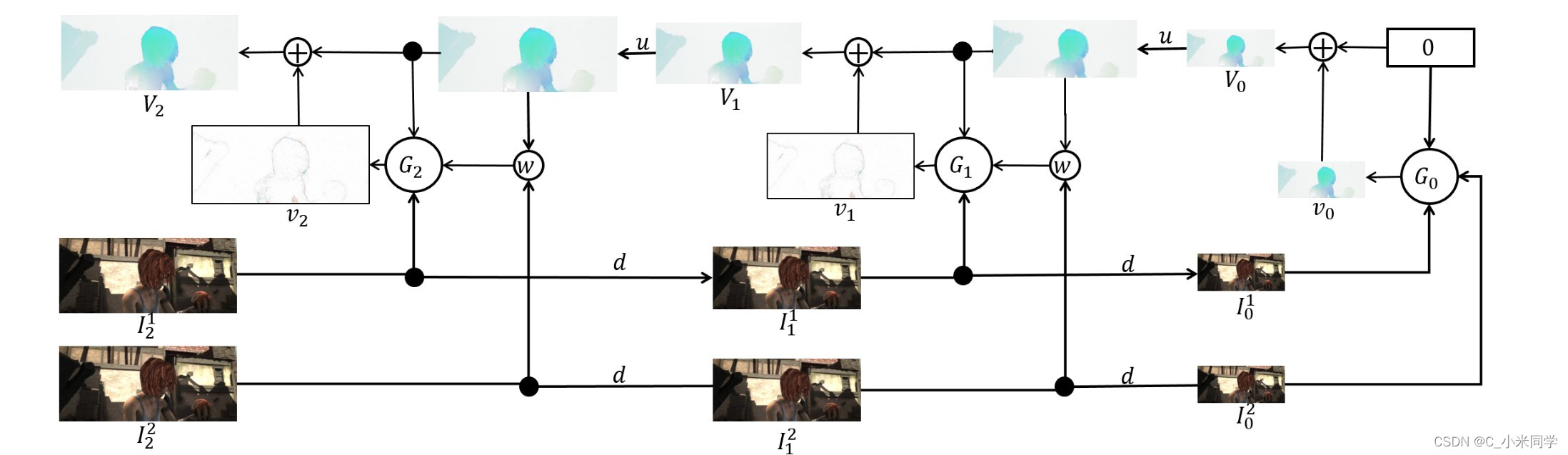
图5
几个参数说明:
u:上采样(2倍)
d:下采样(2倍)
G:生成光流的网络(需要训练)
vk:光流残差
Vk:光流(最终的计算结果)
Vk = u(Vk−1) + vk(光流计算)
vk = Vk − u(Vk−1) (光流残差计算)
Loss计算:欧式距离(如图6)
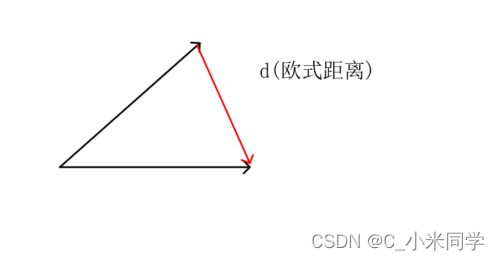
图6
该网络是基于金字塔的分层结构,从小尺度的光流估计到大尺度的光流估计,一定程度上缓解了运动幅度大的问题。效果如图7所示。有一个细节:之前说了,上面的光流代表了运动矢量,也就是速度,光流的颜色越深,速度越大,也就是运动幅度越大,我们在金字塔的第一层把降采样多次的图片(根据金字塔的层数决定降采样次数)输入光流网络G0,此时,两张图像并没有进行warp(运动补偿\帧对齐-一开始用0代替了初始的光流,也就是说:在金字塔的顶端,降采样多次后的小尺寸图像,我们默认两张图像的运动是不变的),这两张图像的运动幅度很大,所以由G0计算出来的残差光流v0颜色很深。而下一层的网络在图像传入G1之前,会进行warp操作,此时的两张图像的运动幅度会很小,所以出来的残差光流颜色很浅。

图7
我们可以发现,Spynet预测的光流和真实的光流还是非常接近的。
三、隐式帧对齐:可变性卷积
可变性卷积的结构如图8所示。
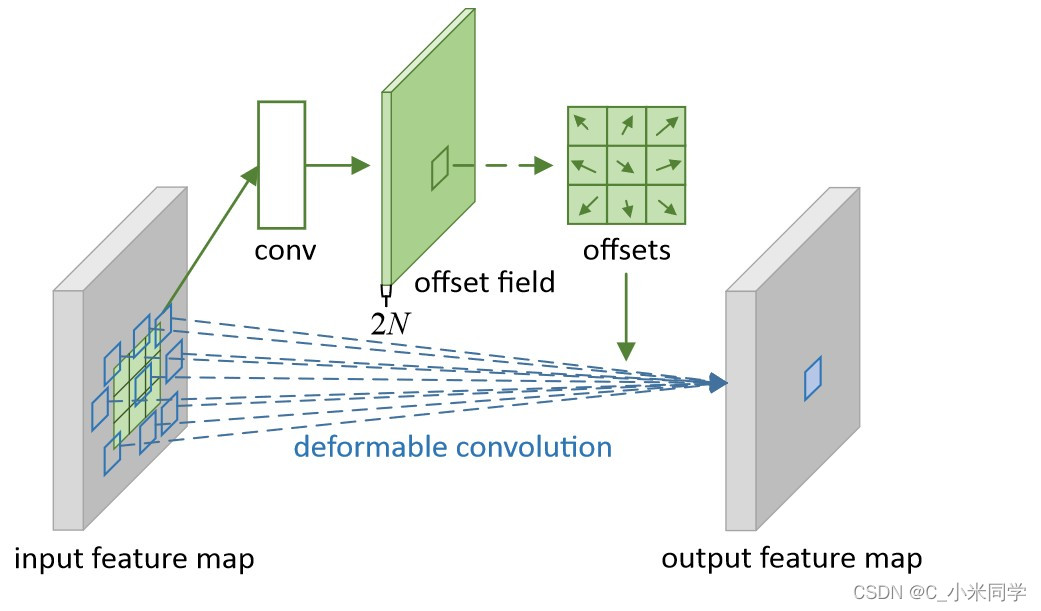
图8
我们可以看见,输入特征经过一个“conv”,得到2倍通道的偏移场(x,y两个方向),然后我们把偏移场展开,得到偏移量(offsets),然后我们把输入特征和偏移场同时放入可变性卷积,得到输出特征。
偏移量也是一个矢量,类似于光流,它可以“指导”特征图的像素移动,实现帧对齐,如图9所示。
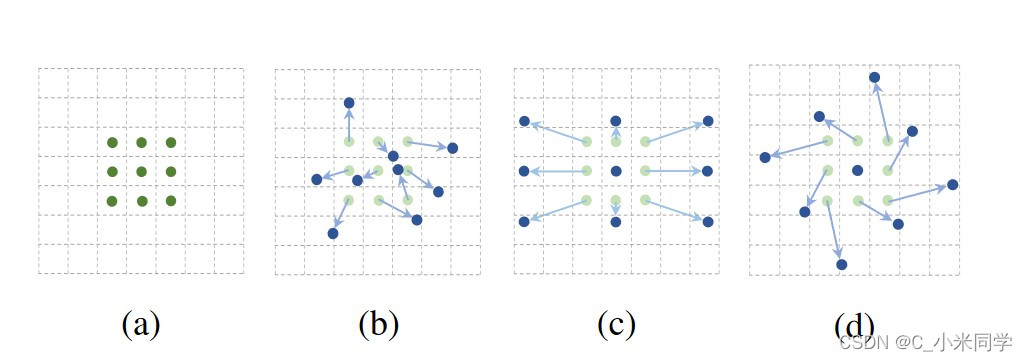
图9
可变性卷积的魅力在哪里?我们看图10。
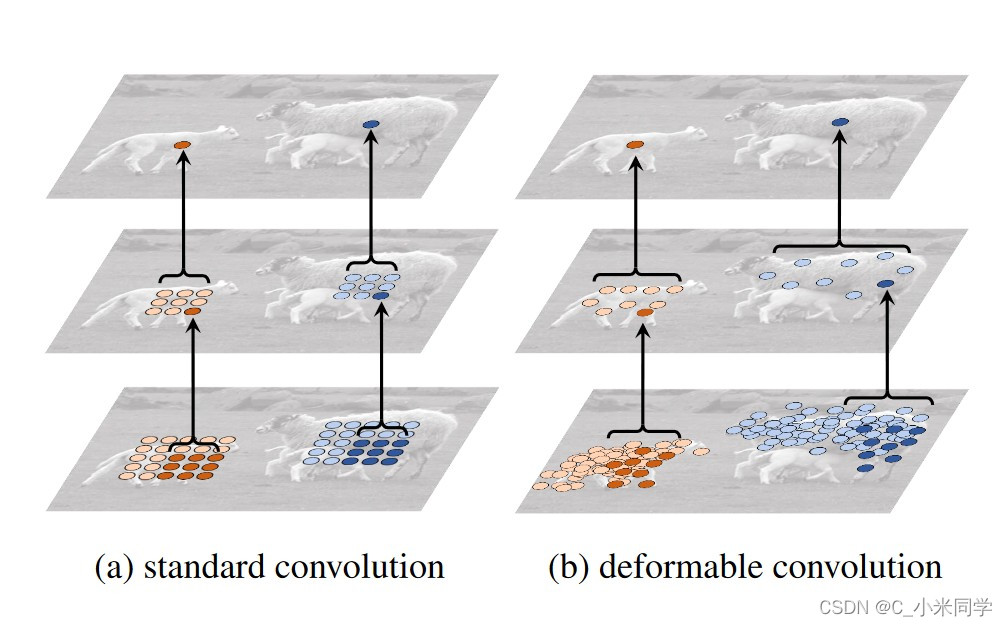
图10
我们可以对比一下感受野:(a)是普通卷积,其感受也是矩形,它可能会关注到物体之外事物,如背景等,这可能对目标检测,图片识别,运动估计这样的任务产生影响。(b)图是可变性卷积,可变性卷积的感受野是不规则的,随着偏移量变化而变化,它更关注物体本身,并且有更大的感受野。更确切的说是增大了有效感受野。
简单分析一下图(a)的感受野,如下图所示:
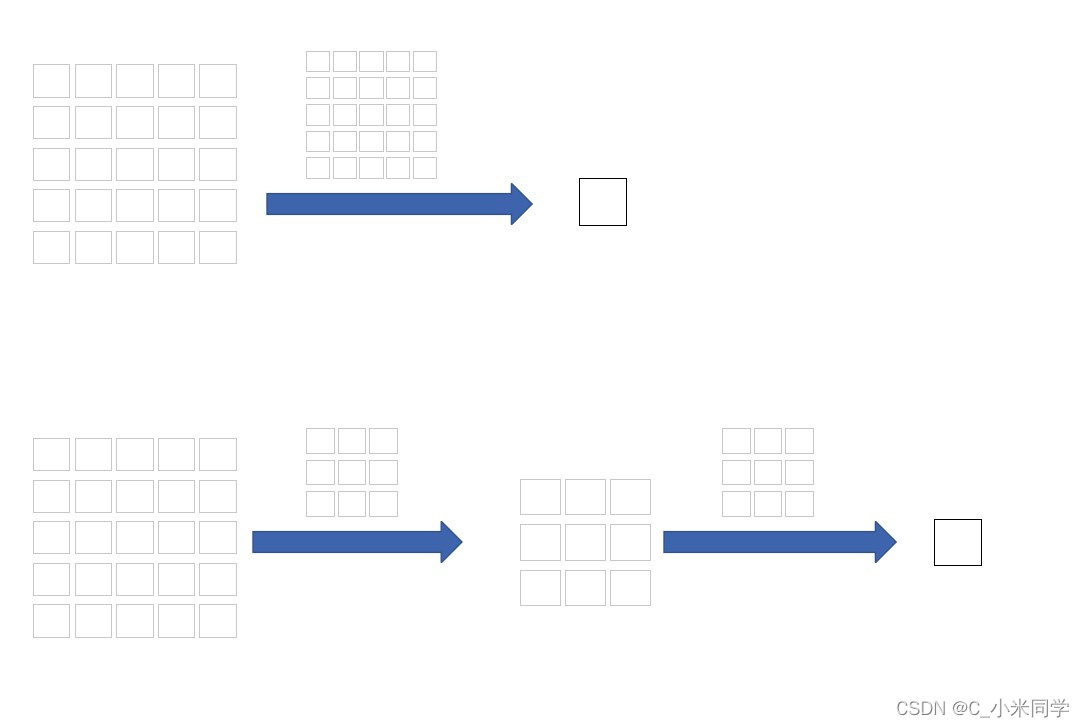
图11
5x5的特征图通过3x3的卷积核输出3x3的特征图,然后再经过3x3卷积核输出1x1的特征图,此时的感受野就是5x5。
如果对感受野不理解,可以参看我的这篇博客:C_小米同学
四、几个疑问
1.为什么要进行帧对齐
如图所示,
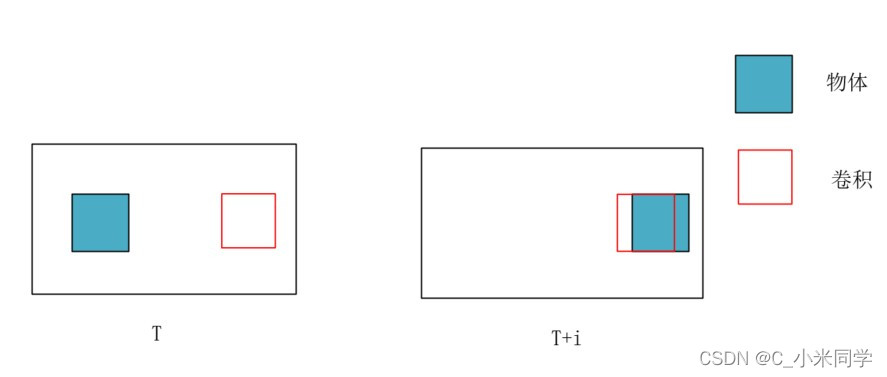
图12
我们可以看到,如果不进行帧对齐,T时刻的卷积核T+i时刻的卷积学习到的东西是不一样的,左边的卷积学习到的是一个背景,右边的卷积学习到的是物体,当两个卷积学习到的进行叠加的时候,会出现“叠影”,这会影响目标检测,运动估计等任务。
2.光流估计为什么可以应用视频插帧?
通过上面的介绍,我们知道:光流是描述两帧画面的运动矢量,而 位移= 速度x时间,我们可以通过时间,来计算位移。比如:我需要在第一秒的画面和第二秒的画面之间插入一帧(比如1.5秒),那我就可以计算他的 位移= 速度x1.5,此时的速度就是第一帧和第二帧画面的光流
3.光流估计和可变性卷积的区别
光流估计的可解释性更强,明确的表示两者之间的运动,可以明确的提取到光流特征。可变形卷积是自适应学习到的一个offset,offset并不一定描述的是运动性,它可能学习到了其他的东西。但是,可变性卷积的灵活性更高,可以自适应学习(虽然不能完全学习到运动信息)
可变性卷积的帧对齐并不是针对图片上的所有像素进行对齐,而光流是针对的全图。
4.运动幅度很大对可变性卷积有什么影响?
如图所示。
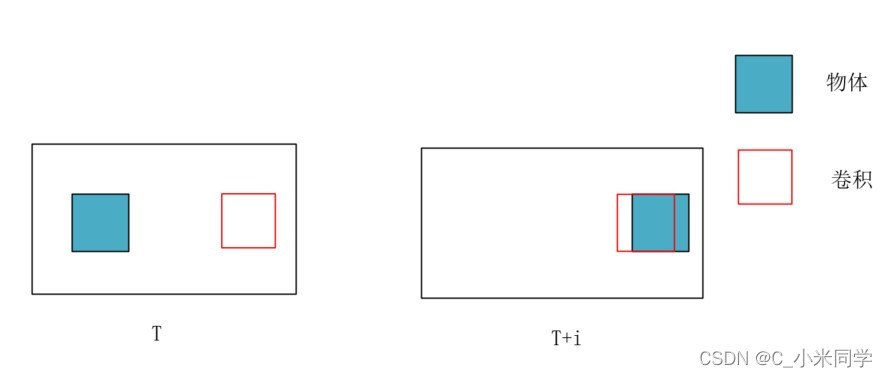
图13
我们可以看到,T和T+i时刻帧的运动幅度很大的时候,在同一个位置的卷积(红色框),右边卷积的物体在左边找不到参照物,不能把两者之间的运动联系起来,不能很好的预测offsets,所以,在这种情况下,offsets预测不准。
可以通过金字塔结构(类似于上面介绍的金字塔结构的光流法),把物体下采样几倍,然后卷积核大小不变,先对来说,扩大了感受野,卷积可以包含两个物体(可以捕获联两个物体的关系),这就可以很好地学习。