引言
在使用图片浏览软件显示图片时,为了凸显某个部位,你会放大图片,为了显示整体,你会缩小图片。
你的原始图片大小是固定的,但图像浏览软件既可以最大化到整个屏幕,也可以只占一个区域,这些操作是怎么实现的呢?
传统图像插值方法
在深度学习还没有涉猎图像超分之前,图像插值方法是图像放大,缩小,旋转以及形变过程中使用的主要手段。

根据插值算法的不同,即使对相同的图像进行调整大小或重新映射,结果也可能会有显著差异。插值只是一种近似,因此每次进行插值时,图像都会损失一些质量。
插值的概念
插值通过使用已知数据来估计未知点的值。例如:如果想知道中午的温度,但只在上午11点和下午1点测量了温度,可以通过执行线性插值来估计它的值:
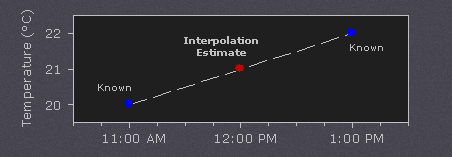
如果在上午11:30有额外的测量值,并根据常识温度上升的大部分发生在中午之前,则可以使用这个额外的数据点来执行二次插值:
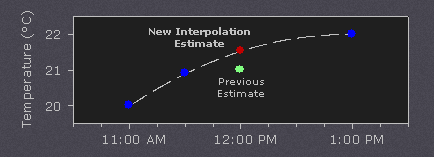
靠近中午的温度测量值越多,插值算法就可以越复杂(更准确)。
举个图形缩放的例子
图像插值在两个方向上基于周围像素的值来计算最佳近似。下图说明了图像缩放的工作原理:
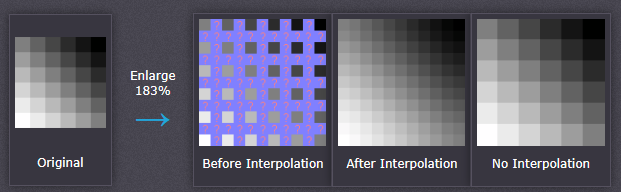
与上面温度的例子不同的是,两个连续的像素之间可能发生剧烈变化,例如,边缘。与温度例子相同的是,知道周围像素的信息越多,插值效果越好。总而言之,图像的拉伸程度越大,效果越差,因为插值没有对细节的想象能力。
图像旋转的例子
旋转或扭曲图像时,也会发生插值。前面图像缩放的例子是插值器特别擅长的一种情况。下面的例子显示了图像细节如何迅速地丢失:
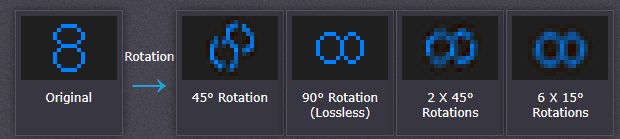
以上结果使用了所谓的“双三次”算法,只有90度旋转是无损的,其余都显示了明显的恶化。
不同的插值算法
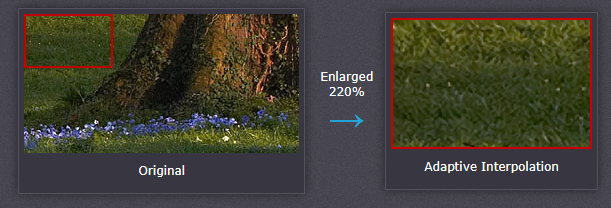
常见的插值算法可以分为两类:自适应和非自适应。自适应方法会根据插值的内容(锐利的边缘或平滑的纹理)而变化,而非自适应方法则会将所有像素都视为相等。
非自适应算法包括:最近邻、双线性、双三次、样条、sinc、lanczos 等。根据它们的复杂性,这些算法在插值时使用的相邻像素数量从0到256(或更多)不等。它们包含的相邻像素越多,就越能变得更准确,但这会以更长的处理时间为代价。这些算法可以用于扭曲和调整照片的大小。
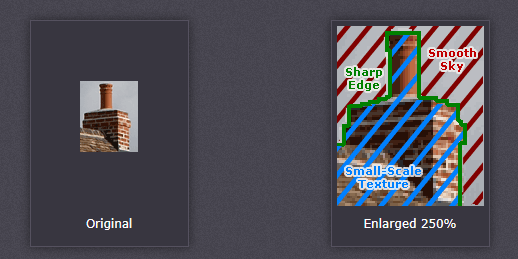
自适应算法在很多受版权保护的软件中都有应用,如 Qimage、PhotoZoom Pro、Genuine Fractals 。当检测到边缘存在时,会在像素级别上应用不同算法,以最大程度地减少插值伪影的出现。
最近邻插值
最近邻是最基本的插值算法,需要的处理时间最少,因为它只考虑一个像素—也就是最接近插值点的像素。这会使每个像素变大,从而简单地实现了放大的效果。
双线性插值
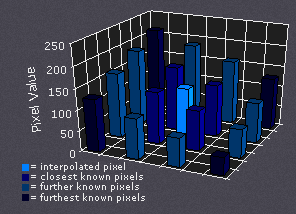
双线性插值考虑到了未知像素周围最近的2x2邻域像素值。然后对这4个像素进行加权平均,以得到最终的插值值。这会比最近邻插值产生更平滑的图像。
下图所示是未知像素与所有已知像素距离相等的情况,所以插值值仅为它们的总和除以4。
高阶插值方法:样条和SINC
这类插值器考虑了更多的周围像素,因此计算成本也更高。这些算法包括样条和sinc,插值后会保留更多的图像信息。因此,在需要对图像进行多次旋转/扭曲累加处理时,它们非常有用。但是,在单步放大或旋转的情况下,可能会出现卡顿的现象。
插值伪影
所有的非自适应插值算法都试图在三种不良效果(边缘光晕、模糊和混叠)之间找到最佳平衡点。
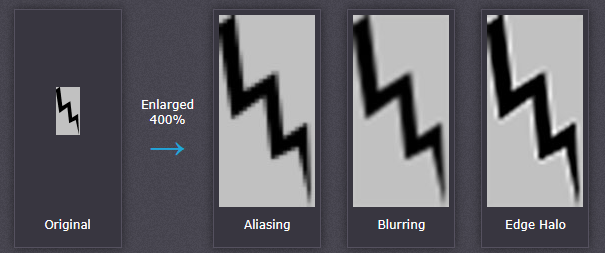
即使是最先进的非自适应插值算法,也不能同时消除上述三种不良效果,必须通过牺牲其中的一种或者两种来改善另一种。
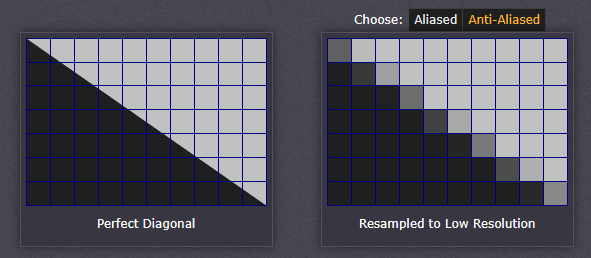
锯齿

抗锯齿技术可以消除这些锯齿,并给出更平滑的边缘和更高的分辨率外观。它的工作原理是考虑理想边缘与相邻像素的重叠程度。锯齿状的边缘只能四舍五入到最接近的像素值,而抗锯齿会为边缘所占像素根据所占比例计算一个颜色值。
锯齿:

抗锯齿:
基于深度学习的图像插值算法
基于深度学习的图像插值算法也被称为图像超分辨率,就是指将图像缩放而不失真。
深度学习发展到今天,无论是在自然语言处理,还是计算机视觉,都已经积累了大量的经验,接下来它会不断渗入到各个细分领域,去解决传统算法的效率和精度等性能问题。这也就是为什么已经有了传统插值算法,还会出现图像超分的原因。
传统算法的缺点前面已经说了,概括一下就是:不能完全消除伪影,锯齿和混叠,导致图像失真。
那为什么深度学习能改善这些缺点?
从传统的算法演化历程来看,越复杂的算法,考虑未知点周边像素数越多,效果就越好,非线性要比线性效果好,而深度学习正好能拟合非常非常复杂的映射。
举个基于阈值图像分割的例子,对于一个二值图像,选择一个阈值就能完成分割,一个阈值也就对应一个if判断语句,但现实中的图像都很复杂,即使使用多个阈值,分割结果也是散乱的,因为没有考虑空间因素,深度学习不仅能模拟非常多的判断语句,还能考虑空间因素。
再举个例子,会想起很早之前用过的机器翻译,效果很一般,它就是将输入的源句子分词,然后将词翻译成目标语言词汇,最后将词汇拼在一起。
I am a student -> 我是一个学生
但如果一个句子中出现了很多像where,that这些关系代词和关系副词时,翻译出来的句子就不通顺了。所以改进版加了目标语言语法知识。
I bought an apple for my girlfriend as a birthday present, it's full of technology
对于上面的句子,机器翻译并不知道it指代的是啥,直到Transformer的出现,它的注意力机制很大程度提升了翻译效果。
但当我认为这就是翻译的天花板时,直到我最近使用ChatGPT,我发现它不光懂语法,不光有注意力机制,它还有专业领域知识,它能识别一个词在不同上下文中有不同的涵义。他不会把一篇有关古董文章中的china翻译成中国,而是翻译成陶瓷。
而基于深度学习的图像超分就是如此,它不再是简单的像素加权求和,而是像一个非常复杂的非线性函数,它清楚的知道边缘的地方应该怎么插值,平坦的纹理区域应该怎么插值。
基于深度学习的插值与传统插值方法相比有如下优势:
- 学习复杂和非线性映射的能力:传统的插值方法,如双三次或双线性插值,使用数学公式来估计缺失的数据点或像素。这些公式基于对底层数据或图像的假设,例如平滑度或连续性。另一方面,基于深度学习的插值可以学习低分辨率和高分辨率图像之间复杂的非线性映射,使其更加灵活,适应不同类型的数据和图像。
- 更好地处理纹理和精细细节:传统的插值方法很难保留图像中的纹理和精细细节,尤其是在放大时。另一方面,基于深度学习的插值可以学习保留这些细节并产生更美观的结果。
- 处理异构数据的能力:传统的插值方法假设底层数据或图像是平滑的或连续的。然而,许多现实世界的数据和图像是异构的,具有复杂的结构和模式。基于深度学习的插值可以学习处理这些结构和模式,从而产生更准确和视觉上令人愉悦的结果。
- 改进的性能:基于深度学习的插值在多个基准数据集上取得了最先进的结果,证明了其与传统插值方法相比的卓越性能。
以下是一些著名的图像插值深度学习模型,以及每个模型的摘要:
-
超分辨率卷积神经网络 (SRCNN)
SRCNN 是一种开创性的深度学习模型,专为单幅图像超分辨率任务而设计。它以低分辨率图像作为输入,并学习低分辨率图像和高分辨率图像之间的端到端映射。该网络由三个卷积层组成,每个卷积层负责一个特定的任务:补丁提取、非线性映射和重建。
概括:单幅图像超分辨率的端到端学习,三层架构。
-
生成对抗网络 (GAN)
GAN 由一个生成器和一个鉴别器网络组成,它们在两人极小极大游戏中竞争。生成器创建合成图像,而鉴别器则试图区分真实图像和生成图像。GAN 已应用于各种图像合成任务,包括图像插值。
概括:对抗训练,适用于图像合成和插值。
-
用于单幅图像超分辨率 (EDSR) 的增强型深度残差网络
EDSR 是残差网络 (ResNet) 架构的改进版本,专为超分辨率任务而设计。它删除了不必要的组件,如批量归一化,并采用了更广泛的残差缩放策略。EDSR 在各种单幅图像超分辨率基准测试中表现出色。
概括:改进的 ResNet 架构,专为超分辨率任务量身定制。
-
深拉普拉斯金字塔超分辨率网络 (LapSRN)
LapSRN 是一种深度学习模型,它使用拉普拉斯金字塔框架逐步重建高分辨率图像。它以从粗到精的方式在多个尺度上执行图像插值。与其他超分辨率方法相比,LapSRN 在速度和准确性方面都表现出了出色的性能。
概括:渐进重建,拉普拉斯金字塔框架,由粗到细的插值。