随着数据库中对象的数量开始增长(可能数十亿个对象或视频帧),将新图像与每个数据库图像匹配所需的时间可能会变得令人望而却步。所以不能一次比较一张图像,而是需要一些技术来快速将搜索范围缩小到几个可能的图像,然后可以使用更保守的验证方法进行比较。
快速找到文档之间的部分匹配的问题是信息检索(IR),Information Retrieval中的核心问题之一。在计算机视觉中,在大型集合中找到特定对象的问题称为基于内容的图像检索 (CBIR),Content-based image retrieval或实例检索。快速文档检索算法的基本方法是预先计算单个单词和它们出现的文档(或网页或新闻故事)之间的倒排索引。更准确地说,文档中特定单词的出现频率用于快速找到与特定查询匹配的文档。
Sivic 和 Zisserman (2009) 是第一个将 IR 技术应用于视觉搜索的人。在他们的视频谷歌系统中,首先在所有视频帧中检测仿射不变特征,他们使用Harris特征点周围的形状适应区域进行索引和最大稳定极值区域,如下图a所示。

接下来,从每个归一化区域(上图b 中所示的补丁)计算 128 维 SIFT 描述符。 然后,通过累积逐帧跟踪的特征的统计数据来估计这些描述符的平均协方差矩阵。然后使用特征描述符协方差来定义特征描述符之间的马氏距离。 在实践中,通过将特征描述符预乘来白化特征描述符,以便可以使用欧几里德距离。
为了将快速信息检索技术应用于图像,必须首先将每个图像中出现的高维特征描述符映射到离散的视觉词中。 Sivicand Zisserman使用 k-means 聚类执行此映射,而后来的一些方法使用替代技术,例如词汇树或随机森林。为了保持聚类时间可控,只使用几百个视频帧来学习聚类中心,这仍然涉及从大约 300,000个描述符中估计数千个聚类,尽管后续工作大大扩展了这种能力。在视觉查询时,新查询区域中的每个特征(例如,上图a,它是从较大视频帧中裁剪的区域)被映射到其对应的视觉词。为了防止非常常见的模式污染结果,创建了最常见的视觉词的停止列表,并且这些词被从进一步考虑中删除。
一旦查询图像或区域被映射到其组成的视觉词中,就可以从数据库中检索可能匹配的图像。由于量化和评分特征的高效性,有学者构建的基于词汇树的识别系统能够在匹配时以 1Hz 和 40,000 张 CD 封面的数据库实时处理传入的图像从六部长篇电影中提取的一百万帧的数据库。
实例识别系统在 2000年后继续快速改进。在大型位置识别任务中,k-d 树的随机森林比词汇树表现更好(下图)。在后续工作中,有学者应用了信息检索的另一个想法,即查询扩展,它涉及从初始查询重新提交排名靠前的图像作为附加查询,以生成额外的候选结果。展示了如何使用软分配来缓解视觉单词选择中的量化问题,其中每个特征描述符都映射到许多附近的视觉单词,这类似于早先提出的多重分配思想。然而,这种技术往往会降低视觉词向量的稀疏性,增加内存和计算成本。还有学者在初始大尺度中结合了部分几何信息和局部描述符之间的显式匹配方案图像排名阶段。总之,这些算法帮助实例识别算法执行 Web 规模的检索、匹配、3D 重建任务。

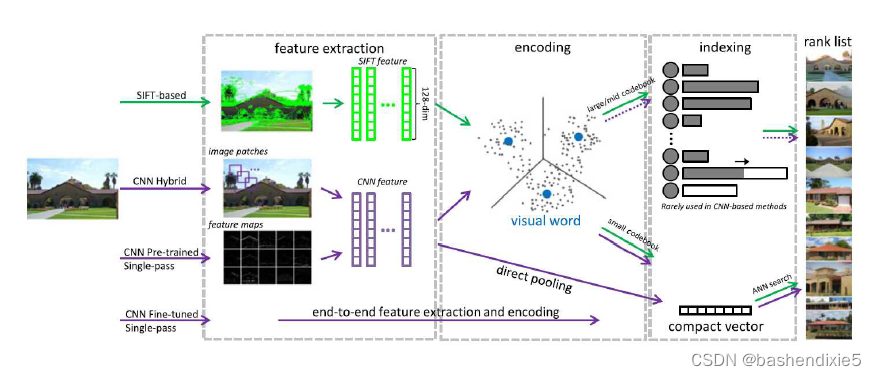
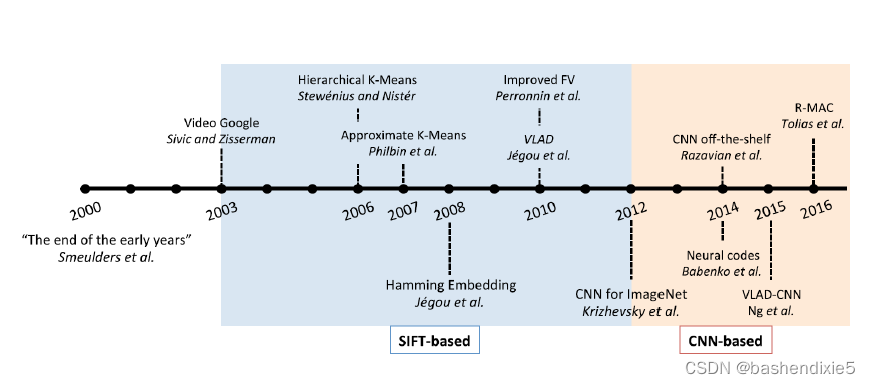
自 2012 年“深度学习革命”以来,研究人员开始开发神经特征检测器和描述符,有时将它们组合到端到端匹配系统中。下面的时间顺序图显示了实例中的一些主要里程碑检索,而再后面的图 显示了已考虑的各种不同的经典和基于 CNN 的检索架构。
2018年的一篇调查论文更详细地描述和对比了这些不同的算法,并提供了其中一些算法在图像检索数据集上的实验比较。您还可以在有关视觉相似性搜索的文章或论文中找到有关相关技术和系统的更多详细信息,比如用单个向量表示图像的全局描述符作为局部特征袋的替代方案。