一旦我们从两个或多个图像中提取了特征及其描述符,下一步就是在这些图像之间建立一些初步的特征匹配。我们采用的方法部分取决于应用程序,例如,不同的策略可能更适合格式化已知重叠的图像(例如,在图像拼接中)与可能没有任何对应关系的图像(例如,当尝试从数据库中识别对象时)。
我们将此问题分为两个独立的部分。首先是选择匹配策略,该策略确定哪些对应关系被传递到下一个阶段进行进一步处理。第二个是设计有效的数据结构和算法以尽快执行这种匹配。
1、匹配策略和错误率
进一步确定哪些特征匹配是合理的处理,取决于执行匹配的上下文。假设我们有两张重叠的图像(例如,用于图像拼接或跟踪视频中的对象)。我们知道,一幅图像中的大多数特征很可能与另一幅图像匹配,尽管有些可能因为被遮挡或外观变化太大而无法匹配。
另一方面,如果我们试图识别有多少已知对象出现在杂乱的场景中(下图),大多数特征可能不匹配。 此外,必须搜索大量可能匹配的对象,这需要更有效的策略,如下所述。

在杂乱的场景中识别物体。 数据库中的两个训练图像显示在左侧。 它们使用 SIFT 特征匹配到中间的杂乱场景,如右图中的小方块所示。 每个已识别的数据库图像在场景上的仿射扭曲在右侧图像中显示为较大的平行四边形。
首先,我们假设特征描述符的设计使得特征空间中的欧几里得(向量幅度)距离可以直接用于对潜在匹配进行排序。如果事实证明描述符中的某些参数(轴)比其他参数更可靠,通常最好提前重新缩放这些轴,例如,通过确定它们与其他已知的匹配。 一个较通用的过程,包括将特征向量转换为新的缩放基,称为白化(关于白化可以参考下面链接)。
机器学习笔记 - 深度学习的预处理和图像白化_bashendixie5的博客-CSDN博客我们将使用代码(Python/Numpy 等)进行编码,以更好的理解从数据预处理的基础知识到深度学习中使用到的技术。将从数据科学和机器学习/深度学习中基本但非常有用的概念开始,例如方差和协方差矩阵,我们将进一步介绍一些用于将图像输入神经网络的预处理技术。使用具体代码了解每个方程的作用!在将原始数据输入机器学习或深度学习算法之前,我们称其为对原始数据的所有转换进行预处理。例如,在原始图像上训练卷积神经网络可能会导致较差的分类性能。预处理对于加快训练也很重要(例如,居中和https://skydance.blog.csdn.net/article/details/124448227 给定一个欧几里得距离度量,最简单的匹配策略是设置一个阈值(最大距离)并返回该阈值内其他图像的所有匹配项。将阈值设置得太高会导致太多误报,即返回不正确的匹配项。 将阈值设置得太低会导致太多的假阴性,即错过太多正确的匹配(下图)。
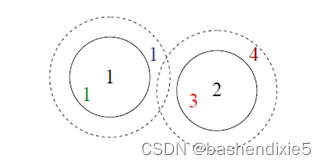
黑色数字 1 和 2 是与其他图像中的特征数据库匹配的特征。在当前阈值设置(实心圆圈)下,绿色1是真阳性(匹配良好),蓝色1是假阴性(匹配失败),红色3是假阳性(不正确匹配)。如果我们将阈值设置得更高(虚线圆圈),蓝色1变为真阳性,而棕色4变为额外的假阳性。
我们可以通过首先计算真假匹配和匹配失败的数量来量化匹配算法在特定阈值下的性能,使用以下定义:
TP:真阳性,即正确匹配的数量;
FN:假阴性,未正确检测到的匹配;
FP:误报,建议的匹配不正确;
TN:真阴性,被正确拒绝的不匹配。
下表显示了包含这些数字的样本混淆矩阵(列联表)。
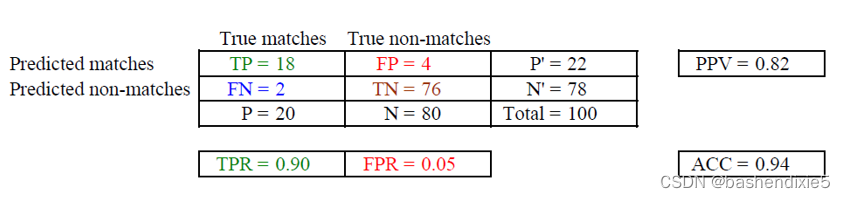
通过特征匹配算法正确和错误估计的匹配数,显示真阳性(TP)、假阳性(FP)、假阴性(FN)和真阴性(TN)的数量。 列总和为实际的正数 (P) 和负数 (N),而行数总和为预测的正数 (P0) 和负数 (N0)。 文中给出了真阳性率(TPR)、假阳性率(FPR)、阳性预测值(PPV)和准确率(ACC)的公式。
我们可以通过定义以下数量将这些数字转换为单位比率

在信息检索(或文档检索)文献中,常使用术语精度(有多少返回的文档是相关的)而不是 PPV 和召回(部分相关文档)代替 TPR。准确率和召回率可以组合成一个称为 F分数的单一度量,这是它们的调和平均值。这个单一度量通常用于对视觉算法进行排名。(可以从下面链接中参考相应参数的具体说明)
机器学习笔记 - IOU、mAP、ROC、AUC、准确率、召回率、F分数_bashendixie5的博客-CSDN博客_iou 机器学习一、什么是交并比?1、交并比(IOU)概述交并比(Intersection over Union) 是一种评估指标,用于衡量目标检测器在特定数据集上的准确性。任何提供预测边界框作为输出的算法都可以使用 IoU 进行评估。只要有测试集手工标记的边界框和我们模型预测的边界框。就可以计算交并比。R1:真实的边界框矩形的范围;R2:预测出来的矩形的范围;Rol:R1和R2重合的范围。 如下图所示 IOU值体现了单个对象...https://skydance.blog.csdn.net/article/details/123738525 任何特定的匹配策略(在特定的阈值或参数设置下)都可以通过 TPR 和 FPR来评价,理想情况下,真阳性率接近1,假阳性率接近0。当我们改变匹配阈值时,我们会得到一组这样的点,这些点统称为接收器操作特征(ROC)曲线 (下图a)。该曲线越靠近左上角,即曲线下面积(AUC)越大,其性能越好。下图b显示了我们如何绘制匹配和不匹配的数量作为特征间距离d的函数。这些曲线可以用来绘制 ROC 曲线。ROC曲线也可以用来计算平均精度,也就是平均精度(PPV),你可以改变阈值来选择最好的结果。
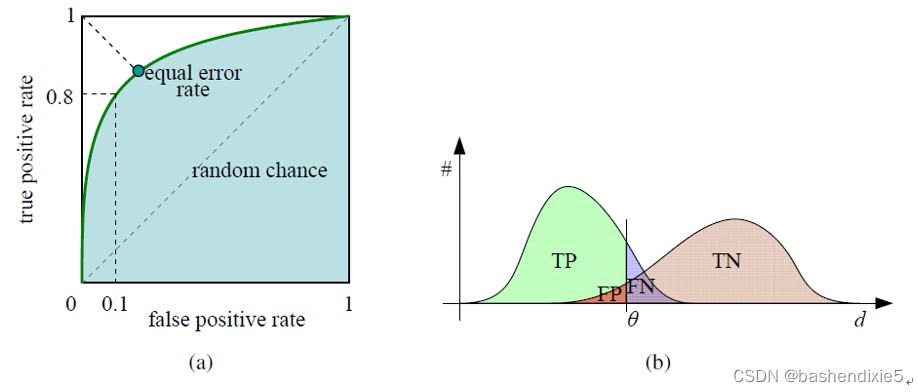
使用固定阈值的问题是难以找到适合的阈值,当我们移动到特征空间的不同部分时,有用的阈值范围可能会有很大差异。在这种情况下,更好的策略是简单地匹配特征空间中的最近邻。由于某些特征可能没有匹配项(例如,它们可能是物体识别中背景杂波的一部分,或者它们可能被其他图像遮挡),仍然使用阈值来减少误报的数量。
理想情况下,这个阈值本身将适应特征空间的不同区域。如果有足够的训练数据可用,有时可以为不同的特征学习不同的阈值。然而,通常我们只是简单地得到一个集合要匹配的图像,例如,在从无序照片集合中拼接图像或构建3D模型时。在这种情况下,一个有用的启发式方法可以是将最近邻距离与第二最近邻的距离进行比较,最好取自已知与目标不匹配的图像(例如,数据库中的不同对象)。 我们可以将这个最近邻距离比定义为
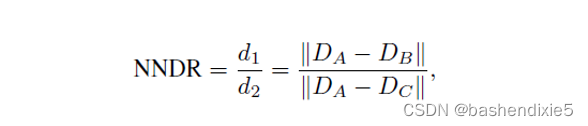
其中和
是最近邻距离和次近邻距离,
是目标描述符,
和
是其最近的两个邻域(下图)。最近的研究表明,相互NNDR(或至少具有交叉一致性检查的 NNDR)明显优于单向 NNDR。
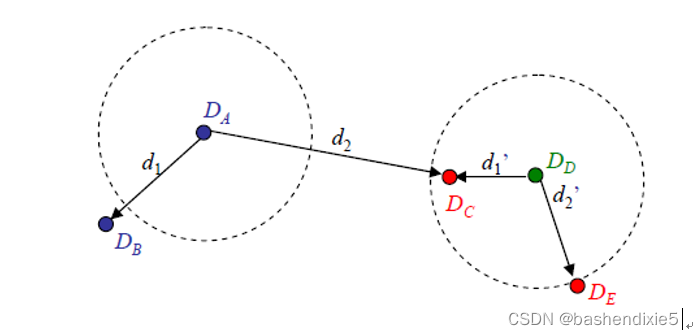
固定阈值、最近邻和最近邻距离比匹配。在固定距离阈值(虚线圆圈)处,描述符 无法匹配
,
错误匹配
和
。 如果我们选择最近的邻居,
正确匹配
,但
错误匹配
。 使用最近邻距离比(NNDR)匹配,小的NNDR
正确匹配
与
,大NNDR d’1/d‘2正确拒绝了匹配
。
2、高效匹配
一旦我们决定了匹配策略,仍需要有效地搜索潜在的候选人。找到所有对应特征点的最简单方法是将所有特征与每对可能匹配的图像中的所有其他特征进行比较。虽然传统上这在计算代价上过于昂贵,但现代GPU已经实现了这样的比较。
一种更有效的方法是设计一种索引结构,例如多维搜索树或哈希表,以快速搜索给定特征附近的特征。这样的索引结构可以为每个图像独立构建(如果我们只想考虑某些潜在匹配,例如搜索特定对象,这很有用),也可以为给定数据库中的所有图像全局构建,这可能会更快,因为它删除了需要迭代每个图像。对于非常大的数据库(数百万张或更多图像),基于文档检索的想法甚至更有效的结构,例如词汇树、产品量化或倒排多索引等。
一种更简单的技术是多维散列,它基于应用于每个描述符向量的某些函数将描述符映射到固定大小的桶中。在匹配时,每个新特征被散列到一个桶中,并且搜索附近的桶用于 返回潜在的候选人,然后可以对其进行排序或评分以确定哪些是有效的匹配项。
一个简单的散列示例是Brown、Szeliski和Winder(2005)在他们的MOPS论文中使用的Haar小波。在匹配结构构建过程中,每个8*8缩放、定向和归一化的MOPS补丁通过执行转换为三元素索引在补丁的不同象限上求和。得到的三个值通过它们的预期标准偏差进行归一化,然后映射到两个(b=10)最近的一维 bin。通过连接三个量化值形成的三维索引用于索引存储(添加)特征的8个bin。在查询时,仅使用主要(最近)索引,因此只需要检查单个3维bin。然后可以使用bin中的系数来选择k个近似最近邻以进行进一步处理(例如计算 NNDR)。
更复杂但更广泛适用的哈希版本称为局部敏感哈希,它使用独立计算的哈希函数的联合来索引特征。此技术扩展为对参数空间中的点分布更敏感,称之为参数敏感散列。最近的工作将高维描述符向量转换为可以使用汉明距离进行比较的二进制代码或者可以容纳任意核函数。
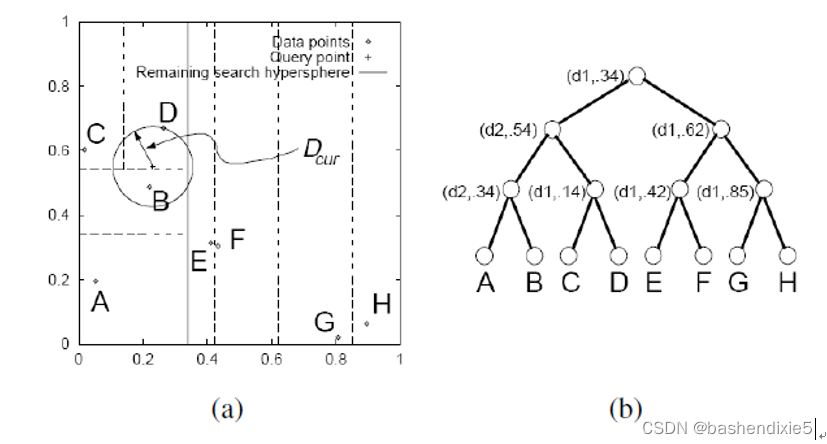
另一类广泛使用的索引结构是多维搜索树。其中最著名的是 k-d 树,通常也写为 kd-trees,它沿交替的轴对齐超平面划分多维特征空间,选择沿每个轴的阈值以最大化某些标准,例如搜索树平衡。下图a显示了一个二维 k-d 树的示例。在这里,八个不同的数据点 A-H 显示为排列在二维平面上的小菱形。k-d树沿轴对齐(水平或垂直)的切割平面递归地分割该平面。每个拆分可以使用维度编号和拆分值来表示(下图b)。拆分的排列是为了尽量平衡树,即保持其最大深度尽可能小。在查询时,经典的k-d 树搜索首先将查询点 (+) 定位在其适当的 bin (D) 中,然后在树中搜索附近的叶子 (C, B, ...) 直到它可以保证找到最近的邻居。最佳箱优先 (BBF) 搜索按箱与查询点的空间接近顺序搜索箱,因此通常更有效。
已经开发了许多额外的数据结构来解决精确和近似最近邻问题。例如,Nene 和 Nayar (1997) 开发了一种他们称之为切片的技术它使用对沿不同维度排序的点列表进行一系列一维二进制搜索,以有效地剔除位于查询点的超立方体内的候选点列表。Grauman和Darrell (2005)在索引的不同级别重新加权匹配树,这使得他们的技术对树构造中的离散化错误不太敏感。Nist´er和Stew´enius(2006)使用度量树,它将特征描述符与层次结构中每个级别的少量原型进行比较。由此产生的量化视觉然后可以将单词与经典的信息检索(文档相关性)技术一起使用,从数百万图像的数据库中快速筛选出一组潜在的候选者。Muja和Lowe(2009)比较了其中的一些方法,引入了他们自己的新方法(分层 k-均值树的优先搜索),并得出结论,多随机 k-d 树通常提供最佳性能。用于计算近似最近邻的现代库包括FLANN和Faiss。
3、特征匹配验证
一旦我们有了一些候选匹配,我们就可以使用几何对齐来验证哪些匹配是内点,哪些是异常点。例如,如果我们期望整个图像在匹配视图中被平移或旋转,我们可以拟合一个全局几何变换并只保留那些足够接近这个估计变换的特征匹配。选择一小组种子匹配然后验证更大集合的过程通常称为随机抽样或 RANSAC。一旦建立了一组初始对应关系,一些系统就会寻找额外的匹配,例如,通过沿着核线或在基于全局变换的估计位置附近寻找额外的对应关系。也可以使用深度神经网络来执行特征匹配和过滤。