模型预测效果评价,通常可以用以下指标来衡量
目录
5.准确度(Accuracy)、精确率(Precision)和召回率(Recall)
1.绝对误差和相对误差
设表示实际值,
表示预测值,则绝对误差E表示为
相对误差e表示为
2.平均绝对误差、均方误差、均方根误差与平均绝对百分误差
平均绝对误差(Mean Absolute Error, MAE)计算公式如下:
表示第i个实际值与预测值的绝对误差。
均方误差(Mean Squared Error, MSE)计算公式如下:
均方根误差(Root Mean Squared Error,RMSE)计算公式如下:
平均绝对百分误差(Mean Absolute Percentage Error,MAPE)计算公式如下:
一般认为MAPE小于10时,预测精度较高
这几个指标都是误差分析的综合指标。
3.Kappa统计
Kappa统计是比较两个或多个观测者对同一事物或者观测者对同一事物的两次或多次观测结果是否一致,Kappa取值在区间[-1,1]内,其值的大小均有不同意义,具体如下:

4.混淆矩阵

混淆矩阵中元素的行下标对应目标的真实属性,列下标对应分类器产生的识别属性,对角线元素表示各个模式能够被分类器正确识别的百分率。下面还会有混淆矩阵更多介绍。
5.准确度(Accuracy)、精确率(Precision)和召回率(Recall)
假阴性(FN): 算法预测为负例(N),实际上是正例(P)的个数,即算法预测错了(False);
真阴性(TN):算法预测为负例(N),实际上也是负例(N)的个数,即算法预测对了(True);
真阳性(TP):算法预测为正例(P),实际上是负例(N)的个数,即算法预测错了(False);
假阳性(FP):算法预测为正例(P),实际上也是正例(P)的个数,即算法预测对了(True)。
混淆矩阵定义如下:
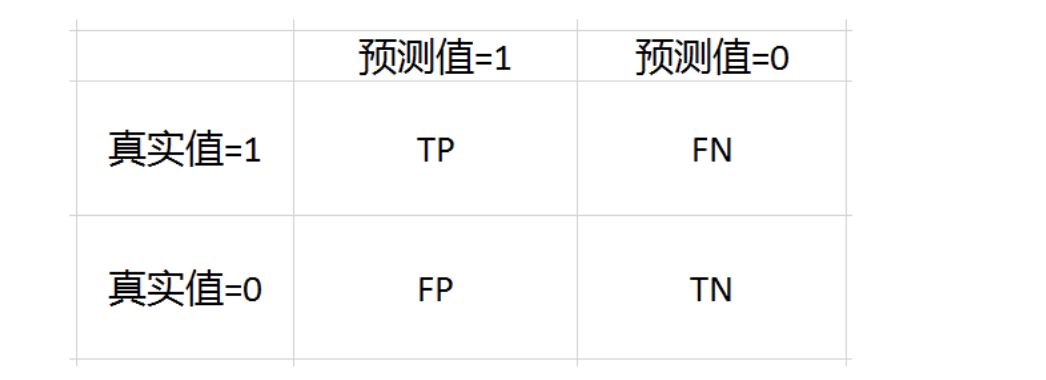
准确率表示所有样本中模型预测正确的比例;
精确率表示预测为正例中实际是正例(预测正确)的比例,判断预测结果准不准
召回率,也叫查全率,表示实际正例中预测正确的比例,判断预测结果全不全
F1是精准率和召回率的调和平均调和平均一个很重要的特性是如果两个数极度不平衡(一个很大一个很小),最终的的结果会很小,只有两个数都比较高时,调和平均才会比较高,这样便达到了平衡精准率和召回率的目的。
6.ROC曲线与AUC
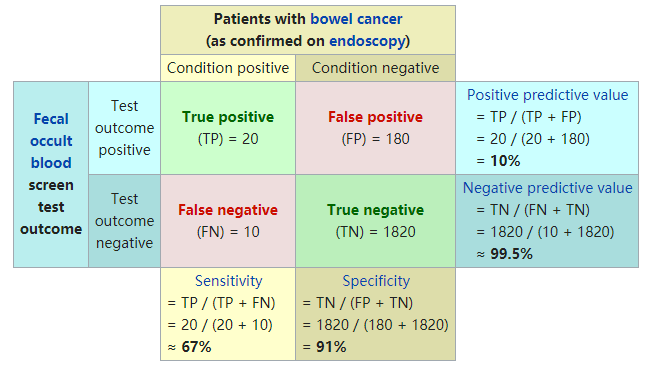
灵敏度(sensitivity):true positive rate,真阳性样本在实际阳性样本中的占比,也是上面的召回率
特异度(specificity):true negative rate,真阴性样本在实际阴性样本中的占

此图来自:统计学中的灵敏度和特异度 - 知乎
ROC(receiver operating characteristic curve,受试者工作特性)曲线是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(灵敏度)为纵坐标,假阳性率(1-特异度)为横坐标绘制的曲线。
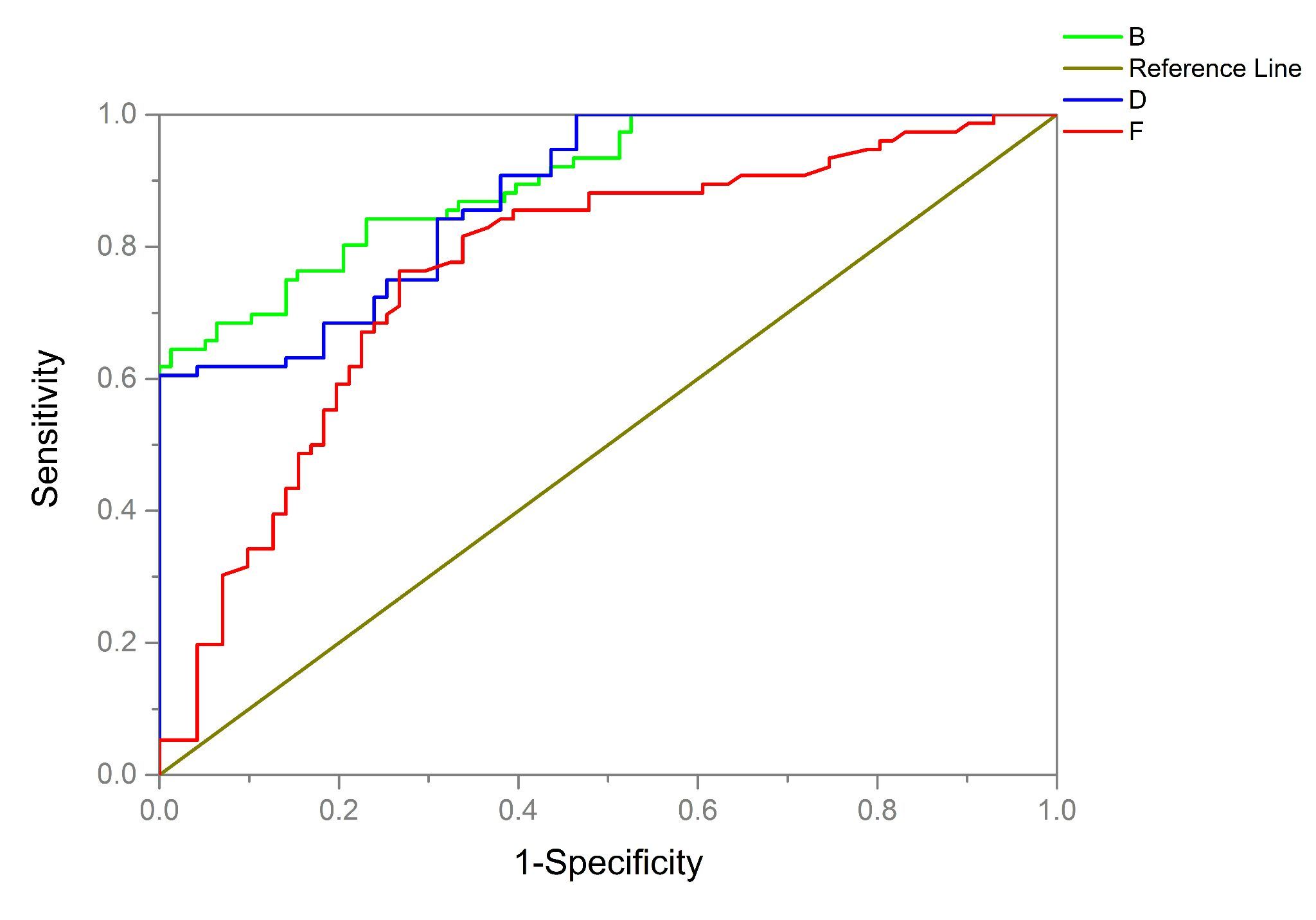
该曲线下的积分面积(AUC)能反映分类器正确分类的统计概率,其值越接近1说明该算法效果越好。
- AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
参考:什么是ROC曲线?为什么要使用ROC?以及 AUC的计算 - 云+社区 - 腾讯云
ROC曲线具体是怎么得到的可以参考:ROC及AUC计算方法及原理_糖葫芦君的博客-CSDN博客_roc
下面介绍ROC曲线的Python实现:
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve, auc, mean_squared_error, accuracy_score
import math
def check_fit(truth, prob):
"""
truth: 真实的值
prob: 预测的值
"""
fpr, tpr, _ = roc_curve(truth, prob) # drop_intermediate:(default=True)
roc_auc = auc(fpr, tpr) # 计算auc值,roc曲线下面的面积 等价于 roc_auc_score(truth,prob)
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([-0.1, 1.05])
plt.ylim([-0.1, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
print('results are RMSE, accuracy, ROC')
predics = [1 if i>=0.5 else 0 for i in prob]
print(math.sqrt(mean_squared_error(truth, prob)), accuracy_score(truth, predics), roc_auc)7.Python分类预测模型的特点
