之前写一个作业样本不均衡问题。然后查了很多文章都说要更换评价指标,不能再使用准确率了,要计算F值。我看了一下F值怎么计算,看了挺多文章的,但是感觉说的比较迷惑,或者说法比较拗口。最后还是自己再总结一个。
查准率、查全率、F值
我们平时对于一个模型预测的准不准,我们最先想到的是用准确率(Accuracy)进行评价。
A = t r u e t o t a l A = \frac{true}{total} A=totaltrue
这个虽然常用,但不能满足所有任务的需求。
所以我们可以引入查准率和查全率。
-
查准率(Precision):某一分类你预测对了多少个。
P = 预测对的某一类 你预测的某一类 P = \frac{预测对的某一类}{你预测的某一类} P=你预测的某一类预测对的某一类
-
查全率(Recall):某一分类你预测出来多少个。
R = 预测对的某一类 样本中的某一类 R = \frac{预测对的某一类}{样本中的某一类} R=样本中的某一类预测对的某一类
举个例子:
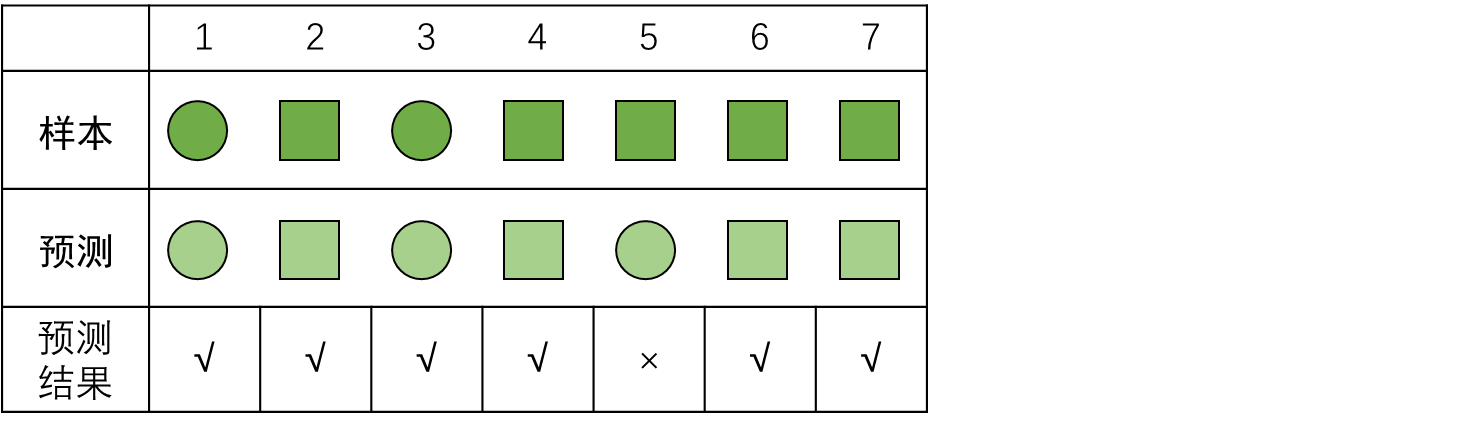
计算○的:
P ○ = 2 3 P_○ = \frac{2}{3} P○=32
R ○ = 2 2 R_○ = \frac{2}{2} R○=22
查准率和查全率二者不可得兼。大概是下图这样的图像。不信你可以自己算一下。对于不同的实验曲线的形状可能略有不同。

精确率高,意味着分类器要尽量在 “更有把握” 的情况下才将样本预测为正样本, 这意味着精确率能够很好的体现模型对于负样本的区分能力,精确率越高,则模型对负样本区分能力越强。
召回率高,意味着分类器尽可能将有可能为正样本的样本预测为正样本,这意味着召回率能够很好的体现模型对于正样本的区分能力,召回率越高,则模型对正样本的区分能力越强。
从上面的分析可以看出,精确率与召回率是此消彼长的关系, 如果分类器只把可能性大的样本预测为正样本,那么会漏掉很多可能性相对不大但依旧满足的正样本,从而导致召回率降低。
而F值是二者的综合:
F ( k ) = ( 1 + k ) × P × R k 2 × P + R , 其中 k > 0 F(k) =\frac{ ( 1 + k ) \times P \times R} { k^2 \times P + R },\quad 其中k>0 F(k)=k2×P+R(1+k)×P×R,其中k>0
其中 k k k可以看做一个权值对待:
- k > 1 k>1 k>1就是查全率有更大影响,
- k < 1 k<1 k<1查准率有更大影响。
而我们常用的是 F 1 F1 F1值, F ( 1 ) F(1) F(1)的意思, k = 1 k=1 k=1,此时
F ( 1 ) = 2 × P × R P + R F(1) = \frac {2 \times P \times R} { P + R } F(1)=P+R2×P×R
对于上边的例子F1值就是: F 1 ○ = 2 × 2 3 × 3 2 2 3 + 3 2 F1_○ = \frac{2\times \frac{2}{3} \times \frac{3}{2}}{ \frac{2}{3} + \frac{3}{2}} F1○=32+232×32×23
对于二分类问题
道理就是我上边说的那一段,但是常规大家介绍的时候都喜欢写什么TP TN之类的字母表示,看得我头晕。所以如果上边例子看懂了的话,可以直接跳过二分类,看多分类就可以了。
二分类呢就是我上面举的那个例子。别人写F值的计算一般都喜欢用一个混淆矩阵来表示。
我们需要建立以下几个量的混淆矩阵:
- 真正例(True Positive,TP):预测类别为正例,实际是正例,预测对了目标样本。
- 假正例(False Positive,FP):预测类别为正例,实际是负例,预测是目标,但预测错了。
- 假负例(False Negative,FN):预测类别为负例,实际是正例,没预测出来的目标样本。
- 真负例(True Negative,TN):预测类别为负例,实际是负例,。
还是上面那个例子,我们讲说圆圈是正例,方块是负例。现在就可以转化成下图这样。
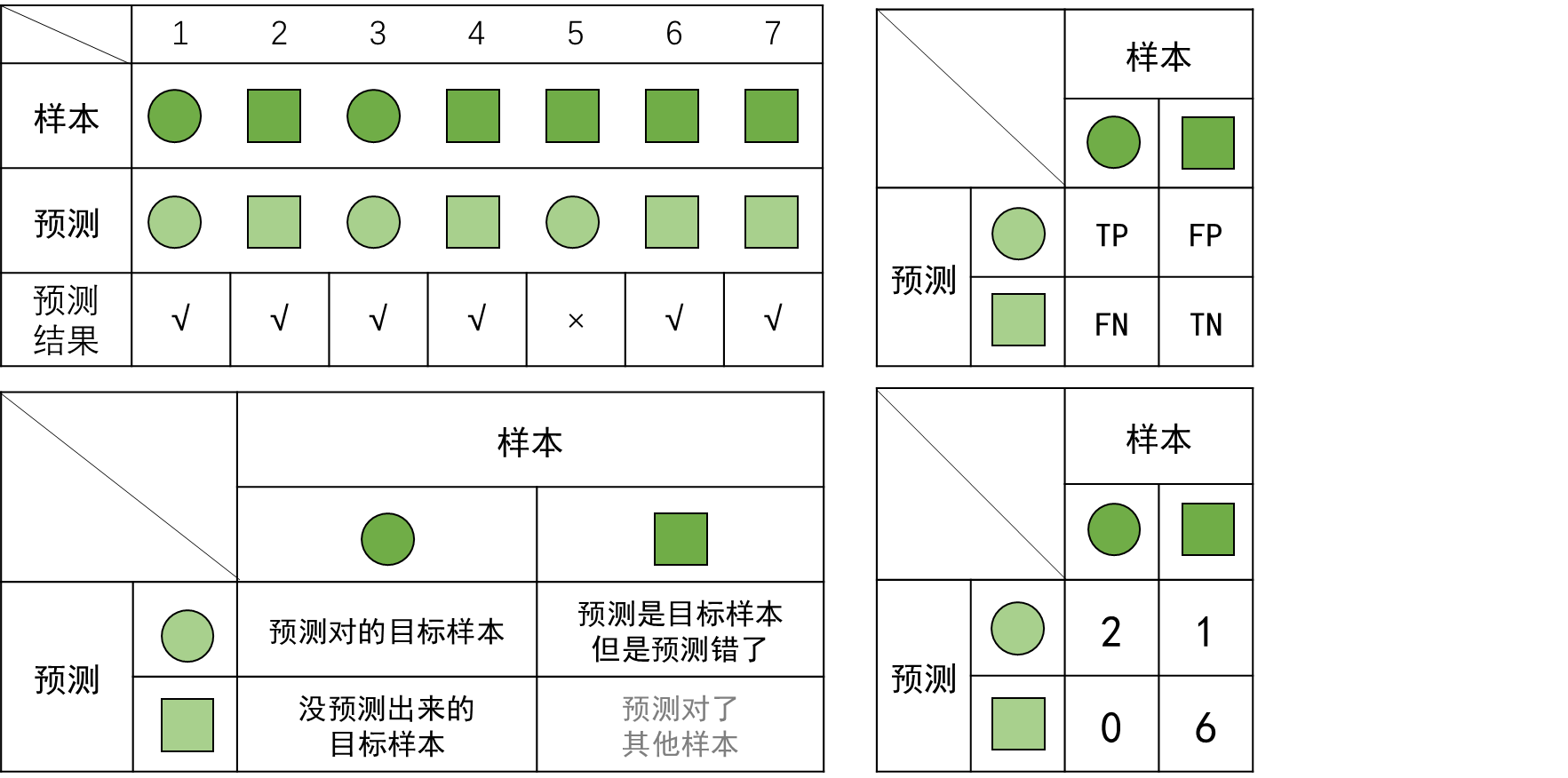
字母真的很让人迷惑!!!所以我搞了文字版。TN那里灰色的,因为计算F值不需要那一项。
此时:
-
准确率: A = T P + T N TP+FP+FN+TN A = \frac{T P+T N}{\text { TP+FP+FN+TN }} A= TP+FP+FN+TN TP+TN
-
精确率: P = T P T P + F P P=\frac{T P}{T P+F P} P=TP+FPTP
-
召回率: R = T P T P + F N R=\frac{T P}{T P+F N} R=TP+FNTP
-
F1值: F 1 = 2 × P × R P + R F 1=\frac{2 \times P \times R}{P+R} F1=P+R2×P×R
多分类
为什么我说可以不看二分类那一段,因为那一段真的四个字母表示特别容易让人迷惑。并且它跟多分类也衔接不上。因为在多分类里强行用简单的正例负例来说真的是很怪异。
不需要你再翻回去了,我直接把那个内容搬下来了。
-
查准率(Precision):某一分类你预测对了多少个。
P = 预测对的某一类 你预测的某一类 P = \frac{预测对的某一类}{你预测的某一类} P=你预测的某一类预测对的某一类
-
查全率(Recall):某一分类你预测出来多少个。
R = 预测对的某一类 样本中的某一类 R = \frac{预测对的某一类}{样本中的某一类} R=样本中的某一类预测对的某一类
上边提到的F值是关于二分类。多分类的时候就需要用到宏F值(F-macro)和微F值(F-micro)。
-
宏F值:
方法一: 求取每一类的F值之后求平均值。
F M a c r o = 1 n ∑ i − 1 n F 1 ( i ) F_{Macro} = \frac{1}{n}\sum_{i-1}^n F1^{(i)} FMacro=n1∑i−1nF1(i)
方法二: 还有一种说法是先分别计算查准率和查全率,再进行平均,使用平均的查准率查全率计算宏F值。
F M a c r o = k × P a v e × R a v e k 2 × P a v e + R a v e F_{Macro} = \frac {k \times P_{ave} \times R_{ave} } { k^2 \times P_{ave} + R_{ave}} FMacro=k2×Pave+Ravek×Pave×Rave
-
微F值:这样每一类的预测结果都加起来之后再计算查准率、查全率、F值。
F M i c r o = k × P s u m × R s u m k 2 × P s u m + R s u m F_{Micro} = \frac {k \times P_{sum} \times R_{sum}} { k^2 \times P_{sum} + R_{sum}} FMicro=k2×Psum+Rsumk×Psum×Rsum
注意: 关于宏F1两种计算方法最终结果是不一样的。
在Scikit-learn(以前称为scikits.learn,也称为sklearn)的包中,使用的是第一种方式。
两种方式的使用争议一直存在。
不过在“Training algorithms for linear text classifiers”1中,作者指出,macro-F1是所有类中F1-score的平均值,即第一种方式才是macro-F1的计算方式。论文Macro F1 and Macro F12对两种macro的方法进行简单分析,第二种方式对错误的分布不太敏感,这一点有点像micro-F1,论文作者也推荐方法一3 4 5 6。
计算
我们还是计算F1为例:

| TP 预测对○ | FP 预测是○,但是预测错了 | FN 没预测出来的○ |
|---|---|---|
| 2 | 1 | 1 |
| TP 预测对□ | FP 预测是□,但是预测错了 | FN 没预测出来的□ |
|---|---|---|
| 4 | 0 | 1 |
| TP 预测对△ | FP 预测是△,但是预测错了 | FN 没预测出来的△ |
|---|---|---|
| 2 | 1 | 0 |
我是手算的,如果你算的结果和我不一样,可能是我算错了。
微F1
总和:
| TP 预测对 | FP 预测,但是预测错了 | FN 没预测出来的 |
|---|---|---|
| 8 | 2 | 2 |
P s u m = 8 8 + 2 = 4 5 R s u m = 8 8 + 2 = 4 5 F M i c r o = 2 × P s u m × R s u m P s u m + R s u m = 2 × 4 5 × 4 5 4 5 + 4 5 = 4 5 \begin{aligned} &P_{sum} = \frac{8}{8+2} = \frac 4 5\\ \\ &R_{sum} = \frac{8}{8+2} = \frac 4 5\\ \\ &F_{Micro} = \frac {2 \times P_{sum} \times R_{sum}} { P_{sum} + R_{sum} } = \frac {2 \times \frac 4 5 \times \frac 4 5} { \frac 4 5 + \frac 4 5 } = \frac 4 5 \end{aligned} Psum=8+28=54Rsum=8+28=54FMicro=Psum+Rsum2×Psum×Rsum=54+542×54×54=54
宏F1
计算方法1
P ○ = 2 2 + 1 = 2 3 R ○ = 2 2 + 1 = 2 3 F 1 ○ = 2 × P ○ × R ○ P ○ + R ○ = 2 3 P □ = 4 4 + 0 = 1 R □ = 4 4 + 1 = 4 5 F 1 □ = 2 × P □ × R □ P □ + R □ = 8 9 P △ = 2 2 + 1 = 2 3 R △ = 2 2 + 0 = 1 F 1 △ = 2 × P △ × R △ P △ + R △ = 4 5 \begin{aligned} &P_○=\frac{2}{2+1} = \frac{2}{3} &R_○=\frac{2}{2+1} = \frac{2}{3} \quad &F1_○=\frac{2 \times P _○\times R_○}{P_○+R_○} = \frac{2}{3} \\ \\ & P_□=\frac{4}{4+0} = 1 &R_□=\frac{4}{4+1} = \frac{4}{5} \quad & F1_□=\frac{2 \times P_□ \times R_□}{P_□+R_□} = \frac{8}{9} \\ \\ &P_△=\frac{2}{2+1} = \frac{2}{3} &R_△=\frac{2}{2+0} = 1 \quad &F1_△=\frac{2 \times P_△ \times R_△}{P_△+R_△} = \frac{4}{5} \end{aligned} P○=2+12=32P□=4+04=1P△=2+12=32R○=2+12=32R□=4+14=54R△=2+02=1F1○=P○+R○2×P○×R○=32F1□=P□+R□2×P□×R□=98F1△=P△+R△2×P△×R△=54
F 1 m a c r o = F 1 ○ + F 1 □ + F 1 △ 3 = 106 135 F1_{macro} = \frac{F1_○+F1_□+F1_△}{3} = \frac{106}{135} F1macro=3F1○+F1□+F1△=135106
计算方法2
P ○ = 2 2 + 1 = 2 3 R ○ = 2 2 + 1 = 2 3 P □ = 4 4 + 0 = 1 R □ = 4 4 + 1 = 4 5 P △ = 2 2 + 1 = 2 3 R △ = 2 2 + 0 = 1 \begin{aligned} &P_○=\frac{2}{2+1} = \frac{2}{3} &R_○=\frac{2}{2+1} = \frac{2}{3} \quad\\ \\ & P_□=\frac{4}{4+0} = 1 &R_□=\frac{4}{4+1} = \frac{4}{5} \quad \\ \\ &P_△=\frac{2}{2+1} = \frac{2}{3} &R_△=\frac{2}{2+0} = 1 \quad \end{aligned} P○=2+12=32P□=4+04=1P△=2+12=32R○=2+12=32R□=4+14=54R△=2+02=1
P a v e = P ○ + P □ + P △ = 7 9 R a v e = R ○ + R □ + R △ = 37 45 F 1 m a c r o = 2 × P a v e × R a v e P a v e + R a v e = 2 × 7 9 × 37 45 7 9 + 37 45 = 259 324 \begin{aligned} &P_{ave}=P_○+P_□+P_△=\frac 7 9 \\ \\ &R_{ave}=R_○+R_□+R_△=\frac{37} {45} \\ \\ &F1_{macro} = \frac {2 \times P_{ave} \times R_{ave} } { P_{ave} + R_{ave}} = \frac {2 \times \frac 7 9 \times \frac{37} {45} } { \frac 7 9 +\frac{37} {45} } = \frac {259}{324} \end{aligned} Pave=P○+P□+P△=97Rave=R○+R□+R△=4537F1macro=Pave+Rave2×Pave×Rave=97+45372×97×4537=324259
如何选择Micro F1 & Macro F1
Macro 相对 Micro 而言,小类别起到的作用更大。
举个例子7,对于一个四分类问题有:
分类 TP FP class A 1 1 class B 10 90 class C 1 TP 1 class D 1 TP 1 那么使用方法二计算有:
P A = P C = P D = 0.5 , P B = 0.1 P macro = 0.5 + 0.1 + 0.5 + 0.5 4 = 0.4 P micro = 1 + 10 + 1 + 1 2 + 100 + 2 + 2 = 0.123 \begin{gathered} P_{A}=P_{C}=P_{D}=0.5, P_{B}=0.1 \\ \\ P_{\text {macro }}=\frac{0.5+0.1+0.5+0.5}{4}=0.4 \\ \\ P_{\text {micro }}=\frac{1+10+1+1}{2+100+2+2}=0.123 \end{gathered} PA=PC=PD=0.5,PB=0.1Pmacro =40.5+0.1+0.5+0.5=0.4Pmicro =2+100+2+21+10+1+1=0.123
我们看到,对于 Macro 来说, 小类别相当程度上拉高了 Precision 的值,而实际上, 并没有那么多样本被正确分类,考虑到实际的环境中,真实样本分布和训练样本分布相同的情况下,这种指标明显是有问题的, 小类别起到的作用太大,以至于大样本的分类情况不佳。而对于 Micro 来说,其考虑到了这种样本不均衡的问题, 因此在这种情况下相对较佳。
如果你的类别比较均衡,则随便;如果你认为大样本的类别应该占据更重要的位置, 使用Micro;如果你认为小样本也应该占据重要的位置,则使用 Macro;如果 Micro << Macro , 则意味着在大样本类别中出现了严重的分类错误;如果 Macro << Micro , 则意味着小样本类别中出现了严重的分类错误。
Weight F1
Weighted F值 是Macro 算法的改良版,顾名思义就是加权版本的F值计算。是为了解决Macro中没有考虑样本不均衡的问题。
既然是Macro F值计算的改良版,那肯定也是有两种计算方法:
-
方法一:将各类别的F值乘以该类在总样本中的占比进行加权计算。
F W e i g h t e d = ∑ i − 1 n w ( i ) F ( i ) F_{Weighted} = \sum_{i-1}^n w^{(i)}F^{(i)} FWeighted=∑i−1nw(i)F(i)
-
方法二:在计算查准率和查全率的时候,各个类别的查准率和查全率要乘以该类在总样本中的占比进行加权计算。
F W e i g h t e d = k × P w e i × R w e i k 2 × P w e i + R w e i F_{Weighted} = \frac {k \times P_{wei} \times R_{wei} } { k^2 \times P_{wei} + R_{wei}} FWeighted=k2×Pwei+Rweik×Pwei×Rwei
P w e i = w ○ P ○ + w □ P □ + w △ P △ P_{wei}=w_○P_○+w_□P_□+w_△P_△ Pwei=w○P○+w□P□+w△P△
R w e i = w ○ R ○ + w □ R □ + w △ R △ R_{wei}=w_○R_○+w_□R_□+w_△R_△ Rwei=w○R○+w□R□+w△R△
计算
我们还是计算F1为例:
| TP 预测对 | FP 预测是,但是预测错了 | FN 没预测出来的 | 样本比例 | |
|---|---|---|---|---|
| ○ | 2 | 1 | 1 | 30% |
| □ | 4 | 0 | 1 | 50% |
| △ | 8 | 2 | 2 | 20% |
计算方法1
P ○ = 2 2 + 1 = 2 3 R ○ = 2 2 + 1 = 2 3 F 1 ○ = 2 × P ○ × R ○ P ○ + R ○ = 2 3 P □ = 4 4 + 0 = 1 R □ = 4 4 + 1 = 4 5 F 1 □ = 2 × P □ × R □ P □ + R □ = 8 9 P △ = 2 2 + 1 = 2 3 R △ = 2 2 + 0 = 1 F 1 △ = 2 × P △ × R △ P △ + R △ = 4 5 \begin{aligned} &P_○=\frac{2}{2+1} = \frac{2}{3} &R_○=\frac{2}{2+1} = \frac{2}{3} \quad &F1_○=\frac{2 \times P _○\times R_○}{P_○+R_○} = \frac{2}{3} \\ \\ & P_□=\frac{4}{4+0} = 1 &R_□=\frac{4}{4+1} = \frac{4}{5} \quad & F1_□=\frac{2 \times P_□ \times R_□}{P_□+R_□} = \frac{8}{9} \\ \\ &P_△=\frac{2}{2+1} = \frac{2}{3} &R_△=\frac{2}{2+0} = 1 \quad &F1_△=\frac{2 \times P_△ \times R_△}{P_△+R_△} = \frac{4}{5} \end{aligned} P○=2+12=32P□=4+04=1P△=2+12=32R○=2+12=32R□=4+14=54R△=2+02=1F1○=P○+R○2×P○×R○=32F1□=P□+R□2×P□×R□=98F1△=P△+R△2×P△×R△=54
F 1 W e i g h t e d = w ○ F 1 ○ + w □ F 1 □ + w △ F 1 △ = 2 3 × 30 % + 8 9 × 50 % + 4 5 × 20 % = 181 225 F1_{Weighted} =w_○F1_○+w_□F1_□+w_△F1_△= \frac 2 3 \times 30\% + \frac 8 9 \times 50\% + \frac 4 5 \times 20\%= \frac {181}{225} F1Weighted=w○F1○+w□F1□+w△F1△=32×30%+98×50%+54×20%=225181
计算方法2
P ○ = 2 2 + 1 = 2 3 R ○ = 2 2 + 1 = 2 3 P □ = 4 4 + 0 = 1 R □ = 4 4 + 1 = 4 5 P △ = 2 2 + 1 = 2 3 R △ = 2 2 + 0 = 1 \begin{aligned} &P_○=\frac{2}{2+1} = \frac{2}{3} &R_○=\frac{2}{2+1} = \frac{2}{3} \quad\\ \\ & P_□=\frac{4}{4+0} = 1 &R_□=\frac{4}{4+1} = \frac{4}{5} \quad \\ \\ &P_△=\frac{2}{2+1} = \frac{2}{3} &R_△=\frac{2}{2+0} = 1 \quad \end{aligned} P○=2+12=32P□=4+04=1P△=2+12=32R○=2+12=32R□=4+14=54R△=2+02=1
P w e i = w ○ P ○ + w □ P □ + w △ P △ = 2 3 × 30 % + 1 × 50 % + 2 3 × 20 % = 5 6 R w e i = w ○ R ○ + w □ R □ + w △ R △ = 2 3 × 30 % + 4 5 × 50 % + 1 × 20 % = 4 5 F 1 W e i g h t e d = 2 × P w e i × R w e i P w e i + R w e i = 2 × 5 6 × 4 5 5 6 + 4 5 = 40 49 \begin{aligned} &P_{wei}=w_○P_○+w_□P_□+w_△P_△ = \frac 2 3 \times 30\% + 1 \times 50\% + \frac 2 3 \times 20\%= \frac 5 6\\ \\ &R_{wei}=w_○R_○+w_□R_□+w_△R_△ =\frac 2 3 \times 30\% + \frac 4 5\times 50\% + 1\times 20\%= \frac 4 5 \\ \\ &F1_{Weighted} = \frac {2 \times P_{wei} \times R_{wei} } { P_{wei} + R_{wei}} = \frac {2 \times \frac 5 6 \times \frac 4 5 } { \frac 5 6 + \frac 4 5 } = \frac {40}{49} \end{aligned} Pwei=w○P○+w□P□+w△P△=32×30%+1×50%+32×20%=65Rwei=w○R○+w□R□+w△R△=32×30%+54×50%+1×20%=54F1Weighted=Pwei+Rwei2×Pwei×Rwei=65+542×65×54=4940
Lewis, David D., et al. “Training algorithms for linear text classifiers.” SIGIR. Vol. 96. 1996. 243199.243277 (acm.org) ↩︎
Multi-Class Metrics Made Simple, Part I: Precision and Recall | by Boaz Shmueli | Towards Data Science ↩︎
Multi-Class Metrics Made Simple, Part II: the F1-score | by Boaz Shmueli | Towards Data Science ↩︎