1. 过拟合和欠拟合
欠拟合:是指模型没有能够很好的表现数据的结构,而出现的拟合度不高的情况。
过拟合:是指模型过分的拟合训练样本,但对测试样本预测准确率不高的情况,也就是说模型泛化能力很差。
欠拟合
数据特征少 ---------> 升维(特征扩展)(马赛克,曝光度,增加噪声)
数据量少 ---------> 获取更多的数据
模型过于简单 --------> 迁移学习,使用更复杂的模型
过拟合
数据特征多-------->降维(PCA,SVD),筛选特征,正则化 ,droupout
特征数据范围差距大---------->数据缩放(归一化,标准化)
模型过于复杂 ------------->梯度爆炸,迁移学习 ,梯度剪切:梯度阈值(在保证模型准确率下降不多的情况下,大幅度减少模型参数),正则化:L1
2. 梯度消失和梯度爆炸
梯度消失:经过神经网络计算后,梯度衰减为0的情况
梯度爆炸:经过神经网络计算后,梯度变得无限大,超过了运算范围
梯度消失与梯度爆炸其实是一种情况,两种情况下梯度消失经常出现:
一是在深层网络中,采用了不合适的损失函数,梯度缩减为0,比如sigmoid。
二是梯度爆炸一般出现在深层网络和权值初始化值太大的情况下。
梯度消失解决办法:
1.更换激活函数 sigmoid---->relu
2.残差学习 resnet
3.batchnorm:对神经网络隐藏层做特征缩放,提高精确度。
梯度爆炸:
1.梯度剪切:Dropout
2.正则化:L1正则化,L2正则化
一般情况下,对于同一组训练数据,利用不同的神经网络训练之后,求其输出的平均值可以减少过拟合。Dropout就是利用这个原理,每次丢掉一半左右的隐藏层神经元,相当于在不同的神经网络上进行训练,这样就减少了神经元之间的依赖性,即每个神经元不能依赖于某几个其它的神经元 ,使神经网络更加能学习到与其它神经元之间的更加健壮robust(鲁棒性)的特征。另外Dropout不仅减少overfitting,还能提高准确率。
总之,正则化是通过给cost函数添加正则项的方式来解决过拟合,Dropout是通过直接修改神经网络的结构来解决过拟合。
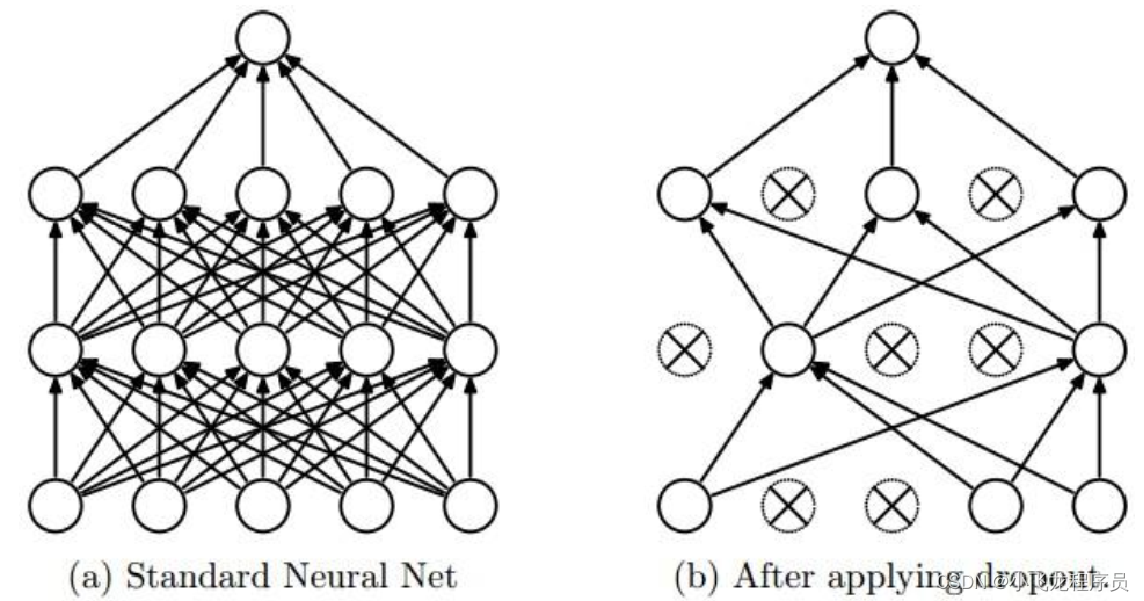
注意:不能同时使用正则化和Dropout减少过拟合,正则化减少特征,或特征变为0,而dropout也是减少特征的。所以不能同时使用。
建议:一般都可以使用Dropout解决过拟合问题
回归算法中使用L2范数相比于Softmax分类器,更加难以优化
对于回归问题,首先考虑是否可以转化为分类问题,比如:用户对于商品的评分,可以考虑将得分结果分成1~5分,这样就变成了一个分类问题。
如果实在没法转化为分类问题的,那么使用L2范数的时候要非常小心,比如在L2范数之前不要使用Dropout。
一般建议使用L2范数或者Dropout来减少神经网络的过拟合
激活函数总结:激活函数包括sigmoid,tanh,relu,softmax。sigmoid激活函数采用缺值方式进行分类,而softmax多分类采用最大概率进行分类。sigmoid激活函数,可以解决二分类问题,但对于多分类问题,sigmoid不能解决,由于其值域为[0,0.25],其代价函数引起梯度消失;而tanh激活函数其值域为[0,1],较优于sigmoid激活函数,但也容易引起梯度消失;relu激活函数在(0,+无穷)不易引起梯度消失,而在(-无穷,0)值为0,从而引出leaky relu激活函数;而softmax函数:f(x)=ln(e^x+1),用于多分类神经网络输出。
3. 梯度下降算法
梯度下降算法包括:批量梯度下降(Batch Gradient Descent,BGD)、小批量梯度下降(mini-BGD)、随机梯度下降(Stochastic Gradient Descent,SGD).
批量梯度下降(BGD):每次迭代更新时,计算m个样本的梯度做梯度下降(总样本数为m)
优点:1.每次计算整个数据集梯度来更新参数
2.处理大型数据时速度很慢,甚至可能导致内存溢出
3.计算量比SGD大
4.在凸面误差曲面中可以收敛得到全局最优值。
随机梯度下降(SGD):每次迭代更新时,计算一个样本的梯度做梯度下降(总样本数为m)
优点:1.每次使用单个样本进行训练
2.处理大型数据时,速度更快
3.频繁的参数更新使得参数间具有高方差
小批量梯度下降(mini-BGD):每次迭代更新时,计算n(1<n<m)个样本的梯度做梯度下降(总样本数为m)
优点:1.每次参数更新都使用多个训练样本进行计算
2.可以减少参数更新的波动,最终得到效果更好和更稳定的收敛
总之,小批量梯度下降,是对批量梯度下降以及随机梯度下降的一个折中办法。其思想是:每次迭代 使用 ** batch_size** 个样本来对参数进行更新
每次选取n个数据作为下降计算的数据(1<n<m),n取值范围最好为50-255范围内。
优点:通过矩阵运算,每次在一个batch上优化神经网络参数并不会比单个数据慢太多。每次使用一个batch可以大大减小收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。(比如上例中的30W,设置batch_size=100时,需要迭代3000次,远小于SGD的30W次)可实现并行化
缺点:batch_size的不当选择可能会带来一些问题。
4. 梯度下降算法优化器
4.1 momentum 动量优化器
动量优化器模仿小球,从A点滚动到B点的时候,小球带有一定的初速度,在当前初速度下继续加速下降,小球会越滚越快,更快的奔向谷底。momentum 动量法就是模拟这一过程来加速神经网络的优化的。
原始的梯度下降公式
w_new=w−αΔw
α为学习率,w为权重
动力优化器公式为
v_t=βv_t−1+αΔw
w_new=w−v_t
β为调整参数,一般设置为0.9
记录上一次的运动量提供给当前梯度下降
4.2 Adagrad优化器
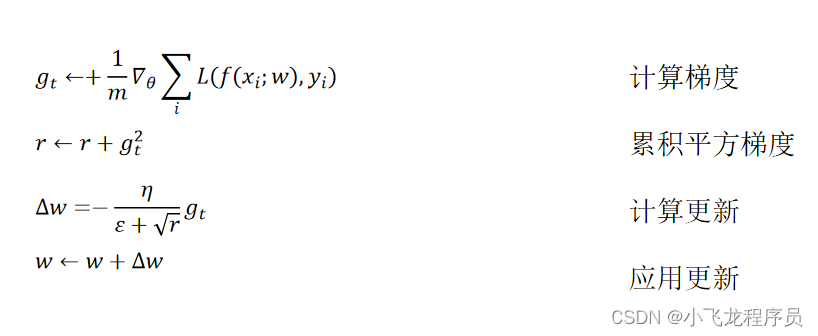
从Adagrad优化算法中可以看出,随着算法不断迭代, r会越来越大,整体的学习率会越来越小。这样做的原因是随着更新次数的增大,我们希望学习率越来越慢。因为我们认为在学习率的最初阶段,我们距离损失函数最优解还很远,随着更新次数的增加,越来越接近最优解,所以学习率也随之变慢。
优点:学习率自动更新,随着更新次数增加,学习率随之变慢。
缺点:分母会不断累积,这样学习率就会后所并最终变得非常小,算法会失去效用。
4.3 RMSprop优化器
RMSprop优化器是一种改进的Adagrad优化器,通过引入一个衰减系数,让r每回合都都衰减一定的比例。
RMSprop优化器很好的解决了Adagrad优化器过早结束的问题,很合适处理非平稳目标,对于RNN网络效果很好。
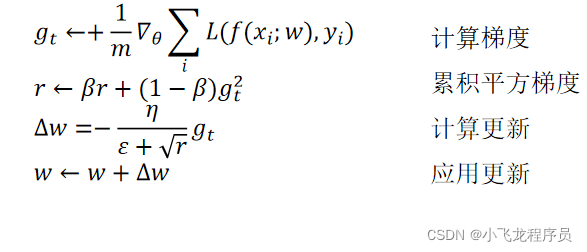
Adam( Adaptive Moment Estimation ):是从Adagrad、Adadelta上发展而来,Adam为每个待训练的变量,维护了两个附加的变量m_t和v_t:
m_t=β_1m_t−1+(1−β_1)g_t (mt-相当于变化的学习率)
v_t=β_2v_t−1+(1−β_2)g_t^2 (vt-动量)
其中t表示第t次迭代,g_t是本次计算出的梯度,从形式上来看m_t和v_t分别是梯度和梯度平方的移动均值。从统计意义上看,m_t和v_t是梯度的一阶矩(均值)和二阶矩(非中心方差)的估计,因此而得名。
| 梯度优化器算法 | 作用 | 区别 | 好处 |
|---|---|---|---|
| momentum梯度算法 | 指数加权平均数先平方再开方 | 添加了动力优化器;如果给了你一个初动量,那么你到达曲线最低点的速度是大于没有初动量的;下降的速度是普通梯度下降快10倍;momentum=0.9还可以更容易跳出局部最优解 | 占用极少内存 |
| rmsp算法 | 通过指数加权平均数和学习率控制梯度下降的 | 引入衰减系数,随着学习率变小,学习率衰减的比率也变小 | |
| adam算法 | 同时使用动量梯度算法和rmsq算法 | 结合了momentum和rmsp优化器优点,效果更好 |
5. batch归一化、dropout、正则化区别
batch归一化:主要对神经网络的输入层和隐藏层的z做归一化。
dropout:随机取消一些节点,削弱了神经元节点之间的联合适应性,增强了泛化能力,即剪枝,防止过拟合。
正则化:例如L1,L2正则化,防止过拟合。