宅家中看到Datawhale的学习号召,在大牛云集的群上找到了一个很佛系的小组,战战兢兢地开始了小白的深度学习之旅。感谢Datawhale、伯禹教育、和鲸科技,感谢课程制作者、组织者、各位助教以及其他志愿者!
2 梯度消失、梯度爆炸
2.1 概念
当神经网络的层数较多时,模型的参数容易随着指数增长而迅速减小至接近零(梯度消失)或迅速增加至非常大(梯度爆炸),使模型的稳定性变差。
2.2 参数初始化
这就使得初始化参数的设置成为多层神经网络的重要考虑因素。但在神经网络中,如果每个隐藏单元的权重参数都设置为相同的值,无论隐藏单元有多少,本质上都相当于只有一个隐藏单元在发挥作用。我们通常将神经网络的模型参数,在一个给定数值范围内,进行随机初始化。
pytorch中集成了许多通用的初始化参数方法,不同类型的layer采用的方法不同,一般不同自己去指定。本小节还介绍了Xavier随机初始化:假设某全连接层的输入个数为a,输出个数为b,Xavier随机初始化将使该层中权重参数的每个元素都随机采样于均匀分布
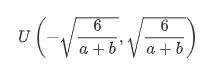 使用这种方法,每层输出的方差不该受该层输入个数影响,且每层梯度的方差也不该受该层输出个数影响。
使用这种方法,每层输出的方差不该受该层输入个数影响,且每层梯度的方差也不该受该层输出个数影响。
2.3 环境因素(偏移)
假设函数不改变,若输入发生偏移,即测试集看起来与训练集有着本质的不同(如卡通图片和照片),称作协变量偏移。标签偏移有些没看懂,期待大神更直白的解释。概念偏移指的是输出发生偏移,即对同一标签有着不同的表示,如不同地区人们把不同饮料(pop,soda,coke)叫做软饮料。这时需要建立一个机器翻译系统来解决概念偏移问题。
2.4 Kaggle房价问题
这一小节介绍了一个真正的数据分析案例——Kaggle房价预测,使用pytorch完成了读取数据集、预处理(缺失填充、标准化)、训练模型、K折交叉验证(数据集小时不使用)、模型选择、预测并提交结果的全部步骤。通过这一案例,让学习者简单地了解了机器学习的完整流程。
