- 1、欠拟合:是一种不能很好拟合数据的的现象。
导致结果:其会导致网络的训练的准确度不高,不能很好的非线性拟合数据,进行分类。
造成原因:这种现象很可能是网络层数不够多,不够深,导致其非线性不够好。从而对于少量样本能进行很好的拟合,而较多样本无法很好的拟合。其实,现在的深度比较少出现欠拟合现象。
解决方法:加深网络。
- 过拟合:是一种过度拟合训练样本,导致网络自身缺失了“泛化能力”,无法对训练样本之外的样本进行准确分类。
造成原因:可能是网络训练的时候进入到了网络极小值点。在其无法跳出极小值点时,则其就会出现过拟合。这个现象一般是网络层数深的时候比较常见。
解决方法:a、使用深度网络的加深,其网络参数也不断增加,增加速度大,可以使用dropout来进行抑制一些神经元,防止过拟合。
b、回想下我们的模型,假如我们采用梯度下降算法将模型中的损失函数不断减少,那么最终我们会在一定范围内求出最优解,最后损失函数不断趋近0。那么我们可以在所定义的损失函数后面加入一项永不为0的部分,那么最后经过不断优化损失函数还是会存在。其实这就是所谓的“正则化”。
下面这张图片就是加入了正则化(regulation)之后的损失函数。这里m是样本数目,landa(后面我用“t”表示,实在是打不出)表示的是正则化系数。
注意:当t(landa)过大时,则会导致后面部分权重比加大,那么最终损失函数过大,从而导致欠拟合
当t(landa)过小时,甚至为0,导致过拟合。
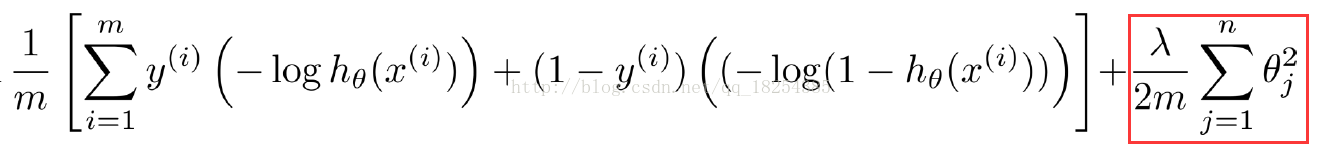
c、增加训练样本可以很好的防止过拟合。

- 梯度消失:是一种随着网络的训练,导致反向传播的损失loss变得越来越小,最后小到为0,这就会导致网络输入层前面的神经元学习不到任何特征,由于其每次训练变化的梯度都是0.其参数不会改变。这就使其失去了意义。
造成原因:这个主要是因为以前的网络使用的了sigmoid作为激活函数,其对于浅层的网络是适合的,但是对于深层的网络就容易导致梯度消失。具体可以参考: 深度神经网络为何很难训练,其是使用了Nielsen在《Neural Networks and Deep Learning》中通过实验说明了这种现象是普遍存在的。
解决方法:
a、2006年Hinton提出的逐层预训练方法,为了解决深层神经网络的训练问题,一种有效的手段是采取无监督逐层训练(unsupervised layer-wise training),其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,这被称之为“预训练”(pre-training);在预训练完成后,再对整个网络进行“微调”(fine-tunning)训练。
b、使用其他激活函数替代sigmoid函数。