考研之数据结构022_图的广度、深度优先遍历算法
一、广度优先遍历算法(BFS)
用邻接表存储的话,遍历序列是可变的,不唯一的。
邻接矩阵的表示唯一,广度优先遍历的序列是唯一的。
1、与树的广度优先遍历之间的联系
树是一种特殊的图。而树的广度优先遍历就是:层序遍历。
从树的广度优先遍历入手,看一下图的广度优先遍历的思想。
- 树的层序遍历思想:
从根节点出发:找到根节点相邻的所有节点(234),找到(234)相邻的所有节点。实际操作是:借用队列思想,先入根节点,然后出列的同时,将根节点的所有子树入队。依次出队并入所有子节点。直到队列为空。这样就可以一次逐层的找到所有节点。

- 图的广度优先遍历思想:
例如从2号出发,就可以找到1,和6节点,再从1和6出发,找到5,3,7节点。在访问5,3,7节点,找到48节点。
树和图的广度优先遍历有什么区别?
第一:不论是树还是图,在进行广度优先遍历的时候,我们都需要通过某一个结点, 找到与之相邻的其他节点。从而一层一层的往下找到。
- 树:找到相邻的结点就是找与之对应的孩子。
树不存在回路。 - 图:
图不一样了,可能出现环状,还有无向图,既可以正向也可以反向走。所以我们要对访问过的顶点进行标记,如果访问过直接跳过即可。
2、算法实现
广度优先遍历BFS要点:
1.找到与一个顶点相邻的所有顶点
2.标记哪些顶点被访问过
3.需要一个辅助队列
针对第一个点:可以利用两个操作就可以找到,与一个顶点相连接的所有的顶点。
第一个:==FistNeighbor(G,x)==:
求图G中顶点X的第一个邻接点,
若有则返回顶点号。
若X没有邻接点或图中不存在X,则返回-1
第二个:==NextNeighbor(G,x,y)==:
假设图G中顶点y是顶点X的一个邻接点,
返回除y之外顶点X的下一个邻接点的顶点号,
若y是x的最后一个邻接点,则返回-1
针对第二个点:
定义一个Bool型的数组标记每一个顶点,到底有没有被访问过


对于无向图,调用BFS函数的次数=连通分量树
连通分量:极大连通子图,就是说有几个不连在一起的图。
那么如下此图的连通分量就是:2

3、复杂度分析、
时间复杂度=访问结点的时间+访问所有边的时间。



4、广度优先生成树·
二、深度优先遍历算法(DFS)
1、与树的深度优先遍历之间的联系
图的深度优先遍历类似于树的先根遍历(根左右)

2、算法实现
创建一个数组【MAX_VERTEX_NUM】用来标记每一个顶点是否曾经被访问过(初始化为false)
过程:
1.先访问一个顶点结点,
2.访问完以后,将数组中改为true
3.再用一个循环来,依次检查和这个结点相邻的其他节点。
在循环里边进行 if判断是否被访问过,
如果没有则重新递归调用BFS函数。重复1——3过程。
如果调用过的是true,那么返回for循环继续进行if判断


2、时间复杂度:


3、深度优先生成树


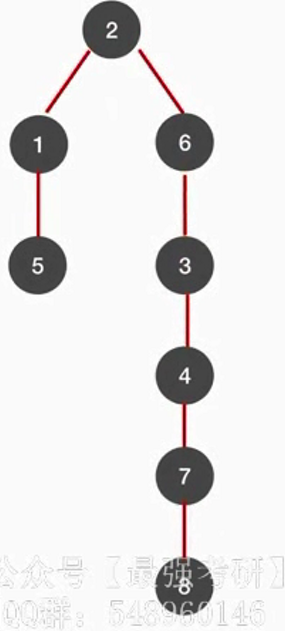
4、图的遍历和图的连通性


