作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121817220
目录
2.1 平均绝对误差(Mean Absolute Error,MAE)
2.2 均方误差(Mean Squared Error,MSE)
2.4 Adjusted R-Square (校正决定系数)
3.2 二分类: 正例(positive)和负例(negtive)
4.1 准确率/正确率(Accuracy):对角线上所有数值
4.2 错误率(error rate):对角线之外的所有数值
4.4 特效度(specificity):负例在对角线上的值
4.6 Accuracy、Precison、recall区别
第1章 模型评估简介
1.1 什么是模型评估
“所有模型都是坏的,但有些模型是有用的”。
我们建立模型之后,接下来就要去评估模型,确定这个模型是否‘有用’,是否“好用”。
模型评估分为训练前评估和训练后评估。
训练前评估是评估模型本身是否适合业务应用场景。
训练后评估是评估模型的训练效果。
1.2 模型评估的意义
在计算机科学特别是机器学习领域中,对模型的评估同样至关重要,只有选择与问题相匹配的评估方法,才能快速地发现模型选择或训练过程中出现的问题,迭代地对模型进行优化。
针对分类、排序、回归、序列预测等不同类型的机器学习问题,评估指标的选择也有所不同。
知道每种评估指标的精确定义、有针对性地选择合适的评估指标、更具评估指标的反馈进行模型调整,这些都是模型评估阶段的关键问题。
1.3 模型评估指标的分类
(1)线性回归的评估指标 (模拟数值输出)
- Mean Absolute Error(MAE) :平均绝对误差
- Mean Square Error(MSE) :平均方差
- R-Squared :R平方值
(2)数字分类的评估指标(数字数值输出)
准确率(Accuracy)、精确率(Precison)、召回率(Recall rate)、f1_score、混淆矩阵、ks、ks曲线、ROC曲线、psi。
1.4 影响模型指标的因素
(1)模型本身
(2)模型的超参数
(3)模型的训练
(4)数据集的分布
(5)数据集的预处理
第2章 线性回归的评估指标
2.1 平均绝对误差(Mean Absolute Error,MAE)
平均绝对误差就是指预测值与真实值之间平均相差多大 :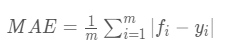
如下图所示:
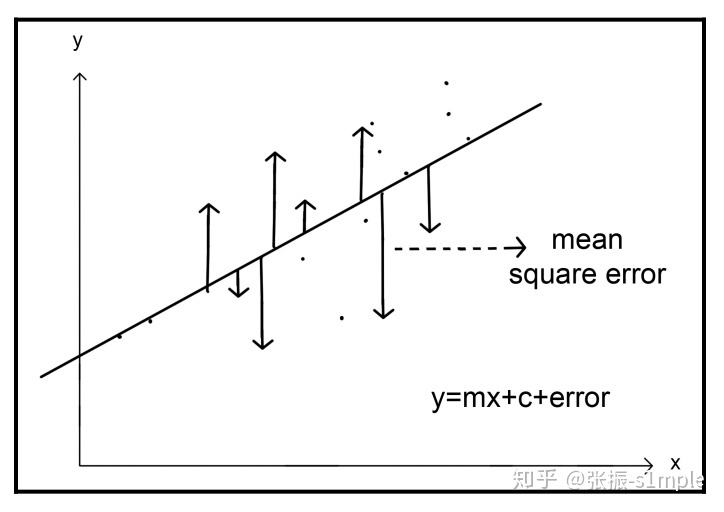
平均绝对误差能更好地反映预测值误差的实际情况。
MAE的值越小,说明预测模型描述实验数据具有更好的精确度。
2.2 均方误差(Mean Squared Error,MSE)
MSE与MAE类似,都是用fi - yi, 不同的是:一个是一次二次评分值,另一个是一次绝对值。
观测值与真值偏差的平方和与观测次数的比值:
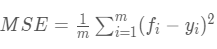
这也是线性回归中最常用的损失函数,线性回归过程中尽量让该损失函数最小。那么模型之间的对比也可以用它来比较。
MSE可以评价数据的变化程度。
MSE的值越小,说明预测模型描述实验数据具有更好的精确度。
2.3 R-square(决定系数)
分子为:预测数据和原始数据的误差,反应的是预测数据偏离真实数据的程度。
分母为:实际值距离平均值的距离或误差,反应的是原始数据偏离平均值的程度。
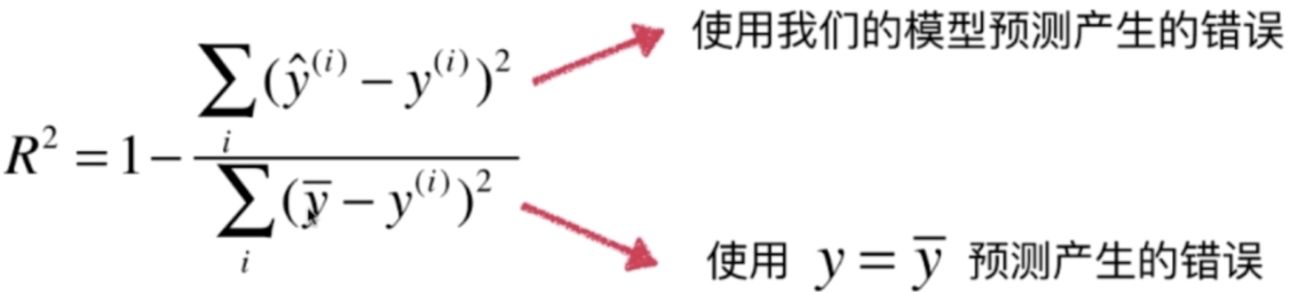
两者相除,反应的是:使用模型预测相对于使用平均值进行预测的误差的比值。
比值>1,采用模型预测,还不如使用平均值进行预测好。
比值=1,采用模型预测,与使用平均值预测一致。
比值<1,采用模型预测,比使用平均值预测要好,通常情况,比值都应该小于1,否则,这个模型预测还不如平均值预测。该值越小,表明模型在消除数据源本身的离散因素后的误差越小,则R2越接近于1。
2.4 Adjusted R-Square (校正决定系数)
n为样本数量,p为特征数量
- 消除了样本数量和特征数量的影响
第3章 分类指标的常见术语
3.1 分类的类型
(1)二分类
(2)多分类
3.2 二分类: 正例(positive)和负例(negtive)
这里首先介绍几个常见的模型评价术语。
现在假设我们的分类目标只有两类:正例(positive)和负例(negtive)
实际分类的情形有如下四种:
(1)True positives(TP):
被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数(样本数);
(2)True negatives(TN):
被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
上述两种情形都是分类正确的情形。
(3)False positives(FP):
被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
(4)False negatives(FN):
被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
上述两种情形,都是分类错误的情形。
3.3 混淆矩阵
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。
混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;
每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。
(1)二分类的混淆矩阵


对角线:真正例与真反都是预测正确的情形。
非对角线:FP, 把反例预测成了正例;FN, 把正例预测成了反例,都是预测错误的情形。
(2)多分类的混淆矩阵
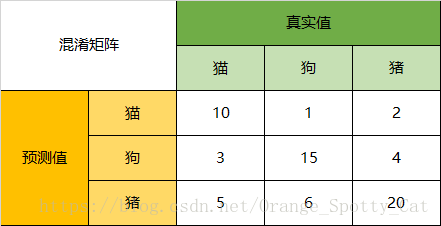
在上述案例中:
对角线的数值表明:预测值与真实值一致的情形。
非对角线的数值表明:预测值与真实值不一致的情形,预测错误的情形,并明确了出错的具体情形。
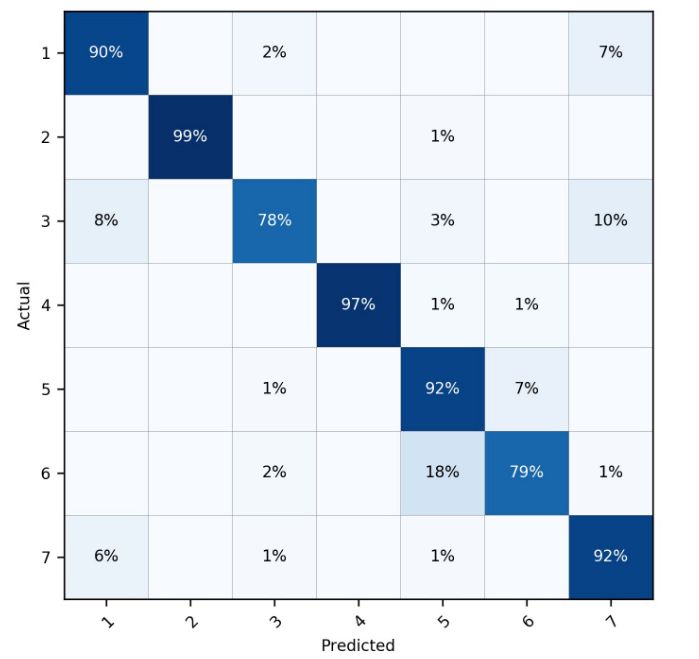
上述分类为7种分类
(1)对角线表明:各个单一分类,分类正确(率)的情形。
(2)非对角线:分类错误的各种情形
- 横向看:以实际类型为出发点,表明某一个实际类型,被分类成不同其他类别的比率。
- 纵向看:以预测结果为出发点,表明错误的预测成某一个类型的实际类型的比率。
第4章 数字分类的评估指标
4.1 准确率/正确率(Accuracy):对角线上所有数值
准确率是指分类正确的样本占总样个数的比例。
对于给定的测试集,分类模型正确分类的样本数与总样本数之比;
所有预测正确的样本/总的样本 =(TP+TN)/总样本数
正确率越高,分类器越好;
总的预测的正确率 = (10 + 15 + 20) / (10 + 1 + 2 + 3 + 15 + 4 + 5 + 6 + 20)
4.2 错误率(error rate):对角线之外的所有数值
错误率则与正确率相反,描述被分类器错分的比例。
error rate = (FP+FN)/总样本数,
对某一个实例来说,分对与分错是互斥事件,所以accuracy =1 - error rate;
总的错误= (1 + 2 + 3 + 4 + 5 + 6 ) / (10 + 1 + 2 + 3 + 15 + 4 + 5 + 6 + 20)
4.3 灵敏度(sensitive):正例在对角线上的值
TP:所有正例分类正确的个数
P:所有的正例总数
sensitive = TP/P,表示的是所有正例中被预测对的比例(有些正例会被分类成负例),衡量了分类器对正例的识别能力;
4.4 特效度(specificity):负例在对角线上的值
TN:所有负例分类正确的个数
N:所有的负例总数
specificity = TN/N,表示的是所有负例中被分对的比例(有些负例会被分类成正例),衡量了分类器对负例的识别能力;
4.5 精确率(Precison):
分类模型预测的正样本中有多少是真正的正样本;


猫的预测的精确率 = 10 / (10 +1 + 2)
狗的预测的精确率 = 15 / (15 +3 + 5)
猪的预测的精确率 = 20 / (20 + 5 + 6)
4.6 召回率(Recall rate)
指正确预测分类的正样本个数占真正的正样本数的比例。
猫的召回率 = 10 / (10 + 3 + 5) = 预测为猫,且为猫的数量/预测为猫的总数
狗的召回率 = 15 / (15 + 1 + 6) = 预测为狗,且为猫的数量/预测为狗的总数
猪的召回率 = 20/ (20 + 2 + 4) = 预测为猪,且为猫的数量/预测为猪的总数
4.6 Accuracy、Precison、recall区别
Accuracy:总体指标,是所有分类预测正确的数目/所有分类数目
Precison: 类别指标, 等于该类预测正确的数目/预测为该分类的数目,其目标是:宁可错过一千坏人,也不可冤枉一个好人。每杀一个,必定是坏人,尽可能精确,不要错选,模棱两可的尽可能放弃。
Recall: 类别指标,等于该类预测正确的数目/该类实际的数目,其目标是:宁可冤枉一千,不可错失一个。尽可能多选,模棱两可的尽可能选出。
很显然,Precison与Recall率指标正好是相反的。
有时候,为了增加召回率,会降低准确率。
有时候,为了增加准确率,会降低召回率。
4.7 f1_score:
在理想情况下,我们希望模型的精确率越高越好,同时召回率也越高越高。
但是,现实情况往往事与愿违,在现实情况下,精确率和召回率像是坐在跷跷板上一样,往往出现一个值升高,另一个值降低,那么,有没有一个指标来综合考虑精确率和召回率了,这个指标就是F值。

4.8 ROC曲线

第5章 案例
Precision, Recall and F1-Score...
precision recall f1-score support
finance 0.9180 0.8840 0.9007 1000
realty 0.9331 0.9200 0.9265 1000
stocks 0.8651 0.8530 0.8590 1000
education 0.9556 0.9480 0.9518 1000
science 0.8402 0.8830 0.8610 1000
society 0.8695 0.9260 0.8969 1000
politics 0.9025 0.8610 0.8813 1000
sports 0.9222 0.9600 0.9407 1000
game 0.9290 0.9030 0.9158 1000
entertainment 0.9212 0.9120 0.9166 1000
accuracy 0.9050 10000
macro avg 0.9056 0.9050 0.9050 10000
weighted avg 0.9056 0.9050 0.9050 10000
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121817220