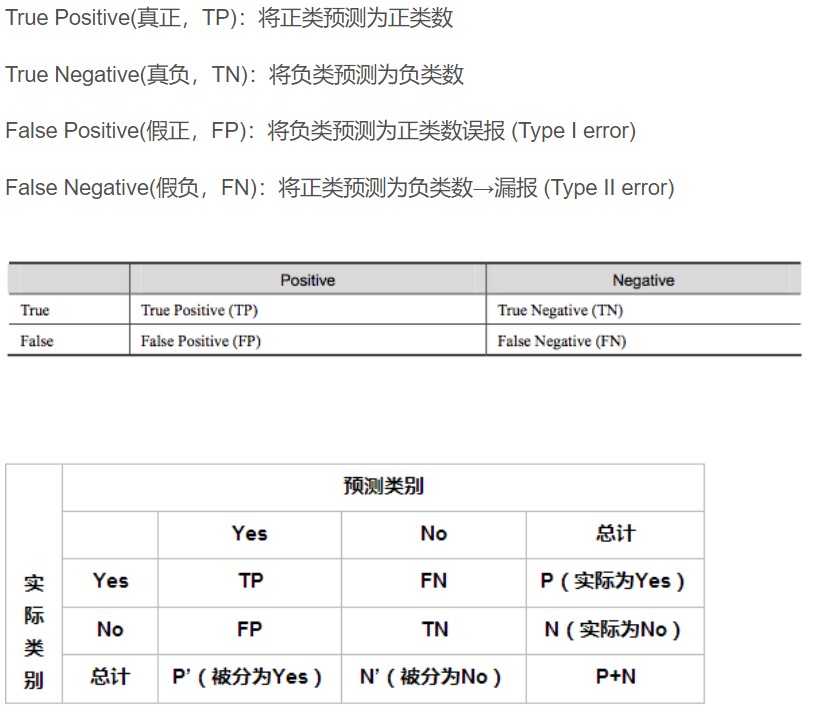
图片来源(图片来源:https://blog.csdn.net/quiet_girl/article/details/70830796)
1.准确率(Accuracy)
定义:对于给定的测试数据集,分类器正确分类的样本数与原数据集总样本数之比。
在正负样本不平衡的情况下,不能只用准确率作为评价指标。
Acc=(TP+TN)/(TP+TN+FP+FN)
2.精确率(Precision)
定义:“正确被分类的样本”占“实际检索到的总样本(分类后得到的样本总数)”的比例。
P=TP/(TP+FP)
3.召回率(Recall)
“正确分类的正样本”占“数据集中所有正样本总数”的比例。
Rec=TP/(TP+FN)=TP/P=sensitive
4.综合评价指标F-measure
精确率和召回率是相对的,需要综合起来评估。

图片来源(图片来源:https://blog.csdn.net/quiet_girl/article/details/70830796)
总结:准确率说明分类的结果是否准确或对不对;精确率说明结果的正样本中有多少是对的,是针对分类结果而言的;召回率说明正确分类的样本全不全,是针对原数据集而言的。
5.AP(Average precision)
检测目标采用mean Average Precision(mAP)作为评价指标,该指标综合考虑了Precision和Recall,具体做法如下:
(1)对于类别C,首先将算法输出的所有C类别的预测框,按置信度排序;
(2)选择top k个预测框,计算FP和TP,使得recall 等于1;
(3)计算Precision;
(4)重复2步骤,选择不同的k,使得recall分别等于0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0;
(5)将得到的11个Precision取平均,即得到AP;
(6)AP是针对单一类别的,mAP是将所有类别的AP求和,再取平均: mAP = 所有类别的AP之和 / 类别的总个数
编程实现参见:https://blog.csdn.net/leewanzhi/article/details/79690275
在测试中,需要将红色部分删除或更改为黄色部分:
from voc_eval import voc_eval print voc_eval('/home/mckee/darknet/results/{}.txt', '/home/mckee/darknet/scripts/VOCdevkit/VOC2007/Annotations/{}.xml', '/home/mckee/darknet/scripts/VOCdevkit/VOC2007/ImageSets/Main/test.txt', '1', '.')
#0.5或其它阈值
参考文献:
https://blog.csdn.net/u012089317/article/details/52156514
https://blog.csdn.net/quiet_girl/article/details/70830796