版权声明:转载请声明出处,谢谢! https://blog.csdn.net/qq_31468321/article/details/83247185
python 数据可视化
本文中主要使用matplotlib和Pandas对数据进行可视化
数据来源:爬取的BOOS直聘数据分析数据
数据展示
本文中针对以上数据,对salary,company_info,work_time,education这几个信息进行数据可视化,做出直方图和饼图

整体框架
先看一下使用的包吧
import re #正则表达式模块
import json #json模块
import pandas as pd #pandas模块
from nltk import FreqDist #nltk模块,用于分析词频
import matplotlib.pyplot as plt #matplotlib模块
from numpy import nan as NAN #numpy 模块
指定matplotlib中的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
初始化,构造DataFrame数据
由于数据是从爬虫返回的JSON文件中导出的,而爬虫返回的JSON文件中JSON格式不标准,需要对格式进行处理,然后再loads为Python对象
def __init__(self):
#读出文件中的内容
self.fp = open("boss_fp.json",'r',encoding='utf-8').read()
#在每一行数据中添加逗号,
self.fp_re = re.sub(r"}","},",self.fp)
#取出最后一个逗号,并在首尾添加方括号,构造为一个标准的JSON数据
self.fp_re = "["+self.fp_re[:-2]+"]"
#loads为Python对象数据
self.json_str = json.loads(self.fp_re)
self.df = pd.DataFrame(self.json_str)
数据清洗
在这个项目中,数据清洗时比较简单的,这里只从整体上来清洗,细节上的在各自模块进行清洗,只需要删除为空的信息即可【删除所有包含空null的行数据】
#删除为空的数据,any表示只要包含null则删除整行
self.dataf = self.df.dropna(axis=0,how='any')
数据分析
分析salary信息
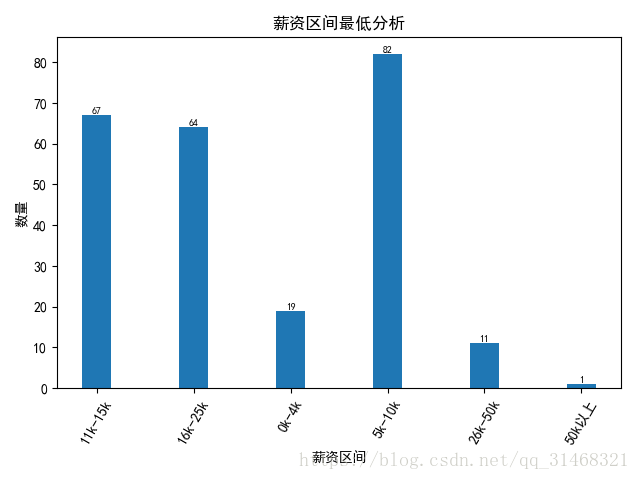
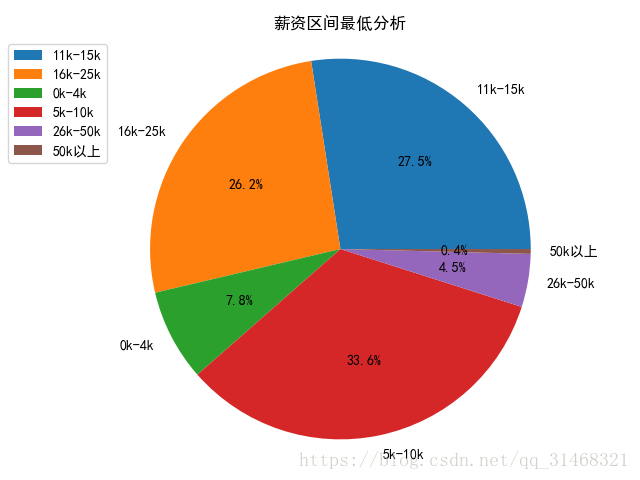
由于salary信息的格式为:15K-10K这种,所以分析salary信息时,按照区间值的最低值和最高值分别进行分析,先取出最值,然后对区间进行划分,新建一个列,保存划分之后的区间值。然后进行统计分析。
#取出区间最低值
self.dataf['salary_down'] = list(map(lambda x:x.split("-")[0],self.dataf['salary']))
#对最低值进行分区
self.dataf['salary_down_1'] = list(map(self.ana_salary_data,self.dataf['salary_down']))
#分析出区间中各种类的值
salary_d = FreqDist(self.dataf['salary_down_1'])
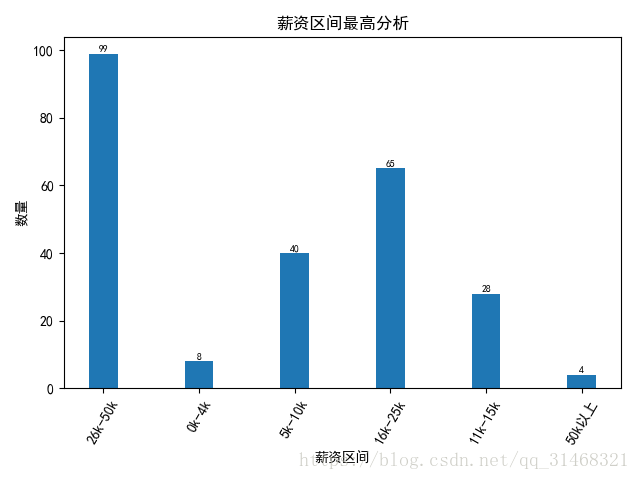
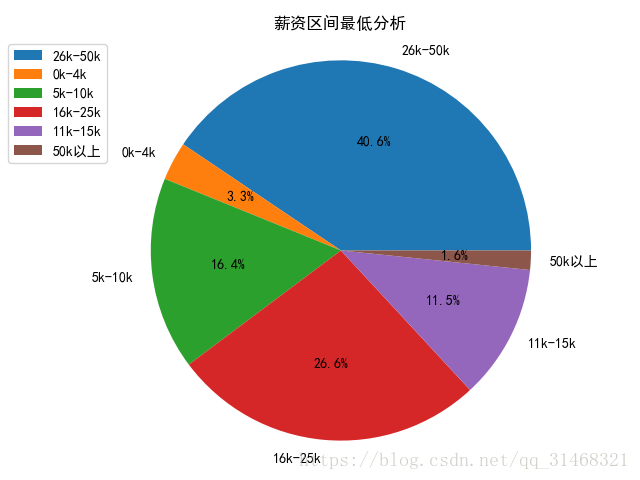
#按最高值进行分析
#按照薪资区间最高分析
self.dataf['salary_up'] = list(map(lambda x:x.split("-")[1],self.dataf['salary']))
self.dataf['salary_up_1'] = list(map(self.ana_salary_data,self.dataf['salary_up']))
salary_ud = FreqDist(self.dataf['salary_up_1'])
#分类接口如下:
def ana_salary_data(self,data_list):
num = int(data_list.split('K')[0])
if num <=4:
data_list = "0k-4k"
elif num <=10:
data_list = "5k-10k"
elif num <=15:
data_list = "11k-15k"
elif num <=25:
data_list = "16k-25k"
elif num <=50:
data_list = "26k-50k"
else:
data_list = "50k以上"
return data_list
最后返回一个dict类型的数据:如下:
字典的key为区间值,value为数量
这样就可以画图了,画图接口在后面展示
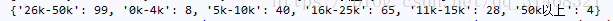
画图
self.do_bar_plot(dict(salary_d),"薪资区间","数量","薪资区间最低分析")
self.do_pie_plot(dict(salary_d),"薪资区间最低分析")
self.do_bar_plot(dict(salary_ud),"薪资区间","数量","薪资区间最高分析")
self.do_pie_plot(dict(salary_ud),"薪资区间最高分析")
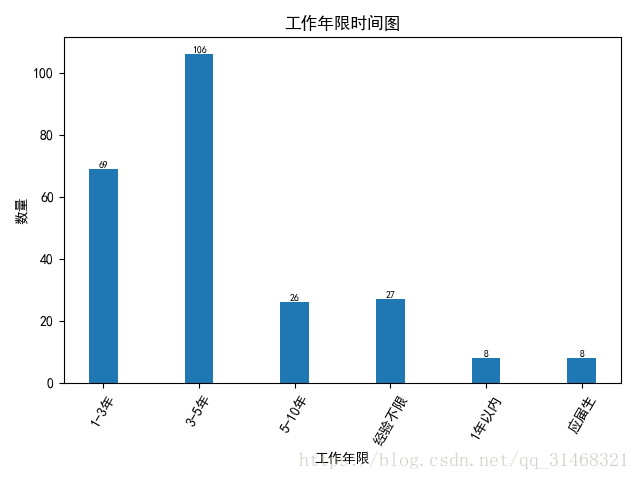
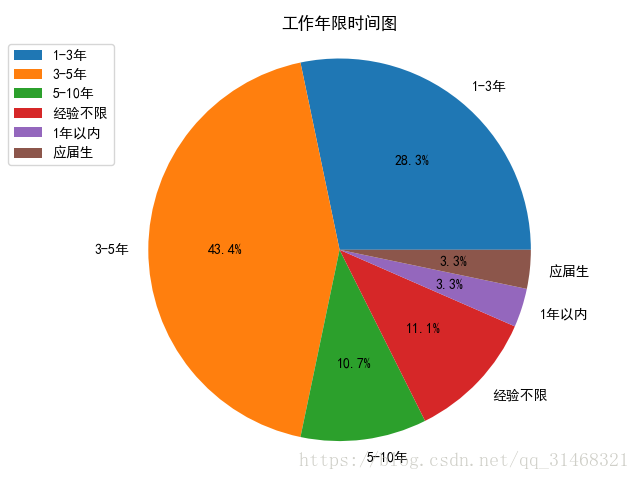
工作年限分析
由于工作年限信息中还有其他字段,首先先提取年限字段,然后对年限自段,进行分类统计
self.dataf['work_time_o'] = list(map(lambda x:x.split(":")[1],self.dataf['work_time']))
worktime = FreqDist(self.dataf['work_time_o'])
这样就会返回一个如上一样的字典数据
画图
self.do_bar_plot(dict(worktime),"工作年限","数量","工作年限时间图")
self.do_pie_plot(dict(worktime),"工作年限时间图")
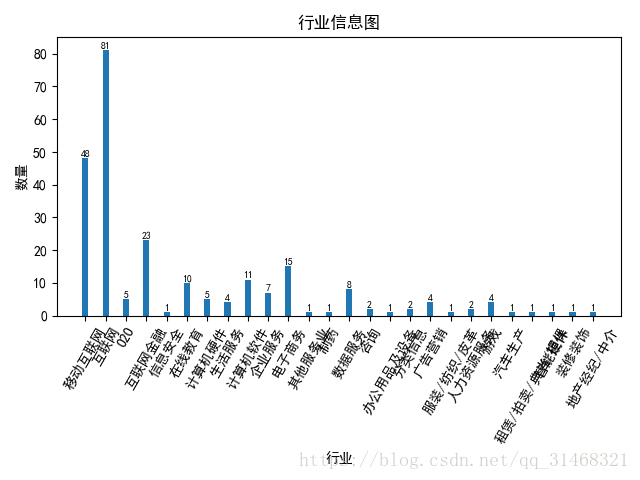
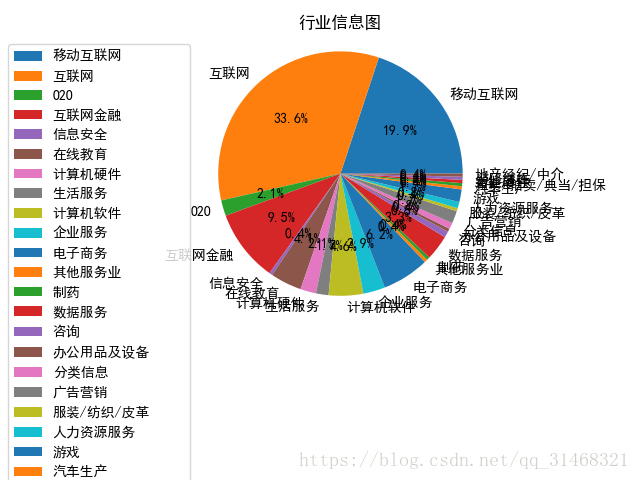
公司信息提取
这一块需要提取公司人数和公司行业两项数据,公司信息数据是一个列表,包含三项数据,分别为公司名称,公司人数,和公司行业。直接取出即可
#公司人数
#如果信息中有缺失,则设置为空,然后删除
self.dataf['info'] = list(map(lambda x: x[1] if len(x) == 3 else NAN, self.dataf['company_info']))
self.dataf = self.dataf.dropna()
infos = FreqDist(self.dataf['info'])
#公司行业
self.dataf['info_3'] = list(map(lambda x: x[-1], self.dataf['company_info']))
infos_3 = FreqDist(self.dataf['info_3'])
画图
self.do_bar_plot(dict(infos_3),"行业","数量","行业信息图")
self.do_pie_plot(dict(infos_3),"行业信息图")
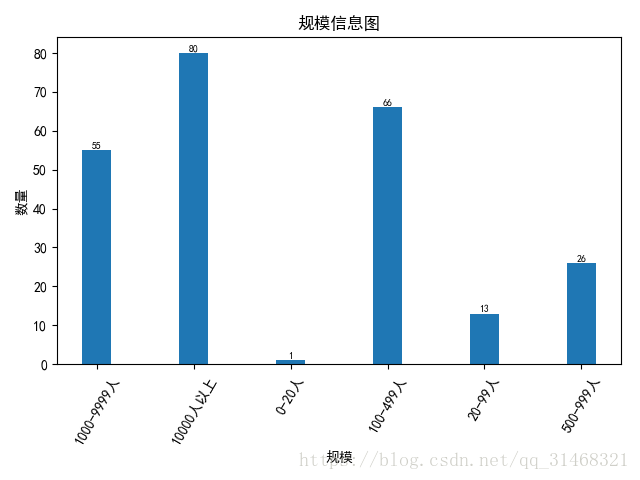
self.do_bar_plot(dict(infos),"规模","数量","规模信息图")
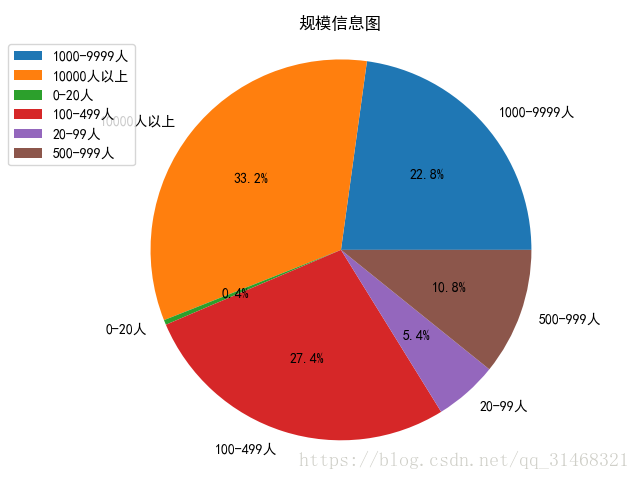
self.do_pie_plot(dict(infos),"规模信息图")
学历分析:
学历分析和公司信息分析基本一致
self.dataf['education_0'] = list(map(lambda x: x.split(":")[1], self.dataf['education']))
edu_dist = FreqDist(self.dataf['education_0'])
edu_dict = dict(edu_dist)
画图
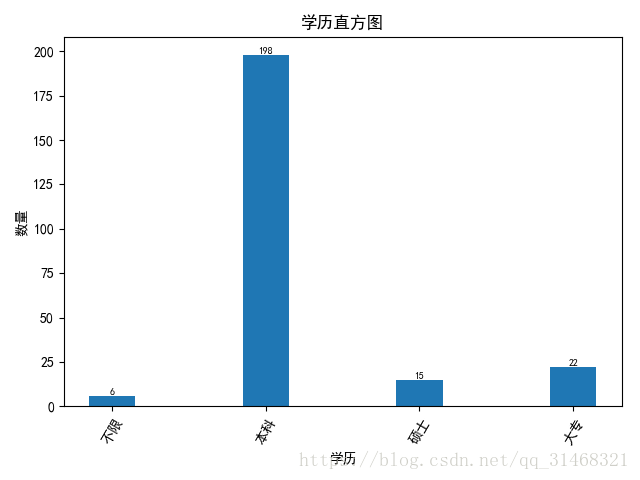
self.do_bar_plot(edu_dict,"学历","数量","学历直方图")
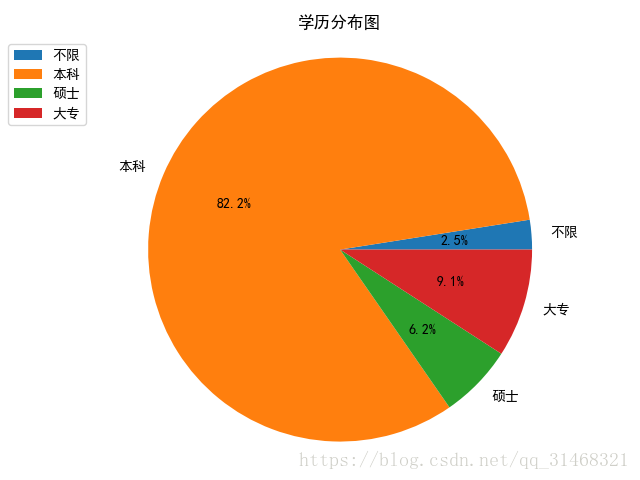
self.do_pie_plot(edu_dict,"学历分布图")
作图接口
本文中作图接口分为两个,柱状图和饼图两种:
柱状图
传入参数为:字典数据,x,y轴标签,和表头
def do_bar_plot(self,data_dict,xlabel,ylabel,title):
plt.figure()
x_val = list(data_dict.keys())
y_val = list(data_dict.values())
plt.bar(x_val,y_val,width=0.3)
plt.xticks(rotation=60)
plt.xlabel(xlabel)
plt.ylabel(ylabel)
for x in range(len(x_val)):
plt.text(x_val[x], y_val[x] + 0.05, '%.0f' % y_val[x], ha='center', va='bottom', fontsize=7)
plt.title(title)
plt.show()
饼图接口
传入参数为:字典数据,和表头
def do_pie_plot(self,data_dict,title):
plt.figure()
x_val = list(data_dict.keys())
y_val = list(data_dict.values())
explode = (0, 0, 0, 0)
plt.pie(y_val,labels=x_val,autopct='%1.1f%%')
plt.axis('equal')
plt.legend(loc='upper left', bbox_to_anchor=(-0.1, 1))
plt.title(title)
plt.show()