数据链接:https://pan.baidu.com/s/1I0w4129XYEW2Iwvc4rm1pA
提取码:hdc3提示:
数据是自己爬的,如果有小伙伴想看,我会再更新数据的爬虫部分。
房天下网站:https://newhouse.fang.com/house/s/b81-b91/
数据可视化小项目,自己杂糅的,希望对大家有帮助,有什么问题评论区留言~
一、数据处理
1.数据导入
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv('北京小区数据信息.csv')
df.head()
2.数据预处理
把数据里面非北京地区的删了
(数据是网站根据北京用户需求推介的,我只想要北京和北京周边的)
df=df[-df.所在区.isin(['非北京周边','海阳城区','宝坻','秦皇岛','永清','涞水','怀来','天津','霸州','大厂','廊坊','涿州','固安','崇礼'])]
df=df[-df.均价.isin(['价格待定元/㎡'])]将数据处理一下,加入一些更有意义的列:
1. 北京各地区房产均价
房价数据有两类:xxx元/m^2,xxxx万元/套起;

先做xxx元/m^2的
estate_single = df[df['均价'].str.contains('元/㎡')]
estate_single['均价'] = [int(i.split('元/㎡')[0]) for i in estate_single['均价']]
estate_mean = estate_single[['所在区', '均价']].groupby('所在区').mean()
estate_mean.reset_index(inplace=True)
estate_mean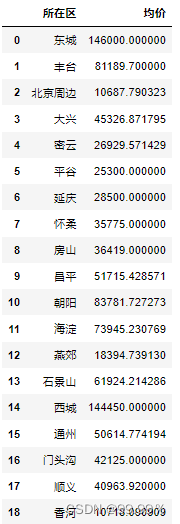
再来做xxxx万元/套起的数据
import re
estate_tao = df[df['均价'].str.contains('套')].reset_index(drop=True)
strinfo = re.compile('万元|/套|起')
#去除中文字符
estate_tao['均价'] = estate_tao['均价'].apply(lambda x: strinfo.sub('',x))
estate_tao['均价']=estate_tao['均价'].astype(int)
#把str型转为int排个名看看
estate_tao['均价']=estate_tao['均价'].sort_index()
estate_tao.head(10)
#把以套为价格的房价排个名
把xxx万元/套的房价数据转为xxx元/m^2的,此步骤不够严谨,所以如果对数据要求高,建议直接把xxx万元/套的房价数据删除,只分析xxx元/m^2的数据就行
#由于房产是以套为单位显示价格,所以只能结合实际,人工评估价格
for i in range(127):
if estate_tao['小区名称'][i]=='恒大丽宫':
estate_tao['均价'][i] = estate_tao['均价'][i]*5#恒大丽宫面积极大
elif estate_tao['均价'][i]>=1500:
estate_tao['均价'][i] = estate_tao['均价'][i]*30#例如圆明天颂户型较大,所以每平米更便宜一些
elif estate_tao['均价'][i]<=1000 and estate_tao['所在区'][i]!='朝阳'and estate_tao['所在区'][i]!='海淀':
estate_tao['均价'][i] = estate_tao['均价'][i]*100#例如兴创荣墅
elif estate_tao['均价'][i]<=1000 and estate_tao['所在区'][i]=='朝阳':
estate_tao['均价'][i] = estate_tao['均价'][i]*130#例如北京书院,户型较小,所以每平米更贵
elif estate_tao['均价'][i]<=1000 and estate_tao['所在区'][i]=='海淀':
estate_tao['均价'][i] = estate_tao['均价'][i]*130
elif estate_tao['均价'][i]>1000 and estate_tao['均价'][i]<1500:
estate_tao['均价'][i] = estate_tao['均价'][i]*55#例如玖瀛府,户型较大,所以每平米更贵
else:
estate_tao['均价'][i] = estate_tao['均价'][i]*75合并处理好的数据(xxx元/m^2和xxx万元/套起)
estate = pd.concat([estate_single,estate_tao], axis=0)
estate['小区名称'].value_counts() #看看情况,有没有重复值 
删除重复值
estate = estate.drop_duplicates()
#数据删除重复值二、特征提取
1.数据标准化
主要是为了获取房产热度指数,所以把房产的评论数据标准化,根据评论条数确定热度:
我将评论数据进行0-1标准化,将评论数最大值设为1,最小值设为0,将数据缩放(映射)到设置的0-1区间。并将标准化后的评论数设为标准化热度,加入到数据集中。
from sklearn import preprocessing
import pandas
a=pd.DataFrame(estate['评论数'])
min_max_normalizer=preprocessing.MinMaxScaler(feature_range=(0,1))
#feature_range设置最大最小变换值,默认(0,1)
scaled_data=min_max_normalizer.fit_transform(a)
#将数据缩放(映射)到设置固定区间
price_frame_normalized=pandas.DataFrame(scaled_data)
#将变换后的数据转换为dataframe对象
print(price_frame_normalized)

#新建列-标准化热度(用来存储房产热度数值)
estate['标准化热度'] = price_frame_normalized
#复制一份数据,为之后的分析埋下伏笔
import copy
estate1=copy.deepcopy(estate)
estate12.LDA主题分类及模型优化
纵观整个数据集,虽然拥有所在区这一列,但是所在区有19种类型,这并不利于直观的可视化,因为每个区域都有交通便利的楼盘,也有相对偏远的楼盘,所以我想到通过详细地址信息进行LDA主题分类,从而获取楼盘的具体位置类型。
首先,将空字符的行替换为nan,然后进行删除;
#第一步 将空字符的行替换为nan,方便进行删除
estate['详细地址'].replace(to_replace=r'^\s*$', value=np.nan, regex=True, inplace=True)
estate['详细地址'].replace(to_replace=r'[a-zA-Z]', value=np.nan, regex=True, inplace=True)
print(estate['详细地址'])
#第二步 删除所有值为nan的行
estate.dropna(axis=0, how='any', inplace=True)然后将文段中包含的数字去除,因为具体的数字对于LDA主题分类的帮助不大,并且因为单位和具体含义难以辨析,所以也容易对结果产生负向影响;
#去除数字
strinfo = re.compile('[0-9]|北京')
estate['详细地址'] = estate['详细地址'].apply(lambda x: strinfo.sub('',x)) →→→→
→→→→ 
随后利用jieba对每行文段进行中文分词操作:
import jieba
import jieba.posseg as psg
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
#格式转换 否则会报错 'float' object has no attribute 'decode'
estate = pd.DataFrame(estate['详细地址'].astype(str))
def chinese_word_cut(mytext):
return ' '.join(jieba.cut(mytext))
#增加一列数据
estate['content_cutted'] = estate['详细地址'].apply(chinese_word_cut)
print(estate.content_cutted.head())
然后通过构建TfidfVectorizer,计算词汇的TF-IDF值,以便接下来的lda分析:
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
#设置特征数
n_features = 2000
tf_vectorizer = TfidfVectorizer(strip_accents = 'unicode',
max_features=n_features,
max_df = 0.99,
min_df = 0.002) #去除文档内出现几率过大或过小的词汇
tf = tf_vectorizer.fit_transform(estate.content_cutted)
print(tf.shape)
print(tf) 
之后进行LDA分析,将LDA模型主题数设为3,从而得到三种主题:
from sklearn.decomposition import LatentDirichletAllocation
#设置主题数
n_topics = 3
#Python 2.X: n_topics=n_topics
lda = LatentDirichletAllocation(n_components=n_topics,
max_iter=100,
learning_method='online',
learning_offset=50,
random_state=0)
lda.fit(tf)
#显示主题数 model.topic_word_
print(lda.components_)
#几个主题就是几行 多少个关键词就是几列
print(lda.components_.shape)
#主题-关键词分布
def print_top_words(model, tf_feature_names, n_top_words):
for topic_idx,topic in enumerate(model.components_): # lda.component相当于model.topic_word_
print('Topic #%d:' % topic_idx)
print(' '.join([tf_feature_names[i] for i in topic.argsort()[:-n_top_words-1:-1]]))
print("")
n_top_words = 10
tf_feature_names = tf_vectorizer.get_feature_names()
#调用函数
print_top_words(lda, tf_feature_names, n_top_words)

最终通过将LDA主题模型可视化,更加直观地感受分类结果 :
import pyLDAvis
import pyLDAvis.gensim_models
keshihua_data = pyLDAvis.sklearn.prepare(lda,tf,tf_vectorizer)
pyLDAvis.display(keshihua_data)
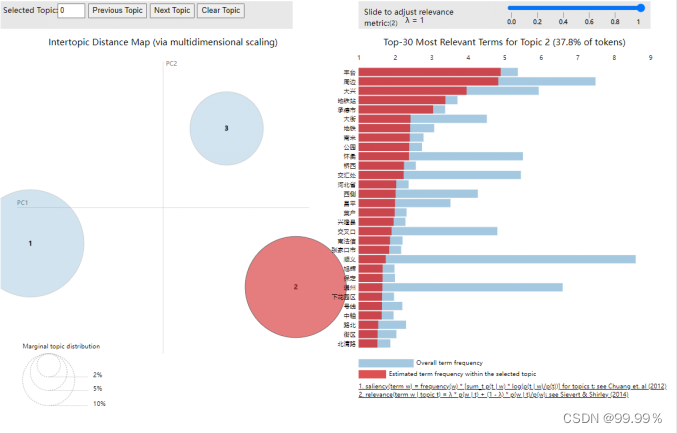
通过分类结果可以看出,所有楼盘详细地址被清晰地分为了3类,每个类别都有自己的主题关键词,具体的分析将在数据分析部分给出。
三、数据分析及可视化
1.kmeans聚类及模型调优
我想利用数据集推知楼盘的热度与楼盘价格是否相关,并且能否根据价格和热度将所有楼盘聚为几种具有代表性的楼盘类型。
estate1就是前面复制出的dataframe,(代码在二、特征提取 1.数据标准化的最后)
estate1['评论数']=estate1['评论数']*100
wnc = list(estate1.groupby(['均价', '评论数']).groups.keys())
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
X = wnc
# Kmeans聚类
clf = KMeans(n_clusters=3)
y_pred = clf.fit_predict(X)
print(clf)
print(y_pred)
# 可视化操作
import numpy as np
import matplotlib.pyplot as plt
x = [n[0] for n in X]
y = [n[1] for n in X]
plt.scatter(x, y, c=y_pred, marker='x')
plt.title("Kmeans-House Data")
plt.xlabel("price")
plt.ylabel("redu")
plt.legend(["house"])
plt.show() 
发现聚为三类的效果并不好,似乎仍旧是依据价格将楼盘分为了高中低三个档次,对热度指标的分类不明显。
我将聚类数调整为5后,发现聚类效果好了很多:
from sklearn.cluster import KMeans
X = wnc
# Kmeans聚类
clf = KMeans(n_clusters=5)
y_pred = clf.fit_predict(X)
print(clf)
print(y_pred)
# 可视化操作
import numpy as np
import matplotlib.pyplot as plt
x = [n[0] for n in X]
y = [n[1] for n in X]
plt.scatter(x, y, c=y_pred, marker='x')
plt.title("Kmeans-House Data")
plt.xlabel("price")
plt.ylabel("redu")
plt.legend(["house"])
plt.show() 
聚类图将数据集划分为:
热度高且价格相对实惠的淡绿色、左下角便宜且热度相对较低的青色、位于中档房价区间且热度较低的紫色、中高档中的热度一般的黄色,以及右下方超高档的冷门楼盘深蓝色;
可以通过聚类图分析出热度高的楼盘均价全部在13万每平米以下,并且绝大多数热度高的楼盘集中在5000-10万之间。
2.可视化(利用pycharts)
主要根据为数不多的数据,画点稍有意义的图像。
#将评论数转化为小数,154→1.54
estate1['评论数']=estate1['评论数']/100
from pyecharts.charts import Bar
from pyecharts.commons.utils import JsCode
from pyecharts import options as opts ##导入配置项
high_top10 = estate1[['小区名称','均价']].sort_values(by='均价',ascending=False)[:10]
# 最高房价top10
low_top5 = estate1[['小区名称','均价']].sort_values(by='均价',ascending=True)[:5]
# 最低房价top10画图画图画图!!!想改颜色啥的直接百度pycharts颜色代码就行,搜就完事了。
1.北京市房价最高的前10个小区
color_js = """new echarts.graphic.LinearGradient(0, 1, 0, 0,
[{offset: 0, color: '#8d4653'}, {offset: 1, color: '#8d4653'}], false)"""
bar = (
Bar()
.add_xaxis(high_top10['小区名称'].values.tolist())
.add_yaxis("均价", high_top10['均价'].tolist(),itemstyle_opts=opts.ItemStyleOpts(color=JsCode(color_js)))
.set_global_opts(title_opts=opts.TitleOpts(title='北京市房价最高的前10个小区',pos_top='2%',pos_left = 'center'),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-45)),
yaxis_opts=opts.AxisOpts(name="均价",name_location='middle',name_gap=50,name_textstyle_opts=opts.TextStyleOpts(font_size=16)))
)
bar.render_notebook() 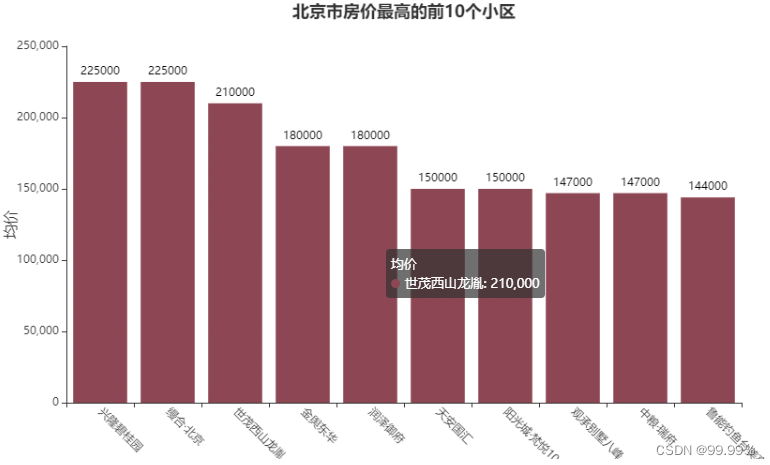
2.北京市及燕郊房价最低的前10个小区
color_js = """new echarts.graphic.LinearGradient(0, 1, 0, 0,
[{offset: 0, color: '#FFFFFF'}, {offset: 1, color: '#8085e8'}], false)"""
bar = (
Bar()
.add_xaxis(low_top5['小区名称'].values.tolist())
.add_yaxis("均价", low_top5['均价'].tolist(),itemstyle_opts=opts.ItemStyleOpts(color=JsCode(color_js)))
.set_global_opts(title_opts=opts.TitleOpts(title='北京市及燕郊房价最低的前10个小区',pos_top='2%',pos_left = 'center'),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-45)),
yaxis_opts=opts.AxisOpts(name="均价",name_location='middle',name_gap=50,name_textstyle_opts=opts.TextStyleOpts(font_size=16)))
)
bar.render_notebook()
3.北京市及周边各区小区房价均价
meanprice = estate1[['所在区', '均价']].groupby('所在区').mean()
color_js = """new echarts.graphic.LinearGradient(0, 1, 0, 0,
[{offset: 0, color: '#FFFFFF'}, {offset: 1, color: '#f7a35c'}], false)"""
xdata = list(meanprice.index)
ydata = [int(price) for price in meanprice['均价'].values.tolist()]
bar = (
Bar()
.add_xaxis(xdata)
.add_yaxis("均价", ydata,itemstyle_opts=opts.ItemStyleOpts(color=JsCode(color_js)))
.set_global_opts(title_opts=opts.TitleOpts(title='北京市及周边各区小区房价均价',pos_top='2%',pos_left = 'center'),
legend_opts=opts.LegendOpts(is_show=False),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-45)),
yaxis_opts=opts.AxisOpts(name="均价",name_location='middle',name_gap=50,name_textstyle_opts=opts.TextStyleOpts(font_size=16)))
)
bar.render_notebook() 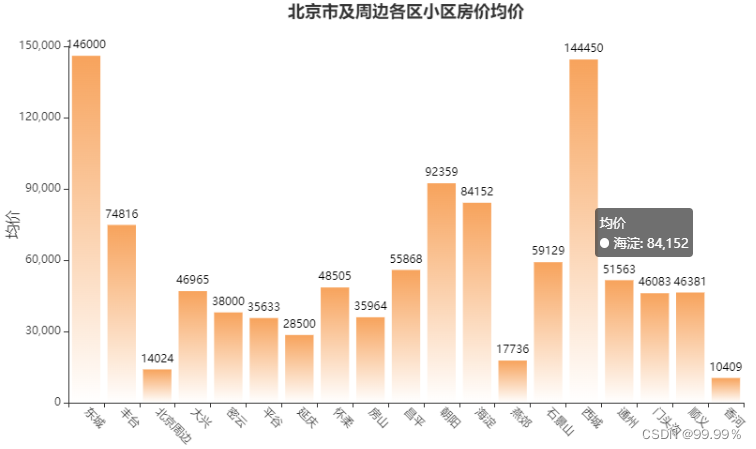
4.北京都市圈各区域楼盘房价级别分布
先按照房价给楼盘分个档次:
bins = [0, 5000, 10000, 50000, 100000, 150000, 1000000]
group_names = ['低的档','中低档', '中档', '中高档', '高的档','超高档']
estate1['小区级别'] = pd.cut(estate1['均价'], bins, labels=group_names)
estate1.head()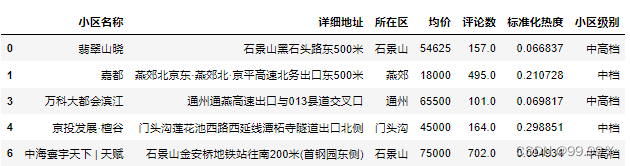
画就完事了:
estate1['超高档'] = estate1['小区级别'].apply(lambda x : 1 if '超高档' in x else 0)
estate1['高的档'] = estate1['小区级别'].apply(lambda x : 1 if '高的档' in x else 0)
estate1['中高档'] = estate1['小区级别'].apply(lambda x : 1 if '中高档' in x else 0)
estate1['中档'] = estate1['小区级别'].apply(lambda x : 1 if '中档' in x else 0)
estate1['中低档'] = estate1['小区级别'].apply(lambda x : 1 if '中低档' in x else 0)
estate1['低的档'] = estate1['小区级别'].apply(lambda x : 1 if '低的档' in x else 0)
qu_huxing = estate1[['所在区','低的档','中低档', '中档', '中高档', '高的档','超高档']].groupby('所在区').sum()
# 绘图
bar = (
Bar()
.add_xaxis(list(qu_huxing.index))
.add_yaxis("低的档", qu_huxing['低的档'].values.tolist(),stack='stack1')
.add_yaxis("中低档", qu_huxing['中低档'].values.tolist(),stack='stack1')
.add_yaxis("中档", qu_huxing['中档'].values.tolist(),stack='stack1')
.add_yaxis("中高档", qu_huxing['中高档'].values.tolist(),stack='stack1')
.add_yaxis("高的档", qu_huxing['高的档'].values.tolist(),stack='stack1')
.add_yaxis("超高档", qu_huxing['超高档'].values.tolist(),stack='stack1')
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title='北京都市圈各区域楼盘房价级别分布',pos_top='2%',pos_left = 'center'),
xaxis_opts=opts.AxisOpts(name='不同级别',axislabel_opts=opts.LabelOpts(rotate=-45)),
yaxis_opts=opts.AxisOpts(name='小区数量'),
legend_opts=opts.LegendOpts(is_show=True, pos_top = '15%'))
)
bar.render_notebook() 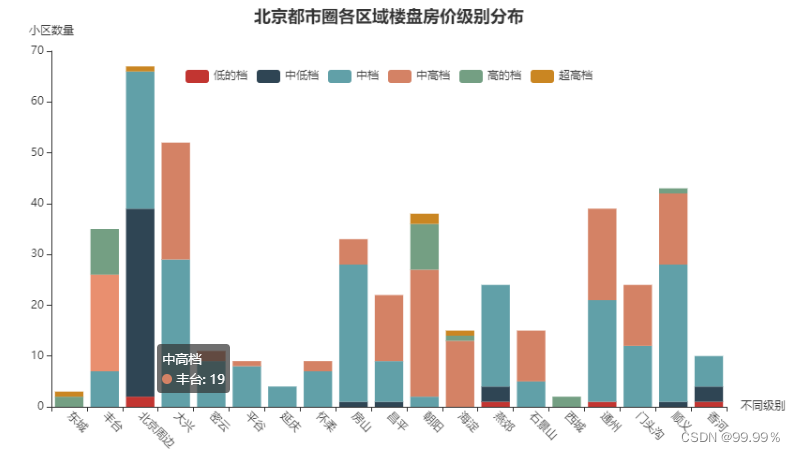
5.北京都市圈各区域楼盘热度级别分布
bins = [0, 100, 500, 1000, 2000] #设置10000为最大值
group_names = ['冷门', '一般', '热门', '非常热门']
estate1['热度级别'] = pd.cut(estate1['评论数'], bins, labels=group_names)
estate1.head()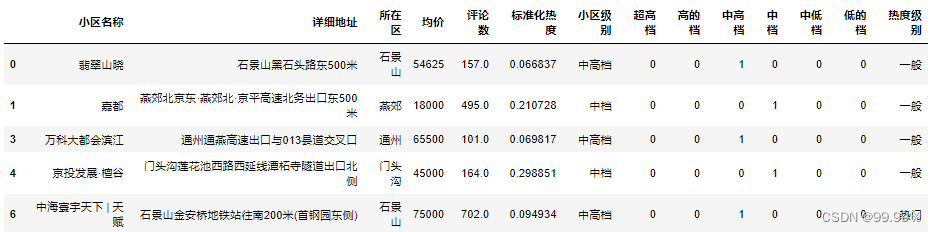
estate1['非常热门'] = estate1['热度级别'].apply(lambda x : 1 if '非常热门' in x else 0)
estate1['热门'] = estate1['热度级别'].apply(lambda x : 1 if '热门' in x else 0)
estate1['一般'] = estate1['热度级别'].apply(lambda x : 1 if '一般' in x else 0)
estate1['冷门'] = estate1['热度级别'].apply(lambda x : 1 if '冷门' in x else 0)
qu_huxing = estate1[['所在区', '冷门', '一般', '热门', '非常热门']].groupby('所在区').sum()
# 绘图
bar = (
Bar()
.add_xaxis(list(qu_huxing.index))
.add_yaxis("冷门", qu_huxing['冷门'].values.tolist(),stack='stack1')
.add_yaxis("一般", qu_huxing['一般'].values.tolist(),stack='stack1')
.add_yaxis("热门", qu_huxing['热门'].values.tolist(),stack='stack1')
.add_yaxis("非常热门", qu_huxing['非常热门'].values.tolist(),stack='stack1')
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title='北京都市圈各区域楼盘热度级别分布',pos_top='2%',pos_left = 'center'),
xaxis_opts=opts.AxisOpts(name='不同热度',axislabel_opts=opts.LabelOpts(rotate=-45)),
yaxis_opts=opts.AxisOpts(name='小区数量'),
legend_opts=opts.LegendOpts(is_show=True, pos_top = '15%'))
)
bar.render_notebook()
6.评论热度分布(饼图,按行政区划分)
这块是直接人工输入的数据,懒得打的小伙伴可以直接value.counts(),然后复制
import matplotlib.pyplot as plt
import plotly.offline
import plotly.graph_objs
import cufflinks as cf
import numpy as np
cf.go_offline()###这两句是离线生成图片的设置
cf.set_config_file(offline=True, world_readable=True)
labels=np.array(['东城', '丰台', '北京周边', '大兴', '密云', '平谷', '延庆', '怀柔', '房山', '昌平', '朝阳','海淀', '燕郊', '石景山', '西城', '通州', '门头沟', '顺义', '香河'])#np.array数组创建方法
sizes=np.array([136,5065,5927,9920,1516,988,277,629,6081,3959,5402,1412,2541,2042,234,4668,2910,4482,2126])
plt.figure(figsize=(10,8),dpi=600)
#构造trace,配置相关参数
trace=plotly.graph_objs.Pie(labels=labels,values=sizes)
layout=plotly.graph_objs.Layout(title='评论热度分布')
#将trace保存于列表之中
data=[trace]
#将data补分和layout补分组成figure对象
fig=plotly.graph_objs.Figure(data=data,layout=layout)
#使用plotly.offline.iplot方法,将生成的图形嵌入到ipynb文件中
plotly.offline.iplot(fig)
7.热度级别树状图(按档次划分)
estate_cor = estate1[['小区级别', '热度级别', '小区名称']].groupby(['小区级别', '热度级别']).count()
estate_cor.reset_index(inplace=True)
estate_cor.rename(columns={'小区名称':'小区数'}, inplace=True)
estate_cor['小区数'].fillna(value=0, inplace=True)
estate_cor
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(font="simhei")
plt.figure(figsize=(10,6), dpi=100)
estate_cor['小区数'] = [int(i) for i in estate_cor['小区数']]
hmap = estate_cor.pivot("小区级别", "热度级别", "小区数")
sns.heatmap(hmap, annot=True, fmt="d",cmap="OrRd") 
总结和后记
本篇文章主要是可视化部分,接下来还会更新导入数据库,django驾驶舱可视化等更深入的内容。
有啥子问题评论区留言即可~~~