一、前言
主成分分析(Principal Component Analysis)是最常用的一种降维方法。以前经常用PCA用来特征的降维,但对原理和实现方法理解的不透彻,用起来心里没底,这几天有空总结一下PCA的原理。
二、原理
在正交属性空间中的样本点,如何使用一个超平面对所有样本进行恰当的表达?这样的超平面应该有这样的性质:
- 最近重构性:样本点到这个超平面的距离足够近(尽量少的信息损失)
- 最大可分性:样本点到这个超平面的投影能尽可能分开
有趣的是基于最近重构性和最大可分性,能分别得到主成分分析的两种等价的推导。首先从最近重构性来推导:
假定数据样本进行了中心化,即 ∑ni=1xi=0 ∑ i = 1 n x i = 0 ;投影变换后的新坐标系为{
ω1,ω2,...,ωd ω 1 , ω 2 , . . . , ω d },其中 ωi ω i 是标准正交基向量, ||ωi||2=1 | | ω i | | 2 = 1 , ωTiωj=0,(i≠j) ω i T ω j = 0 , ( i ≠ j ) 。当丢弃新坐标系中的部分坐标,即将维度降低到 d′ d ′ ,则样本点 xi x i 在低维坐标系中的投影是 zi=(zi1,zi2,...,zid′) z i = ( z i 1 , z i 2 , . . . , z i d ′ ) ,其中 zij=ωTjxi z i j = ω j T x i 是 xi x i 在低维坐标系下第j维的坐标。若基于 zi z i 来重构 xi x i ,则会得到 x^i=∑d′j=1zijωj x ^ i = ∑ j = 1 d ′ z i j ω j .
对于整个训练集,原样本点 xi x i 与基于投影重建的样本点 x^i x ^ i 之间的距离为:
其中const是个常数,根据最近重构性,上式应该被最小化,有:
这就是主成分分析的优化目标。
从最大可分性推导,能得到主成分分析的另一种解释,样本点 xi x i 在新空间中超平面上的投影是W^Tx_i,要想达到最大可分性,就应该使投影后样本的方差最大化,于是优化目标可写为:
显然从最大可分性出发和从最近重构性出发得到的优化目标是一样的,对其使用拉格朗日乘子法可得:
于是,只需对协方差矩阵 XXT X X T 进行特征值分解,将求得的特征值排序,再取前 d′ d ′ 个特征值对应的特征向量构成 W=(w1,w2,...,w′d) W = ( w 1 , w 2 , . . . , w d ′ ) .这就是主成分分析的解.
白话总结,将一组N维向量降为K维(K大于0,小于N),其目标是选择K个单位(模为1)正交基,使得原始数据变换到这组基上后,各字段两两间协方差为0,而字段的方差则尽可能大(在正交的约束下,取最大的K个方差)。
PCA本质上就是把方差最大的方向作为主要特征,并且在各个正交方向上将数据“离相关”,也就是让它们在不同正交方向上没有相关性。
三、算法
输入:样本集D={
x1 x 1 , x2 x 2 , … , xn x n };低纬空间维数d
过程:
-1. 对所有所有样本进行中心化 xi x i = xi x i - 1m 1 m ∑mi=1(xi) ∑ i = 1 m ( x i )
-2. 计算样本的协方差矩阵 X∗XT X ∗ X T
-3. 对协方差矩阵做特征值分解
-4. 选出最大的d个特征值所对应的特征向量 ω1,ω2,...,ωd ω 1 , ω 2 , . . . , ω d
输出:投影矩阵 W=(ω1,ω2,...,ωd) W = ( ω 1 , ω 2 , . . . , ω d )
降维之后低维空间的维度 d′ d ′ 通常是由用户指定的,或通过在 d′ d ′ 值不同的低纬空间中对k近邻分类器(或其他开销较小的分类器)进行交叉验证来选取。对PCA,还可以从重构的角度设置一个重构阈值,例如取 t=95 t = 95 ,然后选取使下式成立的 d′ d ′ :
四、PCA实例

五、核主成分分析KPCA
PCA存在一些限制,例如它可以很好的解除线性相关,但是对于高阶相关性就没有办法了,对于存在高阶相关性的数据,可以考虑Kernel PCA,通过Kernel函数将非线性相关转为线性相关。
非线性降维的一种常用方法,是基于核技巧对线性降维方法进行核化,下面介绍核主成分分析(Kernelized PCA)的实现原理。
假定,我们将在高维空间中把数据投影到由 W W 确定的超平面上,即PCA欲求解
其中 zi z i 样本点 xi x i 在高维特征空间中的像,则
其中 αi=1λzTiW α i = 1 λ z i T W .假定 zi z i 是由原始属性空间中的样本点 xi x i 通过映射 ϕ ϕ 产生,即 zi=ϕ(xi),i=1,2,...,m z i = ϕ ( x i ) , i = 1 , 2 , . . . , m 。若 ϕ ϕ 能被显式表达出来,则通过它将样本映射到高维特征空间,再在特征空间中实施PCA即可,上面两式变为:
一般情况下,我们不清楚 ϕ ϕ 的具体形式,于是引入核函数
将4、5式带入3式化简可得:
其中, K K 为 对应的核矩阵, (K)ij=k(xi,xj) ( K ) i j = k ( x i , x j ) , A=(α1,α2,...,αn) A = ( α 1 , α 2 , . . . , α n ) . 取 K K 最大的 个特征值对应的特征向量即可。
对新样本 x x ,其投影后第 维坐标为:
其中 αi α i 已经规范化, αji α i j 是 αi α i 的第j个分量。由式7可以看出,KPCA需要对所有样本求和,因此它的计算开销较大。
常用的核函数:
多项式核:
径向基核函数(RBF)(高斯核函数):
六、sklearn中PCA的使用方法
函数原型及参数说明
sklearn.decomposition.PCA(n_components=None, copy=True, whiten=False)
n_conmponents:保留的特征个数,缺省为none,保留所有特征;“mle”表示使用MLE算法根据特征的方差分布情况自己去选择一定数量的主成分特征来降维;当去(0,1)之间的小数时,表示从重构的角度设置一个重构阈值,选取合适的特征数;
copy:是否改变元数据,默认为True
whiten:是否进行白化处理,缺省值为False,白化的概念参看Ufldl教程
输出:
pca.explained_variance_ratio_ :投影后的特征维度的方差占比,和为1
pca.explained_variance_:投影后的特征维度的方差
pca.n_components_:保留的特征个数
使用样例
# 分离半月形数据,实现rbf_kernel_pca方法应用于非线性数据集
# 创建一个包含100个样本的二维数据集,以两个半月形状表示
import matplotlib.pyplot as plt
%matplotlib inline
# %matplotlib inline 可以在Ipython编译器里直接使用,功能是可以内嵌绘图,并且可以省略掉plt.show()这一步。
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=100, random_state=123)
plt.scatter(X[y==0, 0], X[y==0, 1], color='red', marker='^', alpha=0.5)
plt.scatter(X[y==1, 0], X[y==1, 1], color='blue', marker='o', alpha=0.5)
plt.tight_layout()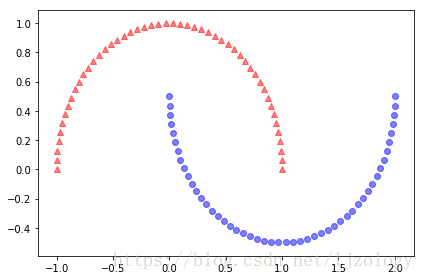
# 通过标准的PCA将数据映射到主成分上,对比原图
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
scikit_pca = PCA(n_components=2)
X_spca = scikit_pca.fit_transform(X)
fig, ax = plt.subplots(nrows=1,ncols=2, figsize=(7,3))
ax[0].scatter(X_spca[y==0, 0], X_spca[y==0, 1], color='red', marker='^', alpha=0.5)
ax[0].scatter(X_spca[y==1, 0], X_spca[y==1, 1], color='blue', marker='o', alpha=0.5)
ax[1].scatter(X_spca[y==0, 0], np.zeros((50,1))+0.02, color='red', marker='^', alpha=0.5)
ax[1].scatter(X_spca[y==1, 0], np.zeros((50,1))-0.02, color='blue', marker='o', alpha=0.5)
ax[0].set_xlabel('PC1')
ax[0].set_ylabel('PC2')
ax[1].set_ylim([-1, 1])
ax[1].set_yticks([])
ax[1].set_xlabel('PC1')
plt.tight_layout()
plt.show()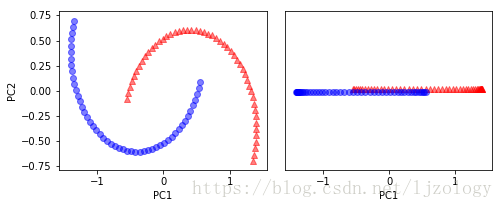
# kernel参数可选择不同的核函数
from sklearn.decomposition import KernelPCA
X, y = make_moons(n_samples=100, random_state=123)
scikit_kpca = KernelPCA(n_components=2, kernel='rbf', gamma=15)
# 其中gamma的选值很重要,默认为1/n_features
X_skernpca = scikit_kpca.fit_transform(X)
fig, ax = plt.subplots(nrows=1,ncols=2, figsize=(7,3))
ax[0].scatter(X[y==0, 0], X[y==0, 1], color='red', marker='^', alpha=0.5)
ax[0].scatter(X[y==1, 0], X[y==1, 1], color='blue', marker='o', alpha=0.5)
ax[1].scatter(X_skernpca[y==0, 0], X_skernpca[y==0, 1],color='red', marker='^', alpha=0.5)
ax[1].scatter(X_skernpca[y==1, 0], X_skernpca[y==1, 1],color='blue', marker='o', alpha=0.5)
ax[0].set_xlabel('PC1')
ax[0].set_ylabel('PC2')
ax[1].set_ylim([-1, 1])
ax[1].set_yticks([])
ax[1].set_xlabel('PC1')
plt.tight_layout()
plt.show()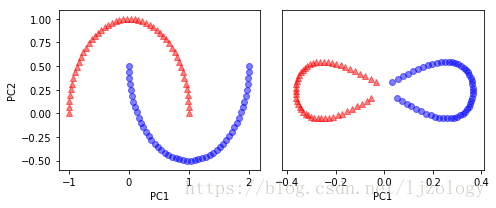
参考文献
http://blog.codinglabs.org/articles/pca-tutorial.html
https://www.cnblogs.com/pinard/p/6243025.html
https://blog.csdn.net/ChenVast/article/details/79236160
周志华. 机器学习 : = Machine learning[M]. 清华大学出版社, 2016.