版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/kevin_zhao_zl/article/details/84342429
论文地址:Fully Convolutional Networks for Semantic Segmentation
[Long J , Shelhamer E , Darrell T . Fully Convolutional Networks for Semantic Segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2014, 39(4):640-651.]
论文实现:github代码
1. 创新
- 接收任意尺寸输入的全卷积网络
- 使用反卷积的上采样
- 融合深层粗糙特征和浅层精细特征的跳跃结构
2.模型提出
- 为什么可以将CNN转化为FCN?
全连接层可以看作卷积层,其中,feature map 1x1,向量长度为通道数。 - 为什么需要上采样?
端到端的密集预测需要输入和输出的尺寸一致,而提取特征图的过程中图像像素降低,感受野变大,输出尺寸与输入不一致。 - 为什么需要跳跃结构进行跨层特征融合?
深层的特征对应全局的语义信息,浅层的特征对应着目标的位置信息,语义分割二者都需要考虑,所以引入了跳跃结构。
3.模型架构
3.1 调整分类网络至全卷积以进行稠密预测
将全连接层替换为卷积层,如图:
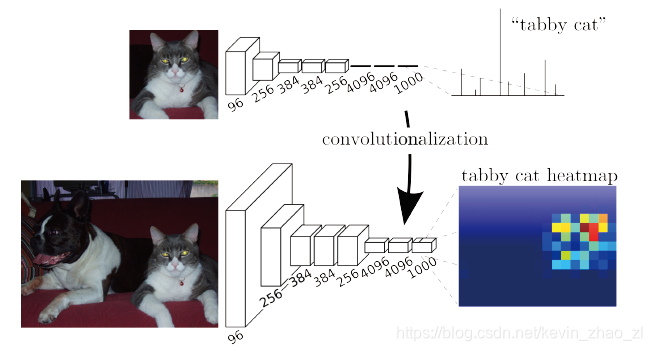
3.2 使用反卷积的上采样
为了还原图像的尺寸,文章中提出了三种方法,即稀疏滤波(Shift-and-stitch)、双线性插值、和反卷积, 并采用了反卷积的方法。反卷积是与卷积操作相反的计算,比如下图是普通的卷积,4x4 Input、3x3 KernelSize、0 pad、1 stride:
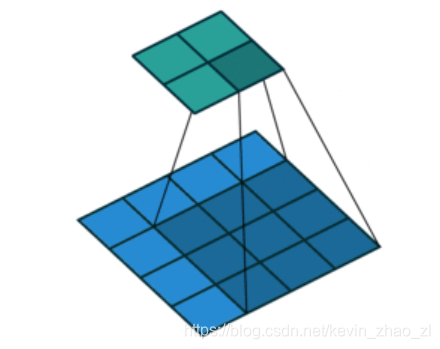
反卷积将卷积还原:2x2 Input、3x3 KernelSize、0 pad、1 stride,如图:
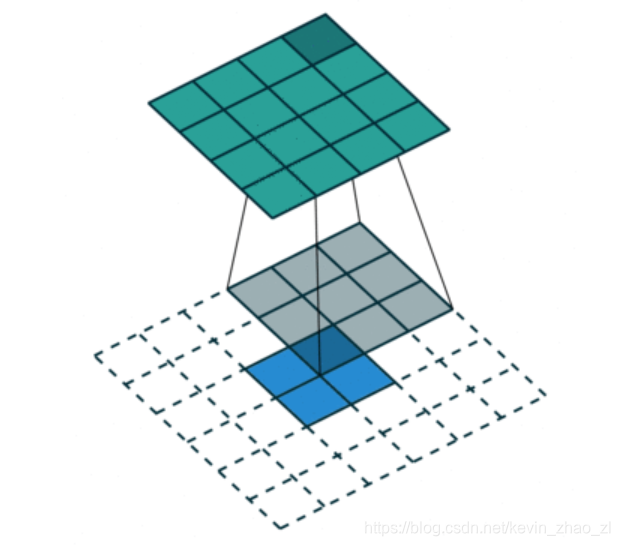
在TensorFlow框架中,反卷积过程如下:
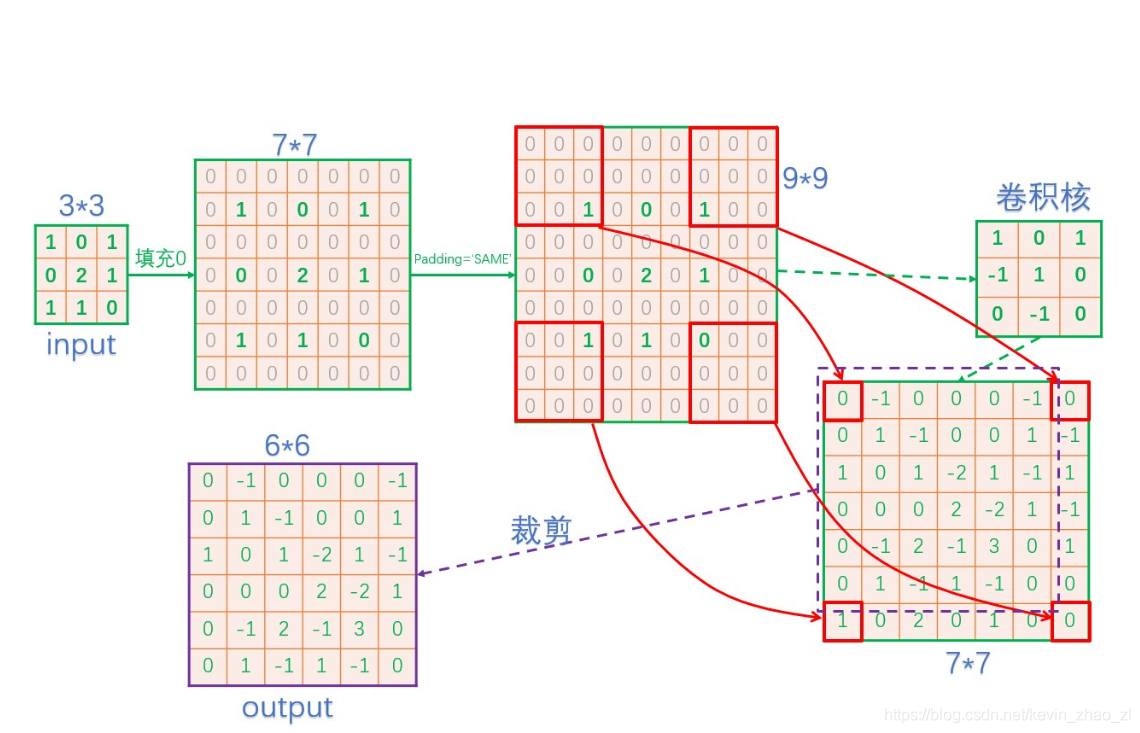
3.3 跨层结构(skip architecture)
首先贴上论文中的结构图:
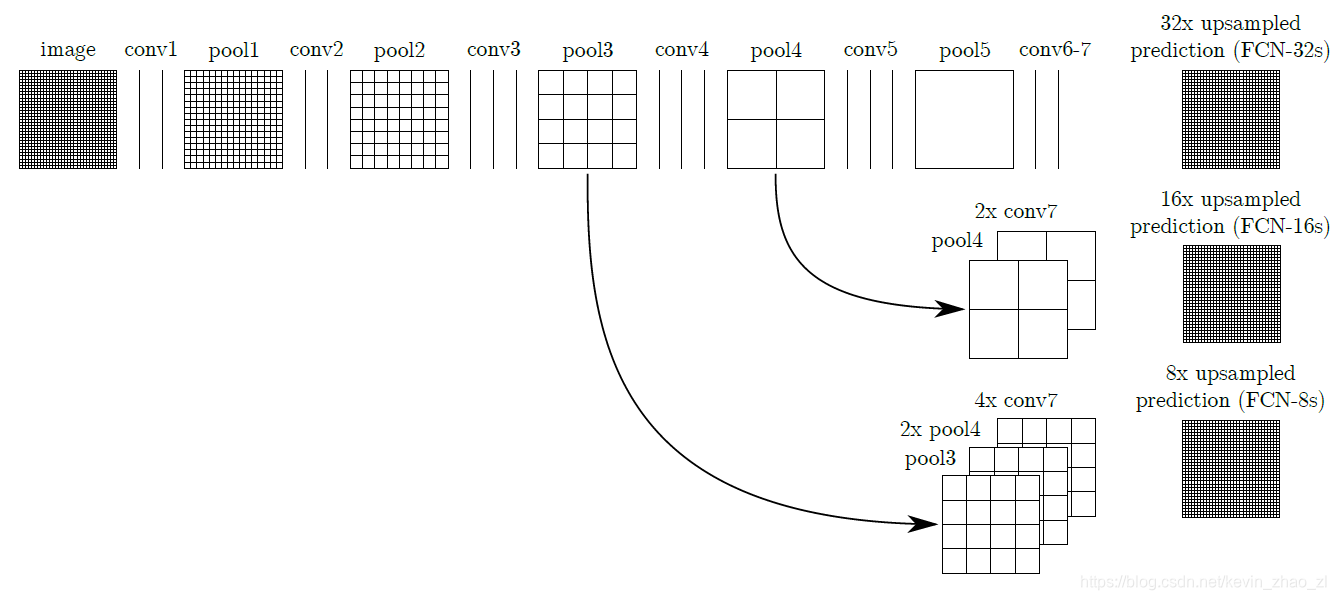
首先是基础的五步操作:
- Input n convs + 1 max Pooling poo1:: Input
- pool1 n convs + 1 max Pooling poo2:: Input
- pool2 n convs + 1 max Pooling poo3:: Input
- pool3 n convs + 1 max Pooling poo4:: Input
- pool4
n convs + 1 max Pooling
poo5::
Input
应用跳跃结构得到三种不同的模型: - 直接对 pool5 进行 32x 上采样后,将得到的特征图扔给Softmax分类器,得到密集预测结果 FCN-32s
- 对 pool5 进行 2x 上采样得到与 pool4 尺寸一样的上采样特征,并于 pool4 逐点相加得到特征图,对此特征图进行 16x 上采样,将得到的特征图扔给Softmax分类器,得到密集预测结果 FCN-16s
- 对 pool5 进行 2x 上采样得到与 pool4 尺寸一样的上采样特征,对此特征进行 2x 上采样得到与 pool3 尺寸一样的上采样特征,并于 pool3 逐点相加得到特征图,对此特征图进行 8x 上采样,将得到的特征图扔给Softmax分类器,得到密集预测结果 FCN-8s
4. 训练
4.1 StageWise Training
- 将经典分类网络初始化,弃用全连接层为卷积层
- 从特征小图 16x16x4096 预测分割小图 16x16x21,之后上采样为大图。反卷积步长为32
- 融合pool4,反卷积步长16
- 融合pool3,反卷积步长8,得到效果最好的FCN-8s
4.2 其他细节
- 使用数据增强方式对最终结果影响不大(需要思考一波为什么和这种效果与GAN的联系);增加有效标注数量提升了最终的性能
- 参数:20 mini batch;固定学习率;动量 0.9;weight decay
- 微调:对整个网络进行微调对性能的提升不大,因为直接微调后几层就会达到前者70%左右的性能
- 没有类别平衡策略