最近看了BP神经网络(Back Propagation Neural Networks),对于其中误差反向传播公式的推导比较困惑,在参考周志华老师的《机器学习》和网上一些博客后,做出一个简单的还原。
1. BP网络模型及变量说明
1.1 模型简图
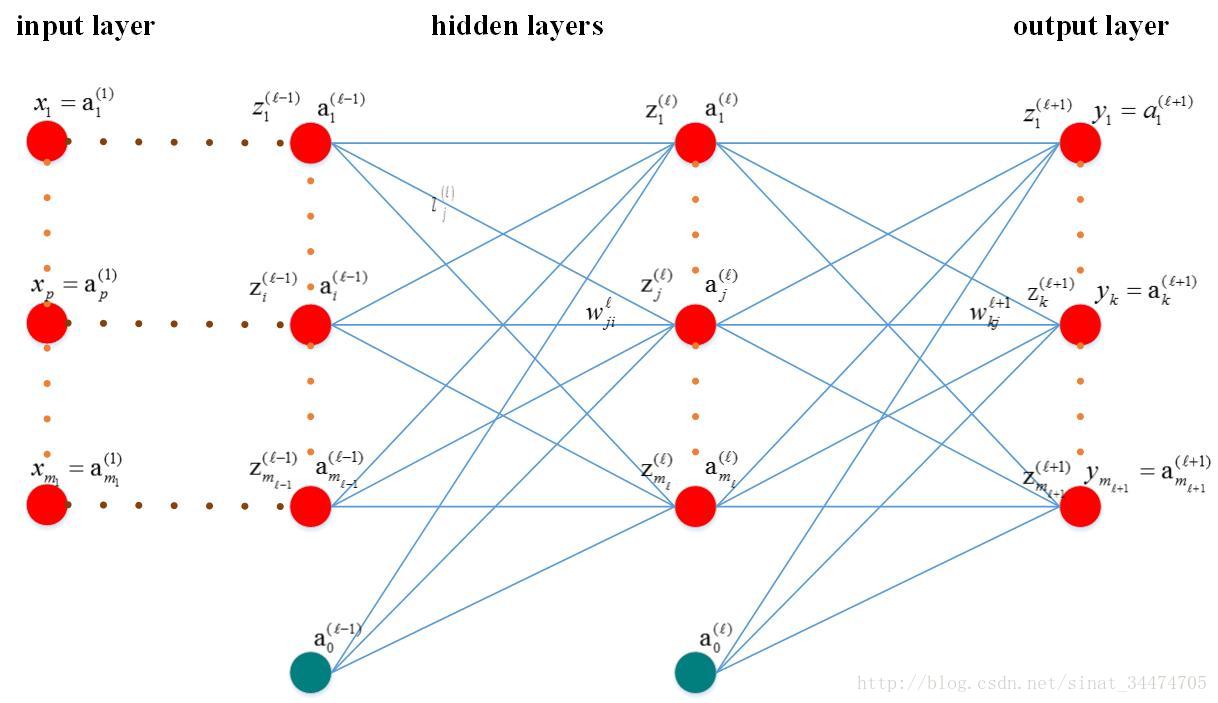
1.2 变量说明:
ml:第l层神经元个数
x(1)p: 输入层第p个神经元,p=1…m1;
yk : 输出层第k的神经元的输出,k=1…ml+1;
tk:输出层第k的神经元的目标值,k=1…ml+1;
z(l)j:第l层的第j的神经元的输入;
a(l)j:第l层第j个神经元的输出;
a(l)0:第l层的偏置项;
w(l)ji:第l−1层第i个神经元与第l层第j个神经元的连接权值;
扫描二维码关注公众号,回复: 11174268 查看本文章
h(.):激活函数,这里假设每一层各个神经元的激励函数相同(实际中可能不同);
Ep:网络在第p个样本输入下的偏差,n=1…N;
N:样本总数
2. 误差反向传播相关推导
2.1 正向传播(forward-propagation)
正向传播的思想比较直观,最主要的是对于激活函数的理解。对于网络中第l层的第j个神经元,它会接受来自第l-1层所有神经元的信号,即:
则经过该神经元后的输出值为:
对于多分类问题,网络输出层第k个神经元输出可表示为:
2.2 代价函数(cost function)
由2.1节公式可以得到BP网络在一个样本下的输出值,我们定义平方和误差函数(sum-of-square error function)如下:
2.3 反向传播(back-propagation)
这是BP神经网络最核心的部分,误差从输出层逐层反向传播,各层权值通过梯度下降法(gradient descent algorithm)进行更新,即:
下面我们以
由此我们得到了误差从输出层向低层反向传播的递推公式,进而可以求出误差对于每一层权值的梯度
3. 总结
BP神经网络是应用最多、最基本的一种人工神经网络,其精髓在于误差反向传播。后续的优化改动多在于激活函数、核函数上。
4. 参考文献
[1] 周志华,机器学习[M] , 清华大学出版社,2016.
[2] BP神经网络:误差反向传播公式的简单推导(博主:Meringue_zz)
