BP算法(即反向传播算法),适合于多层神经元网络的一种学习算法,它建立在梯度下降法的基础上。BP网络的输入输出关系实质上是一种映射关系:一个n输入m输出的BP神经网络所完成的功能是从n维欧氏空间向m维欧氏空间中一有限域的连续映射,这一映射具有高度非线性。它的信息处理能力来源于简单非线性函数的多次复合,因此具有很强的函数复现能力。这是BP算法得以应用的基础。
反向传播算法主要由两个环节(激励传播、权重更新)反复循环迭代,直到网络的对输入的响应达到预定的目标范围为止。
由一个数据算出得分值这个过程叫做前向传播,由一个得分值算出loss值,再有loss值往回传,什么样的w该更新,什么样的w该更新多大的值这个过程叫做反向传播。在反向传播的过程中最重要的是更新权重参数W。
下面我们用一个实例来说明:
如下图所示:
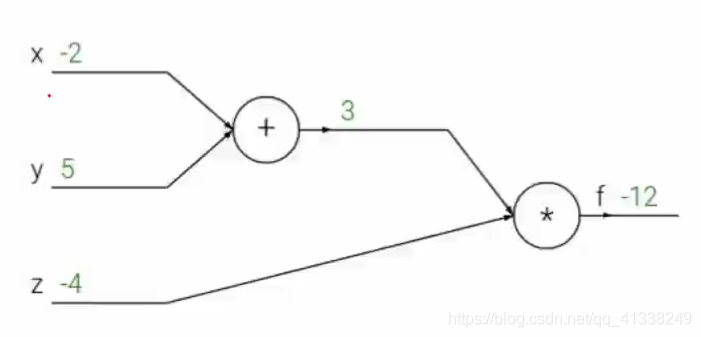
上图表示有三个样本点下x,y,z
1.对x和y进行求和操作
2.将x和y求出的和和z求乘积
f(x,y,z)=(x+y)*Z
例如我们分别给x,y,z赋值为-2,5,-4那么我们得出的f=-12
那么我们好比f就等于损失值为-12
得出损失值后我们要求x,y,z分别对f做出了多大的贡献
我们指定一个q=x+y对第一个节点进行操作
此时f=q*z
如果我们求z对f做了多少影响,只需对z进行求偏导值为3,意思就是如果z增大1倍,那么f值就会增大3倍
如果我们求q对f做了多少影响,只需对q进行求偏导值为-4,意思就是如果q增大1倍,那么f值就会减少4倍
如图所示: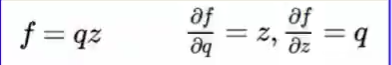
如果我们求x对f做了多大的贡献,那么我们先要求x对q做了多大的贡献,求对x求偏导如图所示:

q对f做的贡献为-4,所以x对f的贡献为1*(-4)为-4,这个过程称作为链式法则
我们的梯度要根据链式法则一层一层的往下传。这样我们就能更新我们的权重参数。
上面这个例子形象的讲解了反向传播的过程和如何实现权重的更新。
下面用代码实现:
import numpy as np
# "pd" 偏导
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def sigmoidDerivationx(y):
return y * (1 - y)
if __name__ == "__main__":
#初始化
bias = [0.35, 0.60]
weight = [0.15, 0.2, 0.25, 0.3, 0.4, 0.45, 0.5, 0.55]
output_layer_weights = [0.4, 0.45, 0.5, 0.55]
i1 = 0.05
i2 = 0.10
target1 = 0.01
target2 = 0.99
alpha = 0.5 #学习速率
numIter = 90000 #迭代次数
for i in range(numIter):
#正向传播
neth1 = i1*weight[1-1] + i2*weight[2-1] + bias[0]
neth2 = i1*weight[3-1] + i2*weight[4-1] + bias[0]
outh1 = sigmoid(neth1)
outh2 = sigmoid(neth2)
neto1 = outh1*weight[5-1] + outh2*weight[6-1] + bias[1]
neto2 = outh2*weight[7-1] + outh2*weight[8-1] + bias[1]
outo1 = sigmoid(neto1)
outo2 = sigmoid(neto2)
print(str(i) + ", target1 : " + str(target1-outo1) + ", target2 : " + str(target2-outo2))
if i == numIter-1:
print("lastst result : " + str(outo1) + " " + str(outo2))
#反向传播
#计算w5-w8(输出层权重)的误差
pdEOuto1 = - (target1 - outo1)
pdOuto1Neto1 = sigmoidDerivationx(outo1)
pdNeto1W5 = outh1
pdEW5 = pdEOuto1 * pdOuto1Neto1 * pdNeto1W5
pdNeto1W6 = outh2
pdEW6 = pdEOuto1 * pdOuto1Neto1 * pdNeto1W6
pdEOuto2 = - (target2 - outo2)
pdOuto2Neto2 = sigmoidDerivationx(outo2)
pdNeto1W7 = outh1
pdEW7 = pdEOuto2 * pdOuto2Neto2 * pdNeto1W7
pdNeto1W8 = outh2
pdEW8 = pdEOuto2 * pdOuto2Neto2 * pdNeto1W8
# 计算w1-w4(输出层权重)的误差
pdEOuto1 = - (target1 - outo1) #之前算过
pdEOuto2 = - (target2 - outo2) #之前算过
pdOuto1Neto1 = sigmoidDerivationx(outo1) #之前算过
pdOuto2Neto2 = sigmoidDerivationx(outo2) #之前算过
pdNeto1Outh1 = weight[5-1]
pdNeto1Outh2 = weight[7-1]
pdENeth1 = pdEOuto1 * pdOuto1Neto1 * pdNeto1Outh1 + pdEOuto2 * pdOuto2Neto2 * pdNeto1Outh2
pdOuth1Neth1 = sigmoidDerivationx(outh1)
pdNeth1W1 = i1
pdNeth1W2 = i2
pdEW1 = pdENeth1 * pdOuth1Neth1 * pdNeth1W1
pdEW2 = pdENeth1 * pdOuth1Neth1 * pdNeth1W2
pdNeto1Outh2 = weight[6-1]
pdNeto2Outh2 = weight[8-1]
pdOuth2Neth2 = sigmoidDerivationx(outh2)
pdNeth1W3 = i1
pdNeth1W4 = i2
pdENeth2 = pdEOuto1 * pdOuto1Neto1 * pdNeto1Outh2 + pdEOuto2 * pdOuto2Neto2 * pdNeto2Outh2
pdEW3 = pdENeth2 * pdOuth2Neth2 * pdNeth1W3
pdEW4 = pdENeth2 * pdOuth2Neth2 * pdNeth1W4
#权重更新
weight[1-1] = weight[1-1] - alpha * pdEW1
weight[2-1] = weight[2-1] - alpha * pdEW2
weight[3-1] = weight[3-1] - alpha * pdEW3
weight[4-1] = weight[4-1] - alpha * pdEW4
weight[5-1] = weight[5-1] - alpha * pdEW5
weight[6-1] = weight[6-1] - alpha * pdEW6
weight[7-1] = weight[7-1] - alpha * pdEW7
weight[8-1] = weight[8-1] - alpha * pdEW8
# print(weight[1-1])
# print(weight[2-1])
# print(weight[3-1])
# print(weight[4-1])
# print(weight[5-1])
# print(weight[6-1])
# print(weight[7-1])
# print(weight[8-1])
BP算法python实现参考https://blog.csdn.net/tudaodiaozhale/article/details/78632931