文章目录
1、Focal Loss理解
-
总述
我们知道object detection的算法主要可以分为两大类:two-stage detector和one-stage detector。前者是指类似Faster RCNN,RFCN这样需要region proposal的检测算法,这类算法可以达到很高的准确率,但是速度较慢。虽然可以通过减少proposal的数量或降低输入图像的分辨率等方式达到提速,但是速度并没有质的提升。后者是指类似YOLO,SSD这样不需要region proposal,直接回归的检测算法,这类算法速度很快,但是准确率不如前者。研究发现正负样本极不均衡是主要原因。Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。
-
损失函数形式
focal foss,这个损失函数是在标准交叉熵损失基础上修改得到的。这个函数可以通过减少易分类样本的权重,使得模型在训练时更专注于稀疏的难分类的样本;防止大量易分类负样本在训练中压垮检测器。
首先回顾二分类交叉熵损失:
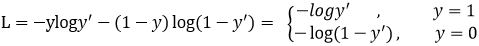
y ‘ y^` y‘是经过激活函数的输出,所以在0-1之间。可见普通的交叉熵对于正样本而言,输出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。假如某个样本x预测为1这个类的概率p=0.6,那么损失就是-log(0.6),注意这个损失是大于等于0的。如果p=0.9,那么损失就是-log(0.9),所以p=0.6的损失要大于p=0.9的损失,这很容易理解。此时的损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。那么Focal loss是怎么改进的呢?
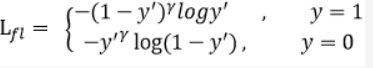

首先在原有的基础上加了一个因子,其中 γ \gamma γ>0使得减少易分类样本的损失。使得更关注于困难的、错分的样本。例如 γ \gamma γ为2,对于正类样本而言,预测结果为0.95肯定是简单样本,所以(1-0.95)的 γ \gamma γ次方就会很小,这时损失函数值就变得更小。而预测概率为0.3的样本其损失相对很大。对于负类样本而言同样,预测0.1的结果应当远比预测0.7的样本损失值要小得多。对于预测概率为0.5时,损失只减少了0.25倍,所以更加关注于这种难以区分的样本。这样减少了简单样本的影响,大量预测概率很小的样本叠加起来后的效应才可能比较有效。
此外,加入平衡因子 α \alpha α,用来平衡正负样本本身的比例不均:文中 α \alpha α取0.25,即正样本要比负样本占比小,这是因为负例易分。
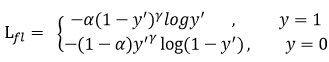
只添加 α \alpha α虽然可以平衡正负样本的重要性,但是无法解决简单与困难样本的问题。γ \gamma γ调节简单样本权重降低的速率,当 γ \gamma γ为0时即为交叉熵损失函数,当 γ \gamma γ增加时,调整因子的影响也在增加。实验发现 γ \gamma γ为2是最优。
总结
作者认为one-stage和two-stage的表现差异主要原因是大量前景背景类别不平衡导致。作者设计了一个简单密集型网络RetinaNet来训练在保证速度的同时达到了精度最优。在双阶段算法中,在候选框阶段,通过得分和nms筛选过滤掉了大量的负样本,然后在分类回归阶段又固定了正负样本比例,或者通过OHEM在线困难挖掘使得前景和背景相对平衡。而one-stage阶段需要产生约100k的候选位置,虽然有类似的采样,但是训练仍然被大量负样本所主导。
介绍
多尺度上目标识别是计算机视觉领域的一个基本挑战,解决这一挑战的基本方法就是“基于图像金字塔的特征金字塔(简称为特征图像金字塔)”,这些金字塔具有尺度不变性,可以通过扫描位置和金字塔层来检测大范围上的尺度。将图像金字塔各层提取特征的主要好处就在于产生了一个多尺度特征表示,这个表示的所有层语义很强,包括高精度的层。尽管这样,然而,对每层进行特征提取有很明显的限制,Inference time将急剧上升,在图像金字塔上进行end-to-end的训练内存上也不可行,最多只能在测试的时候将就用一下。Fast and Faster R-CNN也尽量避免采用这种方法。

注:特征图蓝色边界越宽,表示是语义越强的特征。
(a).使用图像金字塔构:造特征金字塔,速度很慢
(b).使用单一尺度特征更快地检测,如Fast and Faster R-CNN
©.用卷积计算得到金字塔特征阶层,如SSD,SSD为了避免使用低层的特征,从conv4 3 of VGG开始,这导致其不能使用特征阶层的高精度图,不能检测小物体。
RetinaNet
RetinaNet的主网络部分采用的是FPN结构,两个不同任务的子网络,一个是分类网络,一个是位置回归网络。
主干网使用卷积神经网络负责从整个图片提取特征,是一个现成的网络。第一个子网络使用卷积分类,第二个子网络使用卷积来边框回归。两个子网络是我们为one-stage密集型检测而提出的简单设计。虽然这些组件的细节有许多可能的选择,但大多数设计参数对实验中所示的具体值并不特别敏感。
FPN参考:https://blog.csdn.net/weixin_48167570/article/details/120867724

使用特征金字塔(FPN)作为RetinaNet的主干网。FPN给标准的卷积神经网络增加一个自顶向下的路径和侧向连接,来从图片的单一分辨率构建一个丰富的、多尺度的特征金字塔。金字塔的每一层以不同尺寸检测对象。FPN 改善了全卷积网络的多尺寸预测。
我们在ResNet结构上构建FPN,在P3~P7层上构建金字塔,l代表金字塔层级,金字塔每层都有256个通道。金字塔的具体实现与原本的FPN有小的差异。这些都不是关键的,需要强调的是使用FPN作为主干网的原因是,实验发现只使用ResNet层,最终AP值较低。

retinanet的主网络部分结构并不与FPN中提到的结构完全一致,retinanet使用特征金字塔层P3,P4,P5,P6,P7,其中,P3,P4,P5与FPN中的产生方式一样,通过上采样和横向连接从C3,C4,C5中产生,P6是在C5的基础上通过3x3的卷积核,步长为2的卷积得到的,P7在P6的基础上加了个RELU再通过3x3的卷积核,步长为2的卷积得到的。
在P3-P7层上选用的anchors拥有的像素区域大小从32x32到512x512,每层之间的长度是两倍的关系。每个金字塔层有三种长宽比例【1:2 ,1:1 ,2:1],有三种尺寸大小【 2 0 2^0 20, 2 1 / 3 2^{1/3} 21/3, 2 2 / 3 2^{2/3} 22/3】。总共便是每层9个anchors。大小从32像素到813像素。

分类子网络和回归子网络的参数是分开的,但结构却相似。都是用小型FCN网络,将金字塔层作为输入,接着连接4个3x3的卷积层,fliter为金字塔层的通道数(论文中是256),每个卷积层后都有RELU激活函数,这之后连接的是channel为KA(K是目标种类数,不包含背景,A是每层每个位置的anchors数,论文中是9)的3x3的卷积层,激活函数是sigmoid。
与分类子网络并行的,在FPN的每一层附加一个小的FCN用于边框回归。边框回归子网络和分类子网络设计是一样的,唯一不同最后一层通道数是4A个。边框回归的方法与RCNN的边框回归一样。不同于大多数设计,我们使用类别无关的边框归回,参数更少,同样有效。分类子网络和边框回归子网络共享结构,参数独立。