一、正负样本不均衡问题
Class Imbalance(正负样本不平衡) 带来的问题就是:样本中会存在大量的easy examples,且都是负样本(属于背景的样本)。这样,easy negative examples会对loss起主要贡献作用,会主导梯度的更新方向,网络学不到有用的信息,无法对object进行准确分类。
还有一个问题,为什么two stage不会有这样的问题呢或者为什么two stage没有one stage这么严重呢?
因为,对于two stage来说,首先利用RPN产生region proposal,这一步就已经删去了很多easy examples。我们对这些region proposal进行筛选,可以人为控制正负样本的比例为1:3。 此外,对于负样本的选取,可以通过在线难例挖掘,选取有利于网络更新的难分样本,让网络学习到有用的信息,进行参数的更新。
因此,one stage在检测mAP上不如two stage。
二、解决方案:Focal Loss
如下是未变化前的交叉熵(cross entropy) loss,以二分类为例:

通过实验发现,即使是easy examples(Pt >> 0.5),它的loss也很高,所以当这种样本的数量较多的时候,累计起来就会比较大了,甚至会超过那些概率较小的样本(hard example),导致对于那些hard example的学习效果不佳,这也就是为什么正负样本不均衡会导致学习效果不佳,太多的简单样本,累加起来,会产生较大的影响,量变产生质变。如下图蓝线:
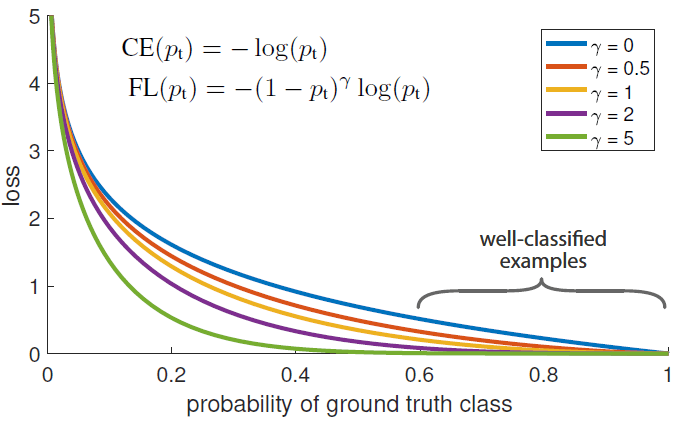
可见普通的交叉熵对于正样本而言,输出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。此时的损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。
因此,对于大量的easy negative examples,这些loss会主导梯度下降的方向,淹没少量的正样本的影响。所以,我们要解决:1> 正负样本不平衡;2>easy和hard examples不平衡问题 。
1、正负样本不均衡问题

为交叉熵加一个权重alpha,用来平衡正负样本本身的比例不均,其中权重因子的大小一般为相反类的比重。即负样本越多,给它的权重越小。这样就可以降低负样本的影响。文中alpha取0.25,即正样本要比负样本占比小,这是因为负例易分。
也可以这么理解:加一个小于1的超参数,相当于把算是Loss曲线整体往下拉一些,是的当概率较大的时候影响减小。
2、easy和hard examples不平衡问题
针对easy和hard样本,在原有的基础上加了一个因子,其中gamma>0使得减少易分类样本的损失。使得更关注于困难的、错分的样本。我们定义损失函数如下:
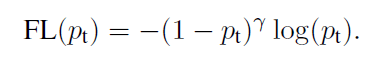
其中,gamma range from 0 to 5. 例如gamma为2,对于正类样本而言,预测结果为0.95肯定是简单样本,所以(1-0.95)的gamma次方就会很小,这时损失函数值就变得更小。而预测概率为0.3的样本其损失相对很大。对于负类样本而言同样,预测0.1的结果应当远比预测0.7的样本损失值要小得多。对于预测概率为0.5时,损失只减少了0.25倍,所以更加关注于这种难以区分的样本。这样减少了简单样本的影响,大量预测概率很小的样本叠加起来后的效应才可能比较有效。
举例:取γ=2,假如分类的概率是p=0.9,则原来的loss=-log(0.9) =0.046,现在-(1-0.9)^2 * log(0.9) = 0.00046,缩小了约100倍,加入分类概率是p=0.968,那么就会缩小约1000倍,如果概率小于0.5,如:p=0.4 , -log(0.4) == 0.39, -(1-0.4)^2 * log(0.4) = 0.14,只是减少了不到3倍。
这样做的好处就是:
- 如果一个样本分类错误了,概率很小(pt很小),这样相乘的系数(1-pt)就接近于1,对样本原本的分类影响不大;
- γ 起到了平滑的作用,作者的实验中,其等于2的效果最好。
正样本:概率越小,表示hard example,损失越大; 负样本:概率越大,表示hard example,损失越大。
这样,(正样本)当对于简单样本,Pt会比较大,所以权重自然减小了。针对hard example,Pt比较小,则权重比较大,让网络倾向于利用这样的样本来进行参数的更新(可参考上图思考)。 且这个权重是动态变化的,如果复杂的样本逐渐变得好分,则它的影响也会逐渐的下降。
gamma调节简单样本权重降低的速率,当gamma为0时即为交叉熵损失函数,当gamma增加时,调整因子的影响也在增加。实验发现gamma为2是最优。
3、Focal Loss的生成
最终,我们把这两种单独的改进进行合并,最终Focal Loss的形式为:
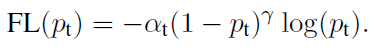
既做到了解决正负样本不平衡,也做到了解决easy与hard样本不平衡的问题。
这里的两个参数α和γ协调来控制,论文采用α=0.25,γ=2效果最好。
三、Caffe实现
修改prototxt:
layer {
name: "mbox_loss"
type: "MultiBoxFocalLoss" #change the type
bottom: "mbox_loc"
bottom: "mbox_conf"
bottom: "mbox_priorbox"
bottom: "label"
top: "mbox_loss"
include {
phase: TRAIN
}
propagate_down: true
propagate_down: true
propagate_down: false
propagate_down: false
loss_param {
normalization: VALID
}
focal_loss_param { #set the alpha and gamma, default is alpha=0.25, gamma=2.0
alpha: 0.25
gamma: 2.0
}
multibox_loss_param {
loc_loss_type: SMOOTH_L1
conf_loss_type: SOFTMAX
loc_weight: 1.0
num_classes: 2
share_location: true
match_type: PER_PREDICTION
overlap_threshold: 0.5
use_prior_for_matching: true
background_label_id: 0
use_difficult_gt: true
neg_pos_ratio: 3.0
neg_overlap: 0.5
code_type: CENTER_SIZE
ignore_cross_boundary_bbox: false
mining_type: NONE #do not use OHEM(online hard example miniing)
}
}
参考链接:https://blog.csdn.net/LeeWanzhi/article/details/80069592
caffe相关配置:https://blog.csdn.net/wfei101/article/details/79477542
Focal Loss的Caffe源码:https://download.csdn.net/download/duan19920101/12150017