公式推导:https://github.com/zimenglan-sysu-512/paper-note/blob/master/focal_loss.pdf
使用的代码:https://github.com/zimenglan-sysu-512/Focal-Loss
在onestage的网络中,正负样本达到1:1000,这就会出现两个问题:1.样本不平衡 2.负样本主导loss。虽然负样本的loss小(因为大量的负样本是easy example,大量负样本是准确率很高的第0类),但个数众多,加起来的loss甚至大于了正样本的loss
focal loss先解决了样本不平衡的问题,即在CE上加权重,当class为1的时候,乘以权重alpha,当class为0的时候,乘以权重1-alpha,这是最基本的解决样本不平衡的方法,也就是在loss计算时乘以权重。注意下面的图:alpha下面有个坐标t,也就是说alpha针对不同类别,值并不一样

尝试了样本不平衡改变权重后,paper就给出了focal loss的公式,实际上就是在CE前加了一个(1-pt)的gama次方,也就是说,如果你的准确率越高,gama次方的值越小,整个loss的值也就越小。也就是说,gama次方就是用来衰减的,准确率越高的样本衰减越多,越低的衰减的越少,这样整个loss就是由准确率较低的样本主导了。对于onestage的网络,loss由负样本主导,但这些负样本大多是准确率很高的,经过focal loss后就变成了正负样本共同主导,或者说是概率低的主导。这一点和ohem很像,ohem是让loss大的进行训练。
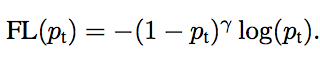
知乎上有人说:
focal loss相比OHEM的提升点在于,3:1的比例比较粗暴,那些有些难度的负样本可能游离于3:1之外。之前实验中曾经调整过OHEM这个比例,发现是有好处的,现在可以试试focal loss了。
paper中单独做了一个实验,就是直接在CE上加权重,得到的结果是alpha=0.75的时候效果最好,也就是说,正样本的权重为0.75,负样本的权重为0.25,正样本的权重大于负样本,因为本身就是正样本个数远少于负样本。加了gama次方后,alpha取0.25的时候效果最好,也就是说,正样本的权重为0.25,负样本的权重为0.75,这个时候反而负样本的权重在增加,按道理来说,负样本个数这么多,应该占loss主导,这说明gama次方已经把负样本整体的loss衰减到需要加权重的地步。
paper中alpha取0.25,gama取2效果最好
代办项:知乎上很多人说这个很boosting很像,为什么?