1 正交化
正交化的含义是在设计系统时,应该使得系统一个组件/参数的变化对另一个组件/参数的影响尽可能小。这样就可以相对简单的实验系统的各个组成部分,可以减小系统的验证和测试时间。
开发一个有监督机器学习系统时,应该依次序完成四件事情:
- 训练集要对代价函数拟合的很好,如果拟合的不好,可以尝试规模更大的网络结构或者尝试使用更好的优化算法;
- 验证集要对代价函数拟合的很好,如果拟合的不好,可以尝试添加正则化或者增加训练集的规模;
- 测试集要对代价函数拟合的很好,如果拟合的不好,可以使用一个更大的验证集;
- 训练结果要在实际应用中表现的很好,如果表现不好,说明没有设置正确的验证/测试集,或者定义的代价函数没有很好的描述实际应用。
2 单实数评价指标
在开始机器学习模型训练之前,首先确定一个单实数的评价指标,从而可以快速的验证自己使用不同策略训练得到的模型的优劣。接着再以最好的那个模型为起点,继续调试改善算法性能。
对于二分类任务,主要的指标有查准率(precision)和查全率(recall)。
| actual True | actual False | |
|---|---|---|
| predict True | true positive(TP) | false positive(FP) |
| predict False | false negative(FN) | true negative(TN) |
查准率,预测为正例的样本中有多少是真正的正例。
查全率,真实正例中有多少被预测为正例。
用于划分为正例的阈值越大,查准确越高,但查全率越低;阈值越小,查准率越低,但查全率越高。如何使用一个指标兼顾查准率和查全率呢?答案是使用查准率和查全率的调和平均。即单一的实数评价指标: ,F1值越大,表示模型的整体性能越好。
满足指标和优化指标
设计一个机器学习系统时,需要考虑很多的性能指标,很多时候把这些性能指标组成一个单实数评价指标难度很大,此时可以根据具体的需要将性能指标分为满足性能指标和优化性能指标两类。
如下图所示的示例,假设对系统的要求时在运行时间小于100ms的情况下最大化识别精度。我们可以设计一个单实数评价指标为
,但是这个评价指标设计的太过刻意。我们可以将指标分为优化指标和满足指标两类,在本例中,可以把运行时间小于等于100ms作为满足指标,把准确率作为优化指标。最终得到的评价标准为:
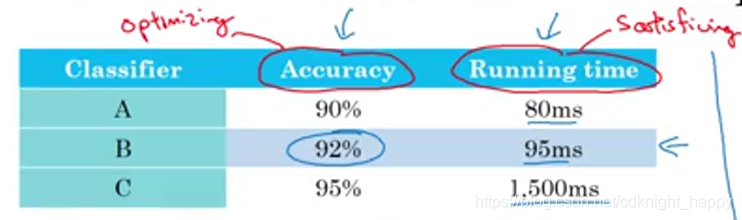
一般在N个评价指标的情况下,会选择其中一个作为优化指标,剩余的N-1个指标作为满足指标。比如在人脸识别任务中,我们可以要求在误识率小于1e-3且识别时间小于500ms的情况下最大化识别准确率,那么误识率和识别时间就是满足指标,准确率就是优化指标。
3 训练/验证/测试集的划分
各数据集作用:
训练集用于训练模型;
验证集用于对不同的算法/超参数进行交叉验证选择最优算法/超参数,再基于选定的算法/超参数在训练集上进行模型训练;
测试集用于最终的模型测试。
训练/验证/测试集的划分对最终的系统性能具有关键的影响。
划分原则:
应该按照同分布的原则随机选取验证/测试集,也就是说应该把全部数据打散,抽取验证集和测试集,在验证集上交叉验证选择算法/超参数,在测试集上进行模型的测试。验证集表示训练过程要瞄准的靶心,如果验证集和测试集分布不一致或者给了错误的评价指标,那么就表示给定了一个错误的靶心,这种情况下想在测试集上取得好的实际应用效果是不可能的。目标错了,走的越远,错的越离谱。
验证/测试集一定要能够表征在实际应用中拟处理的数据的分布情况。验证&测试&实际应用中处理的数据必须是同分布的。
各数据集大小比例:
传统机器学习任务中,按照70%,30%的比例划分训练集和测试集,或者按照60%,20%,20%的比例划分训练、验证、测试集。但是在深度学习时代,由于总的训练样本规模很大,假设在大于1,000,000的情况下,可以按照98:1:1的比例划分训练/验证/测试集。
什么时候应该改变验证/测试集或者改变评价标准?
如果原始定义的验证/测试集+评价标准不符合用户的喜好或者在实际应用中表现不好,那么就应该修改验证/测试集和评价标准。
4 机器学习的参考标准

如上图所示,贝叶斯最优可以认为是可能达到的最小误差,之所以有贝叶斯最优而不是达到真正的100%的准确率是因为可能在图像识别的任务中,某些图像质量太差以至于根本无法正确识别。或者是在语音识别示例中,某些输入音频噪声太大以至于根本无法正确识别信息。所以贝叶斯最优估计的准确率也是低于1的。
在机器学习系统的准确度低于人脸识别准确度的情况下,可以通过使用多种手段快速提升机器学习系统的性能,但机器学习系统的性能一旦超过了人类的识别精度,再想快速提升就比较困难了。
为什么要对标人类的表现?
因为人类的确比较擅长某些任务,比如图像识别、音频分析等,人类能够取得的精度非常接近贝叶斯最优估计的精度。那么在机器学习算法的性能劣于人类表现时,可以通过获取更多的人类标注的数据、分析人类为何能够对某些样本进行正确识别、更好的进行方差和偏差的均衡等手段提升算法的表现。但是一旦通过这些手段将机器学习算法的性能提升到超过人类表现之后,再想继续提升算法性能时,上述三种手段都已失效,因此也就没有了更多的办法继续快速提升。
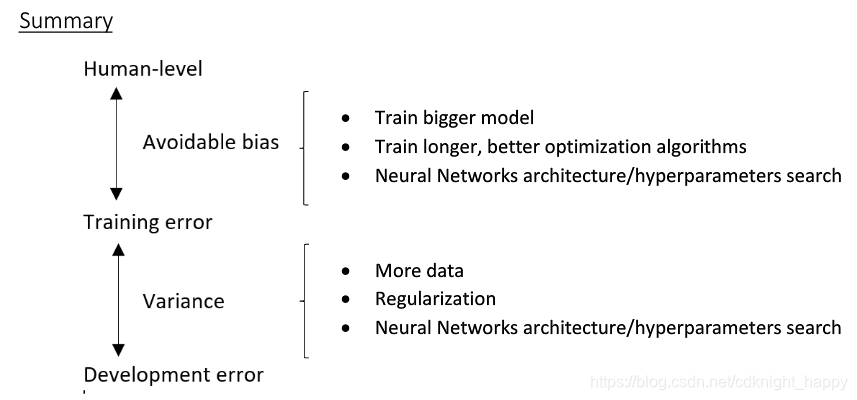
可避免偏差
在计算机视觉任务中,可以把人类的表现近似认为是贝叶斯最优估计。
假设在两个不同的计算机视觉分类任务上取得了下表所示的结果。
| 人类分类错误率 | 1% | 7.5% |
|---|---|---|
| 训练集分类错误率 | 8% | 8% |
| 验证集分类错误率 | 10% | 10% |
| 处理方案 | 降低偏差 | 降低方差 |
第一个任务中,训练集分类错误率和分类分类错误率之间的gap远大于训练集和验证集之间的分类错误率,因此改善模型效果的正确的做法降低偏差,可以使用更大的网络或者进行更多次的迭代优化等降低偏差的手段;第二个任务中,训练集和验证集分类错误率之间的gap远大于训练集和人类之间的分类错误率,所以改善模型性能的首要做法是降低模型的方差,可以通过使用更多的训练数据或者添加正则化等手段。在第二个任务中,努力尝试降低人类表现和训练集分类错误率之间的gap是非常难的。
将贝叶斯最优估计与模型在训练集上表现之间的差值称之为可避免误差;将训练集和验证集上表现之间的差值成为方差。
理解人类表现

上图问题的正确答案是应该把0.5% error作为人类的表现。这是因为人类表现作为贝叶斯最优的近似,那么既然一队有经验的医生可以达到0.5%的错误率,那么就应该把这个最优秀的结果作为人类表现。
如果出现了下表所示的情况:
| 一组人类专家的分类错误率 | 0.5 |
|---|---|
| 训练集分类错误率 | 0.3 |
| 验证集分类错误率 | 0.4 |
在这种情况下,表示没有足够的信息决定下一步应该如何做。因为训练集误差小于了人类的分类误差,此时无法确定是因为我们人类专家并没有做到最好的分类判断而贝叶斯最优估计误差小于0.3%,还是因为贝叶斯最优错误率就是0.5%而我们的模型对训练集过拟合造成了训练集错误率达到了0.3%。此时无法确定可避免偏差和方差的大小,因此就无法确定下一步的优化方向。
提升模型表现
5 进行误差分析
在完成一个模型的训练之后,假设模型在验证集/测试集上的效果不足够理想,应该针对错误样本进行针对性的误差分析。分析的方法是,选取一定量的错误处理的测试样本,统计错误样本的类别,根据各类型样本的比例从大到小针对性处理,改善模型效果。
核心点就是,分析错误样本类型,先处理主要矛盾,再解决次要矛盾。
6 如何处理误标记的训练样本
深度学习算法对于训练样本集中的随机误标记样本是非常鲁棒的。少量的误标记训练样本对模型训练影响不大。但若是发生了大量的系统性的误标记,那么可能影响就无法忽略了。
如何判断是否应该花费时间去修正错误标记的训练样本?答案是选取一定量的错误分类的验证/测试样本,统计由于误标记造成的错误处理的样本所占的比例,比如一张用于验证的猫的图像,模型识别其为猫,但由于图像误标记为狗造成了误识别,就需要统计这部分样本的比例。如果该比例值较大,则需要进行误标记训练样本的修正。
如果经过分析决定修正误标记的样本,那么有两条准则需要遵守:
- 同时寻找验证集和测试集中误标记的样本,之所以这样做,是要保证验证集和测试集服从同一分布,这个的重要性不再重复强调了,只有给定正确的靶心才能取得良好的效果;
- 一般训练集的规模远大于验证集和测试集,所以如果只修正了验证集和测试集,不进行训练集的误标记修正也是可以的,这样训练集和验证/测试集的分布就存在了细微的差异,可以通过其他的手段进行处理,这一点后续介绍。
7 开发一个机器学习任务的基本法则
处理新的问题:
快速设立验证/测试集,明确验证标准;
快速训练一个初始的模型;
基于初始模型的偏差/方差分析,决定下一步的修正方向。持续迭代,优化模型性能。
处理已有很多参考经验的问题:
分析state-of-art论文,站在巨人的肩膀上继续优化。
8 训练集和测试集分布存在差异时如何处理
如何划分数据集
假如准备训练一个猫分类模型。手头有爬取的20万张高清图像和1万张用户上传的模糊、角度不理想的图像。如何分配训练/验证/测试集?
方案一是将全部的21万张图像全部打散,选取205000图像作为训练集,2500验证集,2500测试集。这样做,保证了训练/验证/测试集全部服从同一分布,但是这样违背了最重要的原则,验证/测试集和实际应用时的数据分布不一致,这样就表示给定了一个错误的target。因此,该方案不可取。
正确的做法是,选取20万张网络高清图像+5000张用户上传图像作为训练集,2500张用户上传图像作为验证集,2500张用户上传图像作为测试集。这样虽然训练集和验证/测试集的分布略微不一致,但是验证/测试集和实际应用处理的数据分布一致,保证给定了一个正确的target。这样才可以保证训练出实际应用效果最优的模型。
训练集和验证/测试集分布不一致时如何进行偏差/方差分析
原来训练/验证/测试集分布一致时,我们可以根据贝叶斯最优估计误差、训练集误差、验证集误差三者之间的差值决定下一步的优化方向是减小偏差还是方差。但是如果训练集和验证/测试集分布不一致时,该如何进行判断?
正确的做法是,从训练集中划出一部分不参与训练的数据集,称之为training-dev set。这部分数据集和训练集同分布,但不参与模型的训练过程。最终比较贝叶斯最优估计、训练集误差、training-dev set的误差和验证集误差,就可以得到下一步的优化方向。如果主要差距来自于贝叶斯最优估计和训练集误差,那么下一步应该减小偏差;如果主要差距来自于训练集误差和training-sev set的误差,那么下一步应该减小方差;如果主要差距来自于training-dev set和验证集的误差,那么差距主要是由于data mismatch造成的。
贝叶斯最优误差
可避免偏差
训练集误差
方差
training-dev set 误差
data mismatch误差
验证集误差
对验证集过拟合的程度
测试集误差
如何解决数据不匹配造成的误差?
人工进行误差分析,定位训练集和验证/测试集之间的偏差;
对训练数据进行处理,使其更加接近于验证/测试数据。或者收集更多类似于验证/测试数据的训练样本。
可以人工合成训练数据,但是一定要小心,避免模型对人工合成数据的过拟合。
9 迁移学习
什么时候适合使用迁移学习,比如把针对任务A训练的模型进行迁移使其适用于任务B以提升任务B的性能?
- 任务A和B具有相同类型的输入,都是图像或者都是音频;
- 针对任务A的训练数据远多于针对任务B的训练数据;
- 任务A的低层特征对任务B有益。
10 多任务学习
多任务学习是指一个模型实现多个任务且比多个独立的模型性能更好。
多任务学习用多个logistic regression作为输出,因为一副图像既可以包含行人,又可以包含车辆。如果用softmax regression作为输出,一副图像只能有一个输出label,不适合用于多任务学习。
进行多任务分类时,预测结果为 的矩阵, 表示多任务的任务数, 表示样本数量,计算损失函数时使用 ,即计算各类别所有样本总的损失均值。
假设进行人、车、交通标志、红绿灯的分类,某幅图像标记了包含行人、不包含车辆,但没有标记是否包含交通标志和红绿灯。这样的样本也可以应用于多任务分类。只是在计算损失函数时,对 的求和不再是全部类别,而是标记了 的类别。即 。
多任务学习要想比单个任务单独学习取得更好的效果,需要满足下述三个条件:
- 训练的多个任务可以从共用的低层特征中受益;
- 每一个任务的训练数据量都非常接近,至少要保证所有任务联合起来的训练样本比单独一个任务的训练样本数要多得多;
- 可以通过训练一个足够大的网络同时对所有的任务取得良好的效果。
计算机视觉中的目标检测就是一种典型的多任务学习。
11 端到端学习
端到端学习表示使用单个网络完成多个阶段的任务。
进行端到端的学习需要足够多的数据,如果没有足够多的数据,适当的划分为多个任务是比较合适的,比如人脸识别任务划分为人脸检测和身份认定两个子任务。
端到端学习的优劣:
优点:
- 让数据说话,没有引入人类的偏见;
- 对手工设计组件的依赖大大减少。
缺点:
- 需要大量的训练数据;
- 排除了所有有用的手工设计组件。
是否应该使用端到端学习的判断依据:是否拥有足够多的训练数据去学习足够复杂的映射函数。
不是所有的任务都适合于使用端到端学习,可以把任务的一部分使用端到端学习完成,其余部分使用手工设计的组件进行完成。