本文使用六步法分别实现LeNet(1998)、AlexNet(2012)、VGGNet(2014)、InceptionNet(2014)、ResNet(2015)
除了卷积网络的“开篇之作”LeNet 以外,AlexNet、VGGNet、InceptionNet 以及 ResNet 这四种经典网络全部是在当年的 ImageNet 竞赛中问世的,它们作为深度学习的经典代表,使得 ImageNet 数据集上的错误率逐年降低。
LeNet
LeNet 即 LeNet5,由 Yann LeCun 在 1998 年提出,做为最早的卷积神经网络之一,是许多神经网络架构的起点。
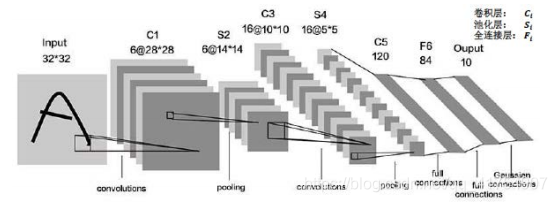
通过共享卷积核减少网络参数。在统计卷积神经网络层数时,一般只统计卷积计算层和全连接计算层,其余操作可视为卷积的附属。LeNet共有5层卷积,两层卷积,三层连续的全连接。
模型构建:
C(6个5*5的卷积核,步长为1,不使用全零填充‘valid’)
B(不使用批标准化None)
A(使用Sigmoid激活函数)
P(使用最大池化max,池化核2*2,步长为2,不使用全零填充‘valid’)
D(None)
C(6个5*5的卷积核,步长为1,不使用全零填充‘valid’)
B(不使用批标准化None)
A(使用Sigmoid激活函数)
P(使用最大池化max,池化核2*2,步长为2,不使用全零填充‘valid’)
D(None)
Flatten(把卷积送过来的数据拉直)
Dense(神经元:120,激活函数:sigmoid)
Dense(神经元:84,激活函数:sigmoid)
Dense(神经元:10,激活函数:softmax)
class LeNet5(Model):
def __init__(self):
super(LeNet5, self).__init__()
self.c1 = Conv2D(filters=6, kernel_size=(5, 5),
activation='sigmoid')
self.p1 = MaxPool2D(pool_size=(2, 2), strides=2)
self.c2 = Conv2D(filters=16, kernel_size=(5, 5),
activation='sigmoid')
self.p2 = MaxPool2D(pool_size=(2, 2), strides=2)
self.flatten = Flatten()
self.f1 = Dense(120, activation='sigmoid')
self.f2 = Dense(84, activation='sigmoid')
self.f3 = Dense(10, activation='softmax')
与最初的 LeNet5 网络结构相比,输入图像尺寸为 32 * 32 * 3,以适应 cifar10 数据集。模型中采用的激活函数有 sigmoid 和 softmax,池化层均采用最大池化,以保留边缘特征。
总体上看,诞生于 1998 年的 LeNet5 与如今一些主流的 CNN 网络相比,其结构相当简单,不过它成功地利用“卷积提取特征→全连接分类”的经典思路解决了手写数字识别的问题,对神经网络研究的发展有着很重要的意义。
AlexNet
AlexNet 的总体结构和 LeNet5 有相似之处。改进之处在于AlexNet共有8层,由五层卷积、三层全连接组成,输入图像尺寸为 224 * 224 * 3,网络规模远大于 LeNet5;使用 Relu 激活函数;进行了舍弃(Dropout)操作,以防止模型过拟合,提升鲁棒性;增加了一些训练上的技巧,包括数据增强、学习率衰减、权重衰减(L2 正则化)等。
AlexNet 的网络结构如图所示:
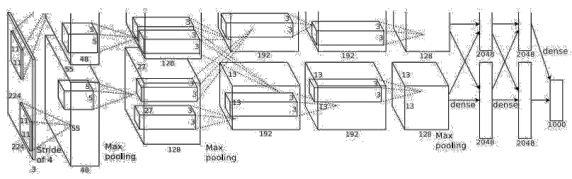
在 Tensorflow 框架下利用 Keras 来搭建 AlexNet 模型,这里做了一些调整,将输入图像尺寸改为 32 * 32 * 3 以适应 cifar10 数据集,并且将原始的 AlexNet 模型中的 11 * 11、7 * 7、5 * 5 等大尺寸卷积核均替换成了 3 * 3 的小卷积核。
Keras 实现 AlexNet 模型:
C(96个3*3的卷积核,步长为1,不使用全零填充‘valid’)
B(不使用批标准化Yes,‘LRN’)
A(使用rule激活函数)
P(使用最大池化max,池化核3*3,步长为2)
D(None)
C(256*3*3,步长为1,不使用全零填充‘valid’)
B(Yes,‘LRN’)
A(使用Relu激活函数)
P(max,3*3,步长为2)
D(None)
C(384*3*3,步长为1,全零填充‘same’)
B(None)
A(Relu)
P(None)
D(None)
C(384*3*3,步长为1,全零填充‘same’)
B(None)
A(Relu)
P(None)
D(None)
C(256*3*3,步长为1,全零填充‘same’)
B(None)
A(Relu)
P(max,核3*3,步长为2)
D(None)
Flatten
Dense(神经元:2048,激活函数:rule,Dropout:0.5)
Dense(神经元:2048,激活函数:rule,Dropout:0.5)
Dense(神经元:10,激活函数:softmax)
class AlexNet8(Model):
def __init__(self):
super(AlexNet8, self).__init__()
self.c1 = Conv2D(filters=96, kernel_size=(3, 3))
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.p1 = MaxPool2D(pool_size=(3, 3), strides=2)
self.c2 = Conv2D(filters=256, kernel_size=(3, 3))
self.b2 = BatchNormalization()
self.a2 = Activation('relu')
self.p2 = MaxPool2D(pool_size=(3, 3), strides=2)
self.c3 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
self.c4 = Conv2D(filters=384, kernel_size=(3, 3), padding='same',
activation='relu')
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same',
activation='relu')
self.p3 = MaxPool2D(pool_size=(3, 3), strides=2)
self.flatten = Flatten()
self.f1 = Dense(2048, activation='relu')
self.d1 = Dropout(0.5)
self.f2 = Dense(2048, activation='relu')
self.d2 = Dropout(0.5)
self.f3 = Dense(10, activation='softmax')
VGGNet
在 AlexNet 之后,另一个性能提升较大的网络是诞生于 2014 年的 VGGNet,其 ImageNet Top5 错误率减小到了 7.3 %。
VGGNet 网络的最大改进是在网络的深度上,由 AlexNet 的 8 层增加到了 16 层和 19 层,更深的网络意味着更强的表达能力,这得益于强大的运算能力支持。VGGNet 的另一个显著特点是仅使用了单一尺寸的 3 * 3 卷积核,事实上,3 * 3 的小卷积核在很多卷积网络中都被大量使用,这是由于在感受野相同的情况下,小卷积核堆积的效果要优于大卷积核,同时参数量也更少。VGGNet 就使用了 3 * 3 的卷积核替代了 AlexNet 中的大卷积核(11 * 11、7 * 7、5 * 5),取得了较好的效果(事实上课程中利用 Keras 实现 AlexNet 时已经采取了这种方式)。
VGGNet16 和 VGGNet19 并没有本质上的区别,只是网络深度不同,前者 16 层(13 层卷积、3 层全连接),后者 19 层(16 层卷积、3 层全连接)。
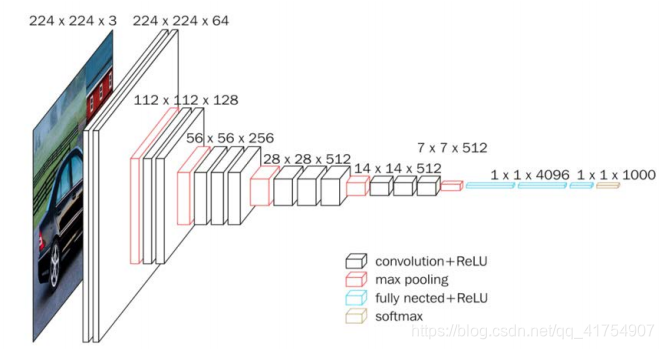
根据特征图尺寸的变化,可以将 VGG16 模型分为六个部分(在 VGG16 中,每进行一次池化操作,特征图的边长缩小为 1/2,其余操作均未影响特征图尺寸)
C(核:64*3*3,步长:1,填充:same )
B(Yes)A(relu)
C(核:64*3*3,步长:1,填充:same )
B(Yes)A(relu)
P(max,核:2*2,步长:2) D(0.2)
C(核:128*3*3,步长:1,填充:same )
B(Yes) A(relu)
C(核:128*3*3,步长:1,填充:same )
B(Yes) A(relu)
P(max,核:2*2,步长:2) D(0.2)
C(核:256*3*3,步长:1,填充:same )
B(Yes) A(relu)
C(核:256*3*3,步长:1,填充:same )
B(Yes) A(relu)
C(核:256*3*3,步长:1,填充:same )
B(Yes) A(relu)
P(max,核:2*2,步长:2) D(0.2)
C(核:512*3*3,步长:1,填充:same )
B(Yes) A(relu)
C(核:512*3*3,步长:1,填充:same )
B(Yes) A(relu)
C(核:512*3*3,步长:1,填充:same )
B(Yes) A(relu)
P(max,核:2*2,步长:2) D(0.2)
C(核:512*3*3,步长:1,填充:same )
B(Yes) A(relu)
C(核:512*3*3,步长:1,填充:same )
B(Yes) A(relu)
C(核:512*3*3,步长:1,填充:same )
B(Yes) A(relu)
P(max,核:2*2,步长:2) D(0.2)
Flatten
Dense(神经元:512,激活:relu,Dropout:0.2)
Dense(神经元:512,激活:relu,Dropout:0.2)
Dense(神经元:10,激活:softmax)
class VGG16(Model):
def __init__(self):
super(VGG16, self).__init__()
self.c1 = Conv2D(filters=64, kernel_size=(3, 3), padding='same') # 卷积层1
self.b1 = BatchNormalization() # BN层1
self.a1 = Activation('relu') # 激活层1
self.c2 = Conv2D(filters=64, kernel_size=(3, 3), padding='same', )
self.b2 = BatchNormalization() # BN层1
self.a2 = Activation('relu') # 激活层1
self.p1 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d1 = Dropout(0.2) # dropout层
self.c3 = Conv2D(filters=128, kernel_size=(3, 3), padding='same')
self.b3 = BatchNormalization() # BN层1
self.a3 = Activation('relu') # 激活层1
self.c4 = Conv2D(filters=128, kernel_size=(3, 3), padding='same')
self.b4 = BatchNormalization() # BN层1
self.a4 = Activation('relu') # 激活层1
self.p2 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d2 = Dropout(0.2) # dropout层
self.c5 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b5 = BatchNormalization() # BN层1
self.a5 = Activation('relu') # 激活层1
self.c6 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b6 = BatchNormalization() # BN层1
self.a6 = Activation('relu') # 激活层1
self.c7 = Conv2D(filters=256, kernel_size=(3, 3), padding='same')
self.b7 = BatchNormalization()
self.a7 = Activation('relu')
self.p3 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d3 = Dropout(0.2)
self.c8 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b8 = BatchNormalization() # BN层1
self.a8 = Activation('relu') # 激活层1
self.c9 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b9 = BatchNormalization() # BN层1
self.a9 = Activation('relu') # 激活层1
self.c10 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b10 = BatchNormalization()
self.a10 = Activation('relu')
self.p4 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d4 = Dropout(0.2)
self.c11 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b11 = BatchNormalization() # BN层1
self.a11 = Activation('relu') # 激活层1
self.c12 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b12 = BatchNormalization() # BN层1
self.a12 = Activation('relu') # 激活层1
self.c13 = Conv2D(filters=512, kernel_size=(3, 3), padding='same')
self.b13 = BatchNormalization()
self.a13 = Activation('relu')
self.p5 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same')
self.d5 = Dropout(0.2)
self.flatten = Flatten()
self.f1 = Dense(512, activation='relu')
self.d6 = Dropout(0.2)
self.f2 = Dense(512, activation='relu')
self.d7 = Dropout(0.2)
self.f3 = Dense(10, activation='softmax')
总体来看,VGGNet的结构是相当规整的,它继承了 AlexNet中的Relu激活函数、Dropout操作等有效的方法,同时采用了单一尺寸的 3 * 3 小卷积核,形成了规整的 C(Convolution,卷积)、B(Batch normalization)、A(Activation,激活)、P(Pooling,池化)、D(Dropout)结构,这一典型结构在卷积神经网络中的应用是非常广的。
InceptionNet
InceptionNet 即 GoogLeNet,诞生于 2015 年,旨在通过增加网络的宽度来提升网络的能力,与 VGGNet 通过卷积层堆叠的方式(纵向)相比,是一个不同的方向(横向)。
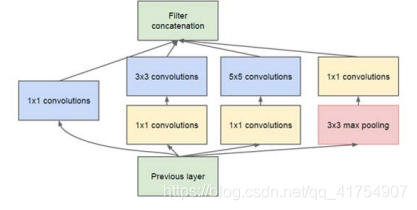
可以看到,InceptionNet 的基本单元中,卷积部分是比较统一的 C、B、A 典型结构,即卷积→BN→激活,激活均采用 Relu 激活函数,同时包含最大池化操作。
在 Tensorflow 框架下利用 Keras 构建 InceptionNet 模型时,可以将 C、B、A 结构封装在一起,定义成一个新的 ConvBNRelu 类,以减少代码量,同时更便于阅读。
InceptionNet引入了Inception结构块,在同一层网络内使用不同尺寸的卷积核,提升了模型的感知力,使用了批标准化,缓解了梯度消失。
InceptionNet的核心是它的基本单元Inception结构块,无论是GoogLeNet(Inception v1),还是InceptionNet的后续版本,例如v2、v3、v4,都是基于Inception结构块搭建的网络,Inception结构块在同一层网络中使用了多个尺寸的卷积核,可以提取不同尺寸的特征。
分支一:
C(核:16*1*1,步长:1,填充:same )
B(Yes) A(relu) P(None) D(None)
分支二:
C(核:16*1*1,步长:1,填充:same )
B(Yes) A(relu) P(None) D(None)
C(核:16*3*3,步长:1,填充:same )
B(Yes) A(relu) P(None) D(None)
分支三:
C(核:16*1*1,步长:1,填充:same )
B(Yes) A(relu) P(None) D(None)
C(核:16*5*5,步长:1,填充:same )
B(Yes) A(relu) P(None) D(None)
分支四:
P(Max, 核:3*3, 步长:1 ,填充:same )
C(核:16*1*1,步长:1,填充:same )
B(Yes) A(relu) P(None) D(None)
卷积连接器将以上四个分支按照深度方向堆叠到一起,构成Inception结构块的输出。由于Inception结构块中的卷积操作均采用了CBA结构,所以将其定义成一个新的类ConvBNRelu,可以减少代码量。
class ConvBNRelu(Model):
def __init__(self, ch, kernelsz=3, strides=1, padding='same'):
super(ConvBNRelu, self).__init__()
self.model = tf.keras.models.Sequential([
Conv2D(ch, kernelsz, strides=strides, padding=padding),
BatchNormalization(),
Activation('relu')
])
def call(self, x):
x = self.model(x, training=False)
return x
Inception结构块:
class InceptionBlk(Model):
def __init__(self, ch, strides=1):
super(InceptionBlk, self).__init__()
self.ch = ch
self.strides = strides
self.c1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c2_1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c2_2 = ConvBNRelu(ch, kernelsz=3, strides=1)
self.c3_1 = ConvBNRelu(ch, kernelsz=1, strides=strides)
self.c3_2 = ConvBNRelu(ch, kernelsz=5, strides=1)
self.p4_1 = MaxPool2D(3, strides=1, padding='same')
self.c4_2 = ConvBNRelu(ch, kernelsz=1, strides=strides)
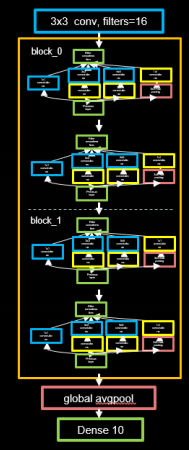
参数 num_layers 代表 InceptionNet 的 Block 数,每个 Block 由两个基本单元构成,每经过一个 Block,特征图尺寸变为 1/2,通道数变为 2 倍;num_classes 代表分类数,对于 cifar10数据集来说即为 10;init_ch 代表初始通道数,也即 InceptionNet 基本单元的初始卷积核个数。
class Inception10(Model):
def __init__(self, num_blocks, num_classes, init_ch=16, **kwargs):
super(Inception10, self).__init__(**kwargs)
self.in_channels = init_ch
self.out_channels = init_ch
self.num_blocks = num_blocks
self.init_ch = init_ch
self.c1 = ConvBNRelu(init_ch)
self.blocks = tf.keras.models.Sequential()
# InceptionNet 的基本单元,利用之前定义好的 InceptionBlk 类堆叠而成
for block_id in range(num_blocks):
for layer_id in range(2):
if layer_id == 0:
block = InceptionBlk(self.out_channels, strides=2)
else:
block = InceptionBlk(self.out_channels, strides=1)
self.blocks.add(block)
# enlarger out_channels per block
self.out_channels *= 2
self.p1 = GlobalAveragePooling2D()
self.f1 = Dense(num_classes, activation='softmax')
InceptionNet 网络不再像 VGGNet 一样有三层全连接层(全连接层的参数量占 VGGNet 总参数量的 90 %),而是采用“全局平均池化+全连接层”的方式,这减少了大量的参数。
ResNet
ResNet 即深度残差网络,由何恺明及其团队提出,是深度学习领域又一具有开创性的工作,通过对残差结构的运用,ResNet 使得训练数百层的网络成为了可能,从而具有非常强大的表征能力。
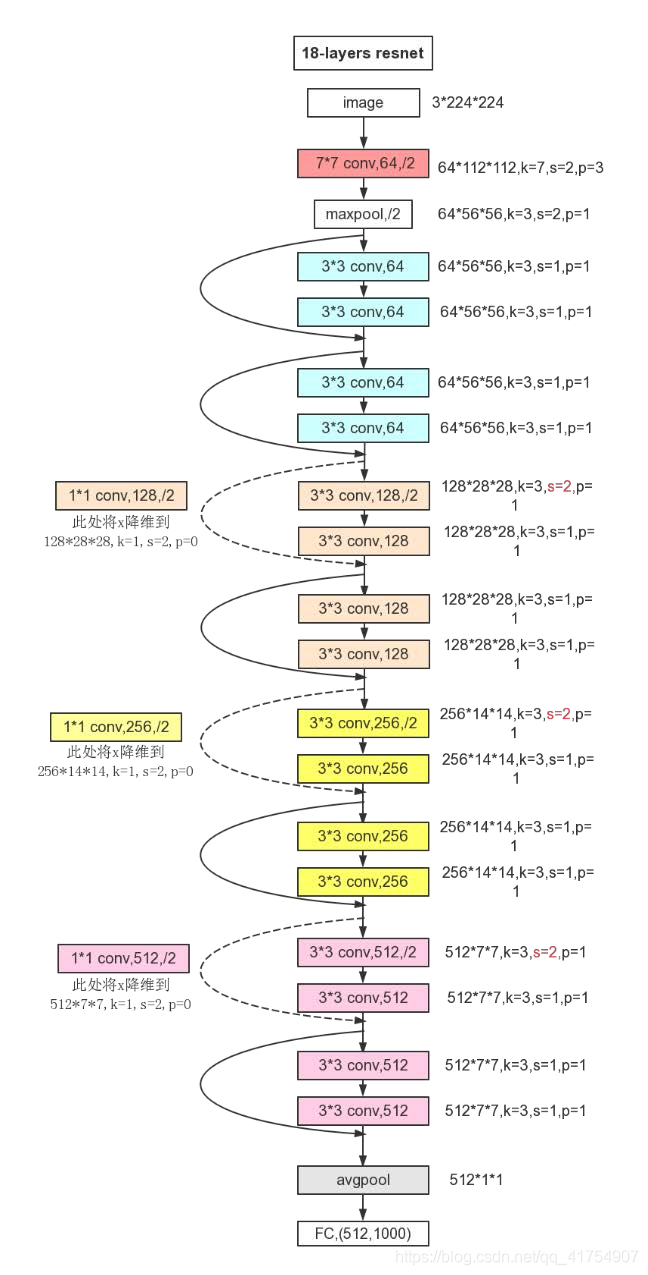
在残差结构中,ResNet 不再让下一层直接拟合我们想得到的底层映射,而是令其对一种残差映射进行拟合。若期望得到的底层映射为H(x),我们令堆叠的非线性层拟合另一个映射 F(x) := H(x) – x,则原有映射变为 F(x) + x。对这种新的残差映射进行优化时,要比优化原有的非相关映射更为容易。
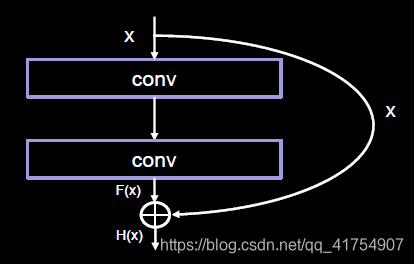
ResNet 引入残差结构最主要的目的是解决网络层数不断加深时导致的梯度消失问题,从之前介绍的 4 种 CNN 经典网络结构我们也可以看出,网络层数的发展趋势是不断加深的。这是由于深度网络本身集成了低层/中层/高层特征和分类器,以多层首尾相连的方式存在,所以可以通过增加堆叠的层数(深度)来丰富特征的层次,以取得更好的效果。
但如果只是简单地堆叠更多层数,就会导致梯度消失(爆炸)问题,它从根源上导致了函数无法收敛。然而,通过标准初始化(normalized initialization)以及中间标准化层(intermediate normalization layer),已经可以较好地解决这个问题了,这使得深度为数十层的网络在反向传播过程中,可以通过随机梯度下降(SGD)的方式开始收敛。
但是,当深度更深的网络也可以开始收敛时,网络退化的问题就显露了出来:随着网络深度的增加,准确率先是达到瓶颈(这是很常见的),然后便开始迅速下降。需要注意的是,这种退化并不是由过拟合引起的。对于一个深度比较合适的网络来说,继续增加层数反而会导致训练错误率的提升。
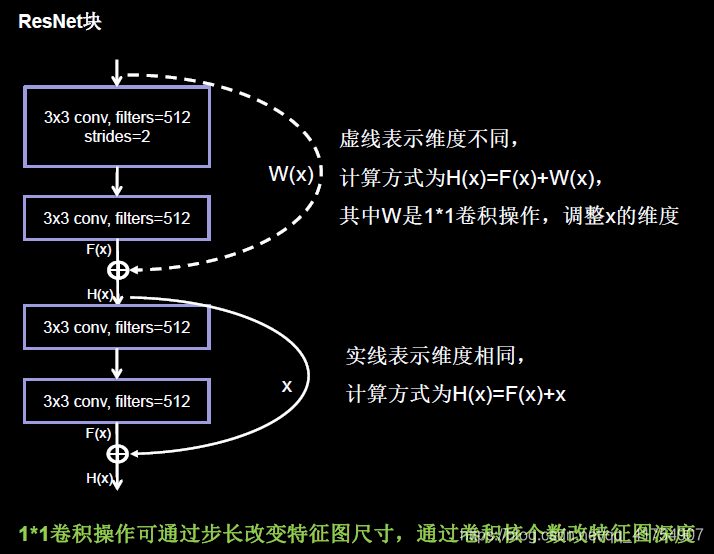
class ResnetBlock(Model):
def __init__(self, filters, strides=1, residual_path=False):
super(ResnetBlock, self).__init__()
self.filters = filters
self.strides = strides
self.residual_path = residual_path
self.c1 = Conv2D(filters, (3, 3), strides=strides, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.c2 = Conv2D(filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b2 = BatchNormalization()
# residual_path为True时,对输入进行下采样,即用1x1的卷积核做卷积操作,保证x能和F(x)维度相同,顺利相加
if residual_path:
self.down_c1 = Conv2D(filters, (1, 1), strides=strides, padding='same', use_bias=False)
self.down_b1 = BatchNormalization()
self.a2 = Activation('relu')
class ResNet18(Model):
def __init__(self, block_list, initial_filters=64): # block_list表示每个block有几个卷积层
super(ResNet18, self).__init__()
self.num_blocks = len(block_list) # 共有几个block
self.block_list = block_list
self.out_filters = initial_filters
self.c1 = Conv2D(self.out_filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.blocks = tf.keras.models.Sequential()
# 构建ResNet网络结构
for block_id in range(len(block_list)): # 第几个resnet block
for layer_id in range(block_list[block_id]): # 第几个卷积层
if block_id != 0 and layer_id == 0: # 对除第一个block以外的每个block的输入进行下采样
block = ResnetBlock(self.out_filters, strides=2, residual_path=True)
else:
block = ResnetBlock(self.out_filters, residual_path=False)
self.blocks.add(block) # 将构建好的block加入resnet
self.out_filters *= 2 # 下一个block的卷积核数是上一个block的2倍
self.p1 = tf.keras.layers.GlobalAveragePooling2D()
self.f1 = tf.keras.layers.Dense(10, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
小结
对于这五种网络(加上最基本的 baseline 共 6 种),其测试集准确率曲线及 Loss 曲线如下。
LeNet5:
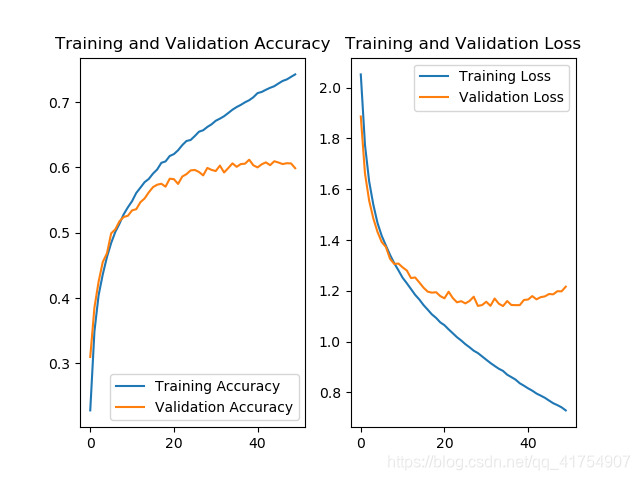
AlexNet8:
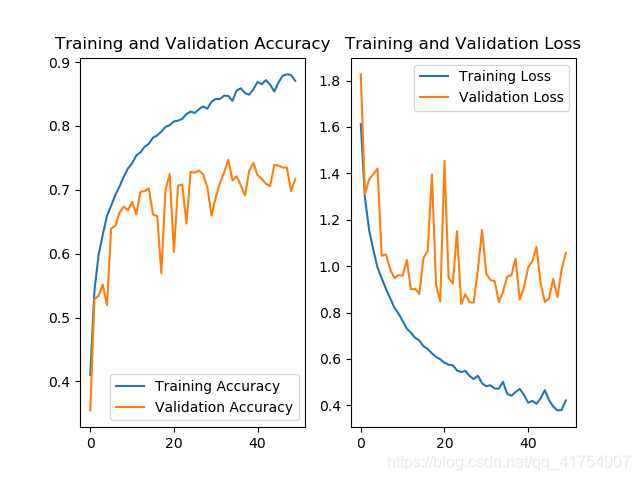
VGGNet16:
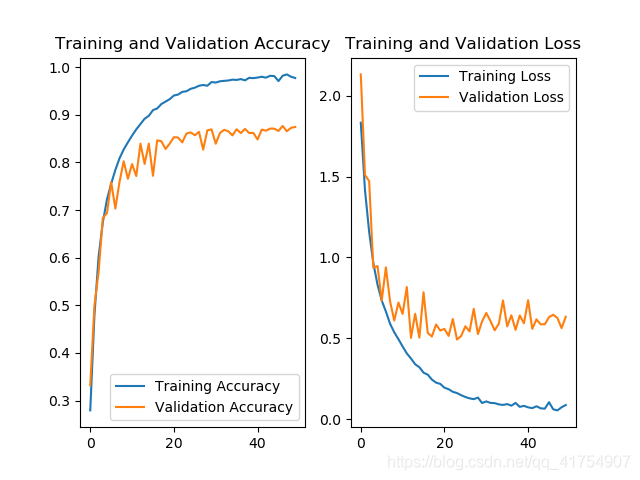
Inception10:
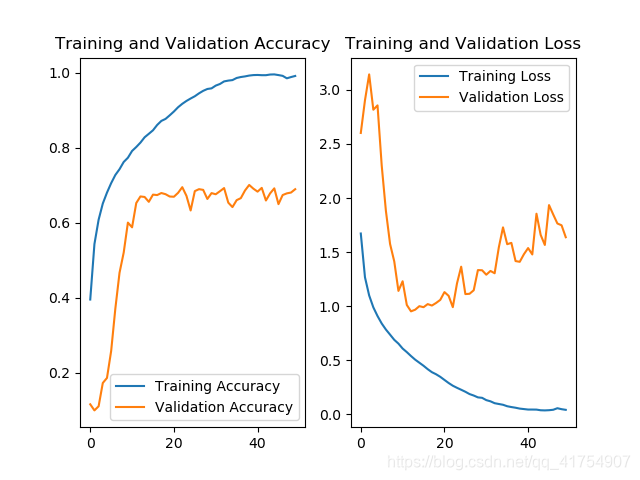
ResNet18:
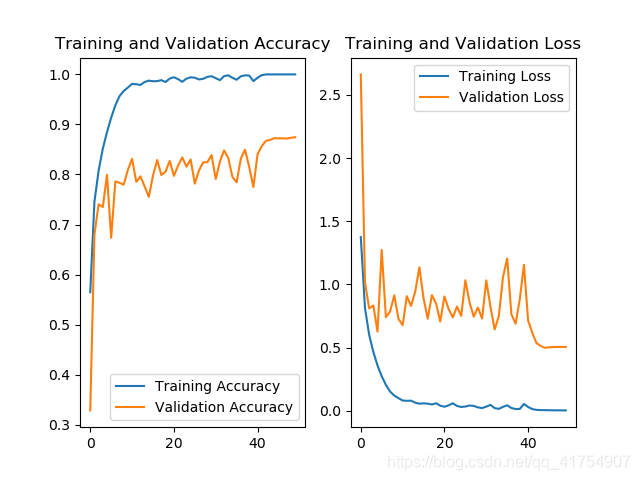
随着网络复杂程度的提高,以及 Relu、Dropout、BN 等操作的使用,利用各个网络训练 cifar10 数据集的准确率基本上是逐步上升的。五个网络当中,InceptionNet 的训练效果是最不理想的,首先其本身的设计理念是采用不同尺寸的卷积核,提供不同的感受野,但 cifar10 只是一个单一的分类任务,二者的契合度并不高,另外,由于本身结构的原因,InceptionNet 的参数量和计算量都比较大,训练需要耗费的资源比较多(完整的 InceptionNet v1,即 GoogLeNet 有 22 层,训练难度很大)。