文章目录
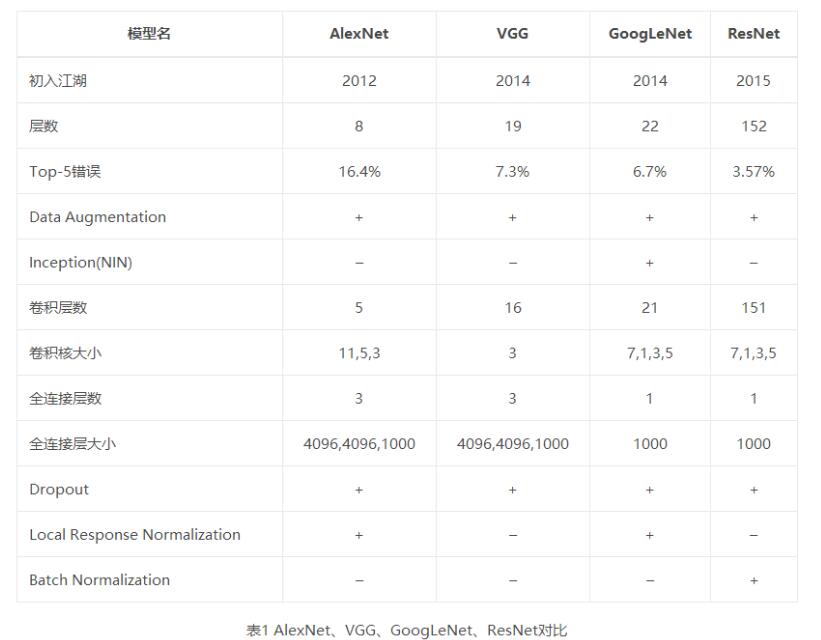
一、对比
二、AlexNet
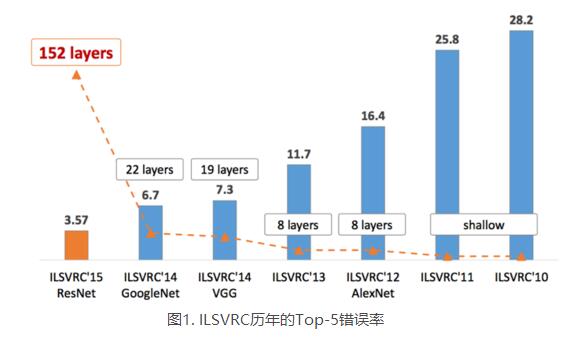
2012年ImageNet比赛分类任务的冠军,Top-5错误率为16.4%,让深度学习受到瞩目。
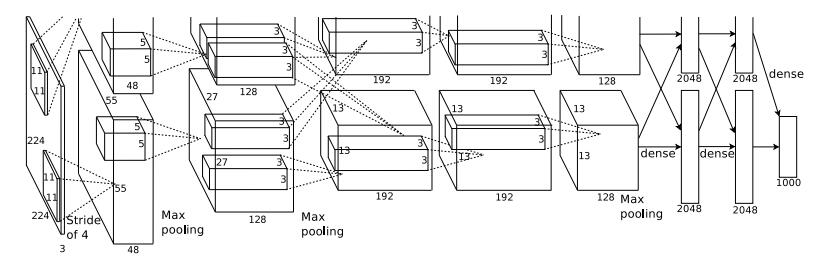
该网络输入为2272273(原始数据为2242243,经过预处理变为227),由5个“卷积+relu+pooling”和3个全连接层构成。
为什么将224预处理为227大小的图像:如果为(224*224)的,(224-11)/4不等于整数,而227的话刚好是整数,利于计算和更多信息的保留,通过resize将224变为227的
网络特点:
- 使用1500多万个代标记的图像训练,两台GPU,训练的5-6天
- 激活函数:Relu,防止梯度消失,加速训练网络
- 使用了数据增强,如镜像、裁剪、转化等
- 使用dropout在全连接层,防止了过拟合问题
- 采用了局部响应归一化,提高了精度
- 卷积核大小为11-5-3-3-3大小

深层网络学习出来的特征是什么样子的:
-
第一层:都是一些填充的块状物和边界等特征
-
中间层:学习一些纹理特征
-
更高层:接近于分类器的层级,可以明显的看到物体的形状特征
-
最后一层:分类层,完全是物体的不同的姿态,根据不同的物体展现出不同姿态的特征了。
为什么使用全连接:
-
在CNN中全连接起到分类器的作用,将前面提取的数据映射到标记空间,将学习到的特征整合,也就是矩阵乘法
-
一般都是使用softmax函数,将前面提取特征和权值乘积的得分函数映射到0-1之间的概率值
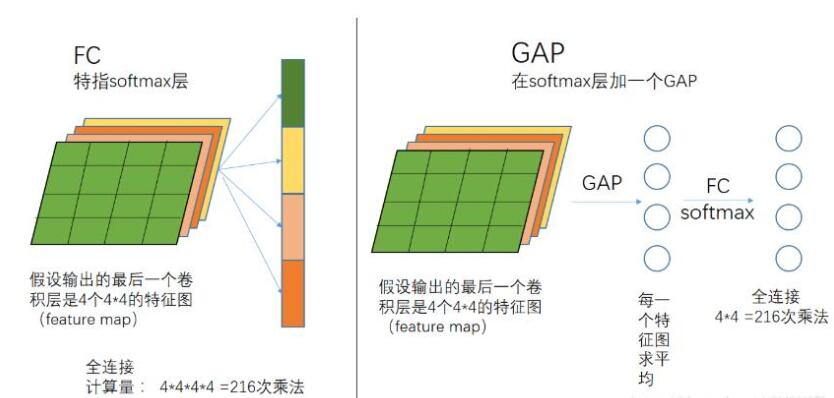
全连接为什么会被全局平均池化代替:
-
全连接参数众多,约占网络的80%,对计算机硬件要求很高,且网络容易过拟合
-
GPA:对输出的10个特征图分别求取平均,得到一个1*10的特征向量,在经过softmax映射,减少很多参数。
三、ZFNet
2013年冠军,整体架构和AlexNet很像,错误率为11.2%,也是一个8层的网络。
- ZFNet只用了130万张训练,AlexNet用了1500多万张
- 激活函数:Relu
- 损失函数:交叉熵损失
- 训练方式:小批量梯度下降
- 一台GPU训练12天
- 开发了可视化技术“解卷积网络”,有助于窥探CNN内部机理,提供了直观信息。
- ZFNet滤波器大小为77(步长为2),AlexNet滤波器为1111(步长为4),对于输入数据来说第一层卷积有助于保留大量的原始像素信息,大的滤波器会过滤掉大量相关信息。
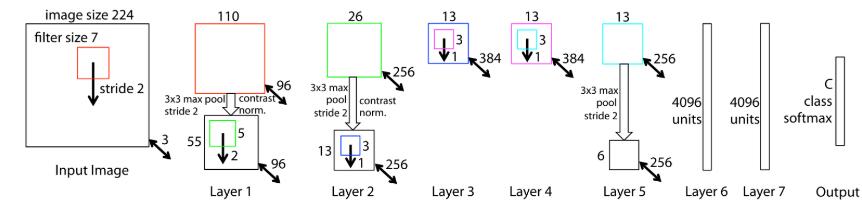
四、VGGNet
2014年识别任务亚军,定位任务冠军。构建了16~19层的深层网络,分类错误率达到了7.3%,适合做迁移学习。
该网络全部使用了33卷积核做卷积,22的卷积核做池化,通过不断加深网络结构来提升性能,
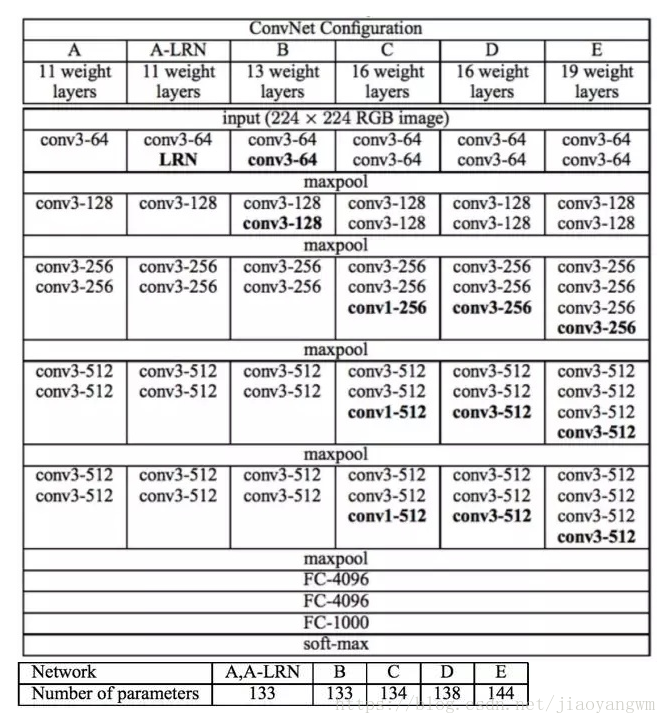
D组参数的效果最好,详细介绍如下:
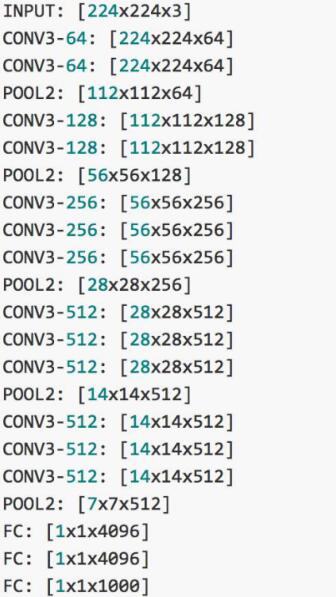
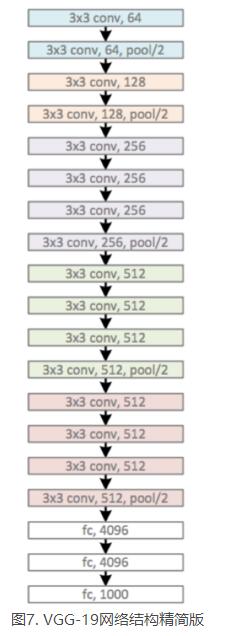
VGG-16比VGG-19少了三个卷积层。
VGGNet网络结构特点:
-
抛弃了LRN层
-
使用的卷积核都是33的(s=1,p=1),抛弃了大的卷积核,3个33卷积核的组合可以达到77感受野,可以使用更多的Relu函数,增加非线性,而且减少了参数,池化层都采用22的maxpooling(s=2)。
-
更加验证了网络越深,效果越好
-
使用小批量梯度下降,批尺寸为256
-
采用L2正则化
-
dropout:用在前两个全连接层之后,p=0.5
-
参数初始化:w~N(0,0.01),偏置为0
-
数据增强
五、GoogLeNet
2014年图像分类任务的冠军,错误率降低至6.7%,是一个22层的网络。
- VGGNet的参数量是AlexNet的三倍多,GoogLeNet考虑了内存和计算资源,只有五百万个参数,比六千万参数的AlexNet少12倍。
GoogLeNet出来之前,主流的网络结构是使网络更深更宽,但是这样会存在一些缺点:
-
训练集有限时,参数过多,出现过拟合
-
网络越大,计算复杂度越大,设计起来困难
-
网络层数增多的是,梯度消失越严重
GoogLeNet的优势:更适合大量数据的处理,尤其是内存或计算资源有限制的场合,计算效率有优势且分类准确率很高。
1、Inception-v1模型
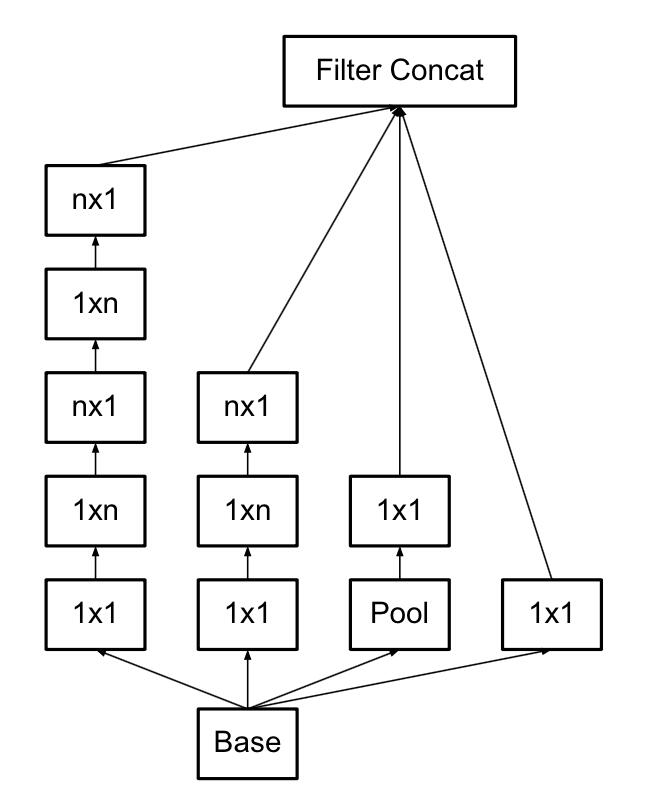
一般的卷积层只是一味的增加卷积层的深度,且每层卷积核只有一种大小,特征提取能力较弱,GoogLeNet提出的Inception模型,在同一层并行的使用不同大小的卷积核对经过padding的输入图像进行卷积,对不同的特征图在深度方向进行组合。
Inception-v1使用11、33、5*5的卷积核分别进行特征提取,之后将其进行组合。
下图表示了Inception-v1的模型:
原本的形式是未添加11的卷积核的,但是如果所有的卷积核都在上一层的所有输出层来做,那么55的卷积核计算量太大,所以添加了1*1的卷积核来起到降维的作用。
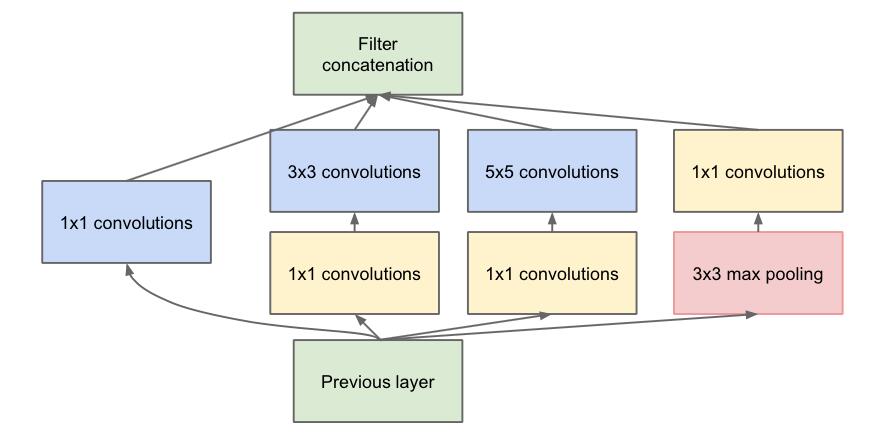
模型特点:
-
去除了全连接层,用平均池化来代替
-
Inception模型提高了参数利用率,可以反复堆叠形成一个大网络
2、Inception-v2模型
改进:
-
添加了BN层,减少了由数据分布不同而导致学习能力下降,和计算复杂增大的情况,使每层的输入都归一化。
-
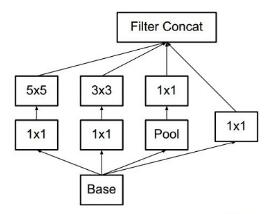
用两个33的卷积核代替v1模型的55,降低了参数数量,加速了计算
3、Inception-v3模型
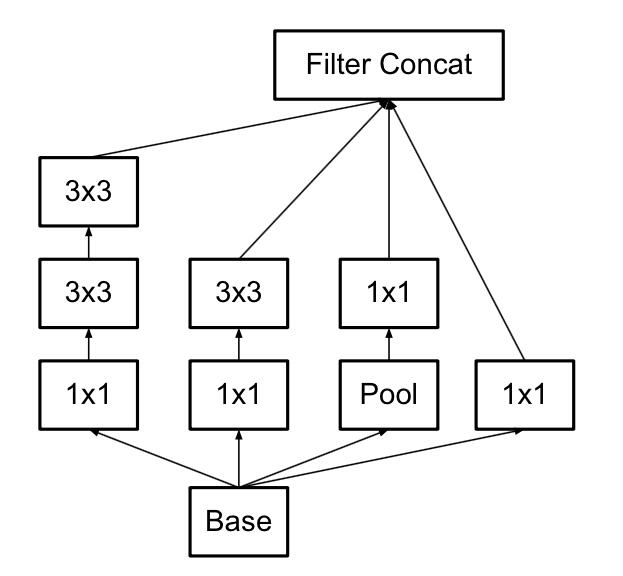
改进:最重要的改进就是分解,将33的分解为13和3*1的卷积
既然将大的卷积核分解为小的卷积核可以实现等效的效果,那么说明大的卷积核的部分参数是冗余的,也就是不需要5*5的卷积核提供的25个参数特征,可能是因为图像区域的关联性很强,卷积核参的关联性也很强,可以进一步压缩,相当于紧密网络到稀疏网络的转换。
Inception-v3提出了上图的分解方式,先用13的卷积核卷积,再接一个31的卷积核,可以明显的降低参数量和计算量。所以Inception-v3将所有的nn的卷积核都分解为 n1和1*n的叠加。
3×3的卷积使用3×1卷积和1×3卷积代替,这种结构在前几层效果不太好,但对特征图大小为12~20的中间层效果明显。
Inception-v3模型总共有46层,由11个Inception模块组成。其架构如所示:
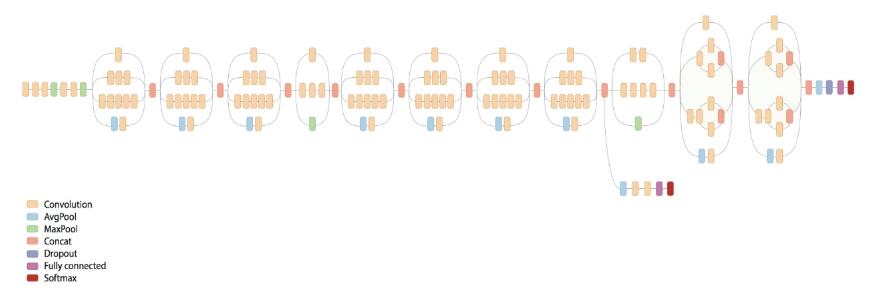
图中每个多通道的集合就是一个inception模块,共96个卷积层,一般迁移学习就会保留瓶颈层及其之前的参数,仅仅替换最后一层全连接层,重新进行微调来适应自己的项目。
4、Inception-v4模型
Inception-v3到inception-v4网络变得更深了,在GAP前Inception-v3包括了4个卷积模块运算(1个常规卷积块+3个inception结构),Inception-v4变成了6个卷积模块。对比两者的卷积核的个数,Inception-v4比Inception-v3也增多了许多。
5、GoogLeNet模型
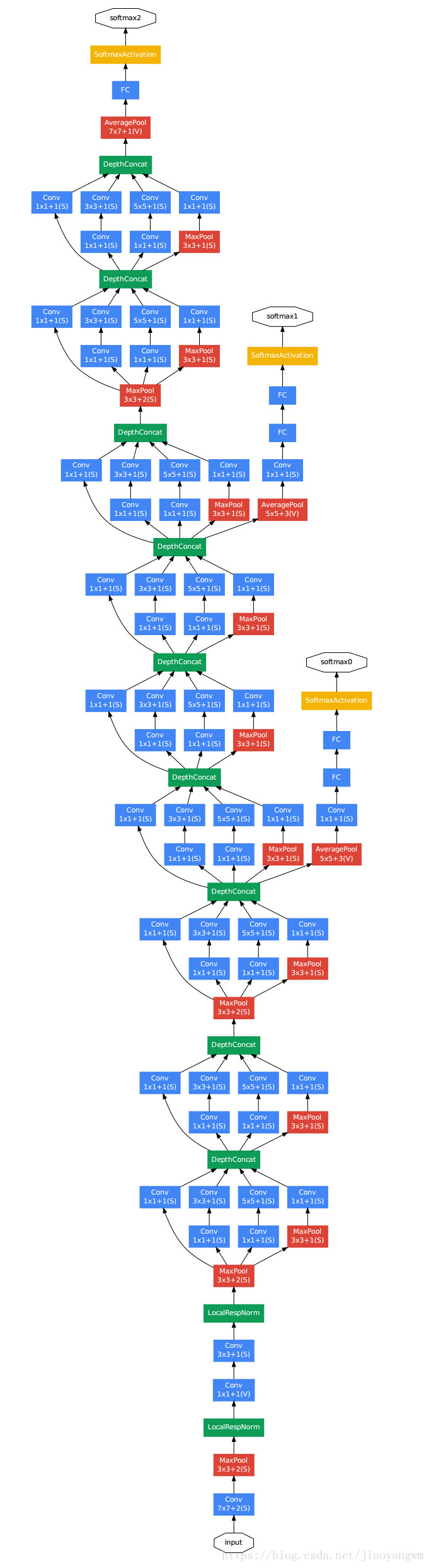
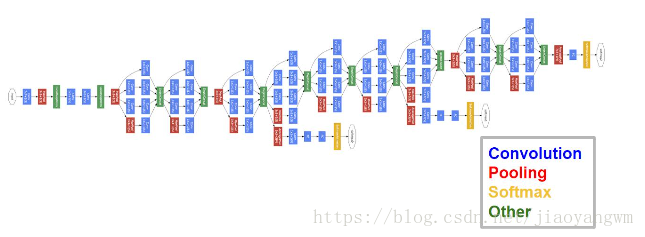
训练过程:先训练得到一组权重参数,也就是第一个分支softmax0,再用这些参数作为初始化参数,训练第二部分网络,得到第二个分支softmax1,再用这些参数作为初始化参数,训练第三部分网络,得到softmax2。
目的:为了避免梯度消失,网络额外增加两个辅助的softmax用于前向传播梯度,文章中说这两个辅助的分类器的loss应该加一个衰减系数,实际测试的时候,这两个额外的softmax会被去掉。
网络特点:
- 引入Inception模块,利用同层多种不同大小的卷积核提取特征并进行组合的方式提高了每层网络的特征提取能力
- 利用小卷积核叠加的方式实现大卷积核的作用,减少了参数量,可以使用更多的relu,引入更多的非线性
- 使用了BN,将输入归一化为标准的高斯分布,提高网络训练能力和训练速度
- 使用分支训练结构,辅助梯度传播,避免梯度消失
六、ResNet
2015年分类任务的第一名,错误率降低到3.57%,152层网络。
网络深度提高,带来的影响:常规的网络越来越深的情况下,会出现梯度消失
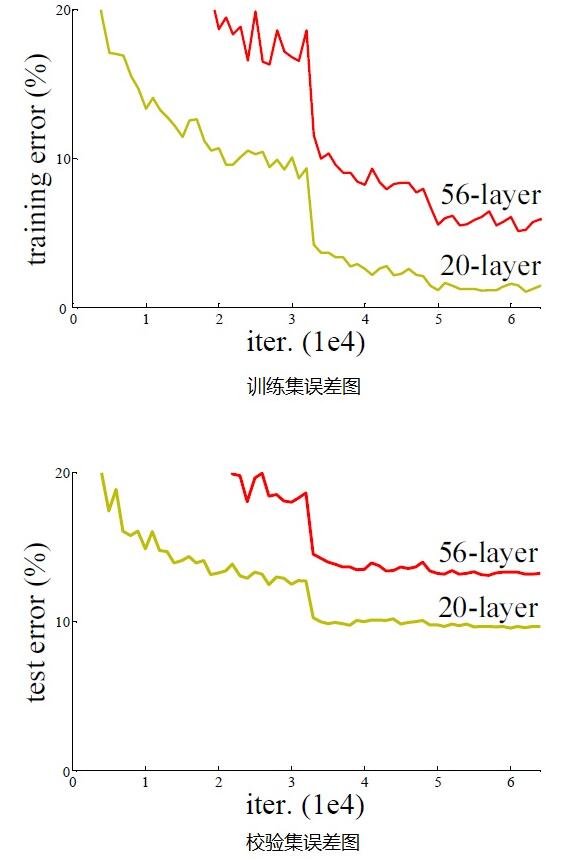
可以看出,随着网络层级的不断增加,模型精度不断得到提升,但是提升到20层以后的时候,训练精度和测试精度迅速下降,更加难训练。说明网络并不是越深越好。
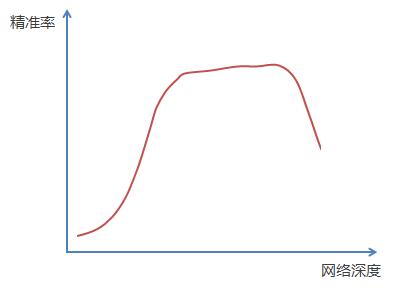
ResNet网络的思想来源:假设有一个较浅的网络达到了饱和的准确率,这时在它后面追加几个恒等映射,这样就增加了网络深度,且误差不会增加,也就是更深的网络不会带来训练集上误差的上升。
ResNet就是利用恒等映射将前一层的输出传递到后面层
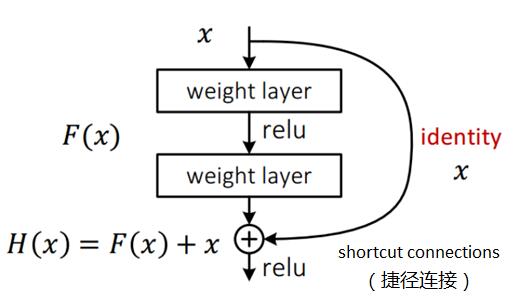
假设网络的输入为x,期望输出为H(x),如果直接学习的话,训练难度会很大,上图的残差网络是通过捷径连接,将本层的输入x直接传到本层输出,假设输入x和期望输出H(x)的残差为F(x),当F(x)=0的时候,输入和期望相等,也就是恒等变换,所以ResNet网络的训练目标就是将F(x)逼近于0,使网络深度加深,准确率不变。
训练目标:将目标和输入的残差逼近于0,使网络加深而准确率不降
为什么要很深的网络:图像是层次非常深的数据,所以要深层次的网络进行特征提取,网络深度对深层特征提取很有意义。
各条路线的意义:
-
**第一条直接向下的网络:**试图从x中直接学习残差F(x)
-
**第二条捷径网络:**直接传递x
-
**整合:**将两者相加,就是要求的输出映射H(x)
**为什么要添加捷径网络:**只有一条通路的反向传播会导致连乘的梯度消失,两条路会使得变为求和的形式,避免梯度消失。后面的层可以看见输入,不会因为信息损失而失去学习能力。
和传统网络的不同:传统网络每次会学习x->H(x)的完整映射,ResNet只学习残差的映射
反向传播的时候,捷径连接的梯度为1,传到前一层的梯度就会多一个1,更加有效的训练。
ResNet34(左)和ResNet50/101/152(右)示意图:
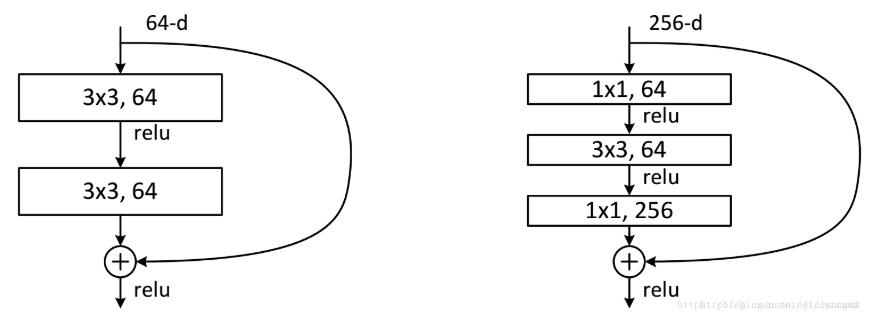
右边的结构可以用第一个11的卷积核将厚度为256的输入降到64维,然后再通过第二个11的卷积核恢复
