ZFNet
时间:
2013年
出处:
Matthew D.Zeiler 和 Rob Fergus (纽约大学)2013年撰写的论文:
Visualizing and Understanding Convolutional Networks
目的:
AlexNet的提出使得大型卷积网络开始变得流行起来,但是人们对于CNN网络究竟为什么能表现这么好,以及怎么样能变得更好尚不清楚,因此为了针对上述两个问题,提出了一个新颖的可视化技术,“理解”中间的特征层和最后的分类器层,并且找到改进神经网络的结构的方法
做法:
使用反卷积(Deconvnet),可视化特征图(feature map)
通过Deconvnet技术,可视化Alex-net,并指出了Alex-net的一些不足,最后修改网络结构,使得分类结果提升
与AlexNet相比,前面的层使用了更小的卷积核和更小的步长,保留了更多特征
成就:
ZFNet是2013年ILSVRC的冠军
贡献:
CNN领域可视化理解的开山之作,作者通过可视化解释了为什么CNN有非常好的性能、如何提高CNN性能,然后进行调整网络,提高了精度
论文主要贡献如下:
特征可视化
使用反卷积,可视化feature map
通过feature map可以看出,特征分层次体系结构
前面的层学习的是物理轮廓、边缘、颜色、纹理等特征,后面的层学习的是和类别相关的抽象特征
CNN学习到的特征具有平移和缩放不变性,但是,没有旋转不变性
对于CNN结构的改进
通过特征可视化可以知道,Krizhevsky的CNN结构学习到的第一层特征只对于高频和低频信息有了收敛,但是对于中层信息却还没有收敛;同时,第二层特征出现了混叠失真,这个主要是因为第一个卷积层的层的步长设置为4引起的,为了解决这个问题,作者不仅将第一层的卷积核的大小设置为7*7,同时,也将步长设置为2
对于遮挡的敏感性
通过遮挡,找出了决定图像类别的关键部位当,在输入图片中遮挡了学习到的特征时,分类效果会很差。
关联分析
作者认为深度结构隐形地学习到不同图像中一些特定结构的关联性。通过遮挡不同图像的相同结构,然后计算学习的特征与没有遮挡之前学习到的特征之间的差,然后这些差的Hamming距离Δ,当Δ越小时,说明了网络还是学习到了一定的结构关联性。(这个地方不理解)

特征提取的通用性
这个部分主要是作者通过实验说明了,将使用ImageNet2012数据集训练得到的CNN,在保持前面七层不变的情况,只在小数据集上面重新训练softmax层,通过这样的实验,说明了使用ImageNet2012数据集训练得到的CNN的特征提取功能就有通用性。
特征分析
作者通过实验证明了,不同深度的网络层学习到的特征对于分类的作用,说明了深度结构确实能够获得比浅层结构更好的效果。
通过实验,说明了深度增加时,网络可以学习到更具区分的特征。
底层特征在迭代次数比较少时就能收敛,高层需要的迭代次数比较多
越是高层的特征,其用来做分类的性能越好
技术分析
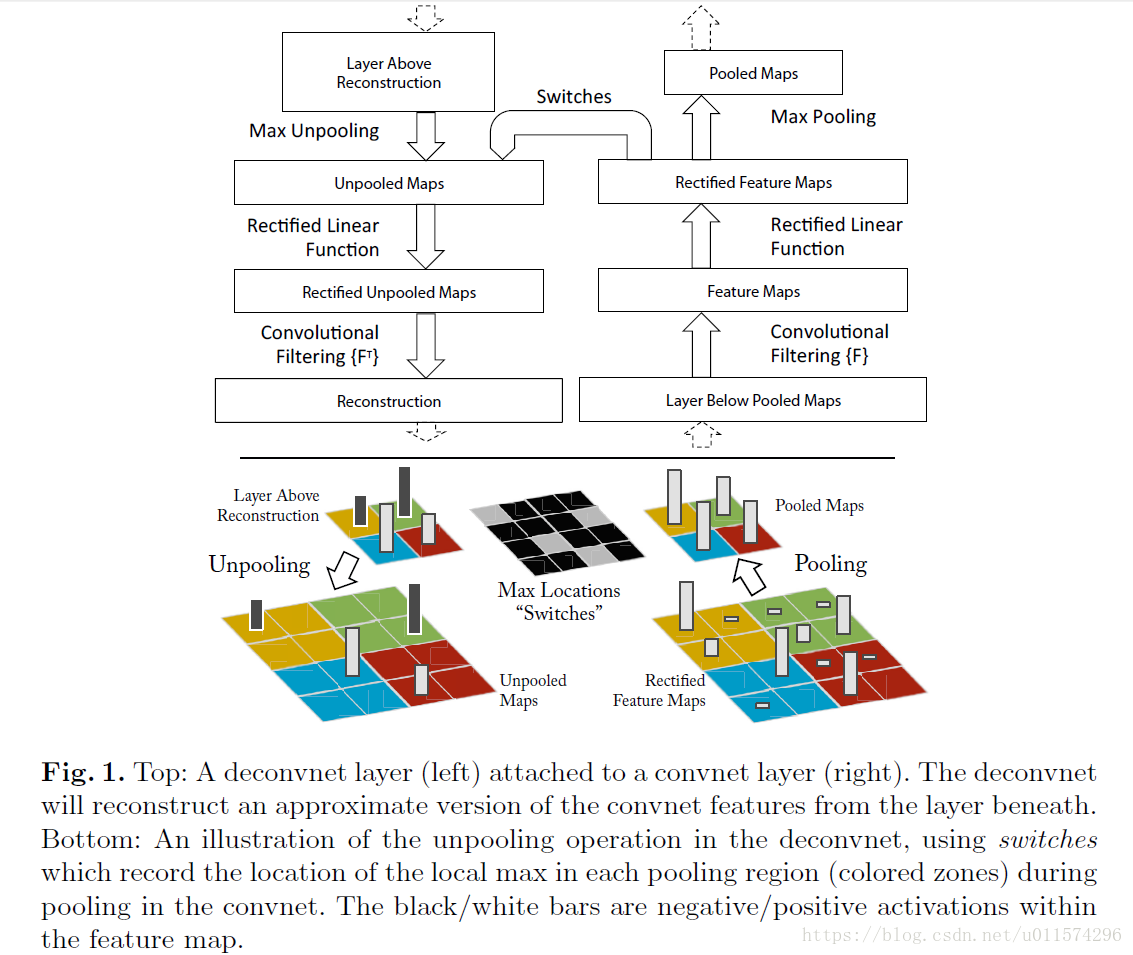
1、反池化过程
我们知道,池化是不可逆的过程,然而我们可以通过记录池化过程中,最大激活值得坐标位置。然后在反池化的时候,只把池化过程中最大激活值所在的位置坐标的值激活,其它的值置为0,当然这个过程只是一种近似,因为我们在池化的过程中,除了最大值所在的位置,其它的值也是不为0的。刚好最近几天看到文献:《Stacked What-Where Auto-encoders》,里面有个反卷积示意图画的比较好,所有就截下图,用这篇文献的示意图进行讲解:
此处输入图片的描述
以上面的图片为例,上面的图片中左边表示pooling过程,右边表示unpooling过程。假设我们pooling块的大小是3*3,采用max pooling后,我们可以得到一个输出神经元其激活值为9,pooling是一个下采样的过程,本来是3*3大小,经过pooling后,就变成了1*1大小的图片了。而upooling刚好与pooling过程相反,它是一个上采样的过程,是pooling的一个反向运算,当我们由一个神经元要扩展到3*3个神经元的时候,我们需要借助于pooling过程中,记录下最大值所在的位置坐标(0,1),然后在unpooling过程的时候,就把(0,1)这个像素点的位置填上去,其它的神经元激活值全部为0。再来一个例子:
此处输入图片的描述
在max pooling的时候,我们不仅要得到最大值,同时还要记录下最大值得坐标(-1,-1),然后再unpooling的时候,就直接把(-1-1)这个点的值填上去,其它的激活值全部为0。
2、反激活
我们在Alexnet中,relu函数是用于保证每层输出的激活值都是正数,因此对于反向过程,我们同样需要保证每层的特征图为正值,也就是说这个反激活过程和激活过程没有什么差别,都是直接采用relu函数。
3、反卷积
对于反卷积过程,采用卷积过程转置后的滤波器(参数一样,只不过把参数矩阵水平和垂直方向翻转了一下),这一点我现在也不是很明白,估计要采用数学的相关理论进行证明。
最后可视化网络结构如下:
此处输入图片的描述
网络的整个过程,从右边开始:输入图片-》卷积-》Relu-》最大池化-》得到结果特征图-》反池化-》Relu-》反卷积。到了这边,可以说我们的算法已经学习完毕了,其它部分是文献要解释理解CNN部分,可学可不学。
反卷积可视化以各层得到的特征图作为输入,进行反卷积,得到反卷积结果,用以验证显示各层提取到的特征图。举个例子:假如你想要查看Alexnet 的conv5提取到了什么东西,我们就用conv5的特征图后面接一个反卷积网络,然后通过:反池化、反激活、反卷积,这样的一个过程,把本来一张13*13大小的特征图(conv5大小为13*13),放大回去,最后得到一张与原始输入图片一样大小的图片(227*227)。
通过反卷积Deconvnet实现可视化:
在每个卷积层都加上了一个反卷积层。在卷积、ReLU、Max-pooling之后,不仅输出给下一层用作输入,也为反卷积提供输入。而反卷积层依次进行unpooling、ReLU和反卷积。见图2。
Unpooling:在max-pooling中利用switches表格记录每个最大值的位置,然后在unpooling中奖该位置填回最大数值,其余位置填0。
ReLU:直接利用ReLU函数,仍然确保输出为非负数。
反卷积:利用相同卷积核的转置作为核,与输入做卷积运算。
训练过程跟以前一样,仍然是从256*256中截取中心和边框五,224*224切片再进行中心翻转,batchsize128,学习率0.01,采用dropout策略。所有权值初始0.01,偏置为0。
2选择激活值:
为了理解某一个给定的pooling特征激活值,先把特征中其他的激活值设置为0;然后利用deconvnet把这个给定的激活值映射到初始像素层。
3反卷积过程deconvnet:
3.1Unpooling
顾名思义就是反pooling过程,由于pooling是不可逆的,所以unpooling只是正常pooling的一种近似;通过记录正常pooling时的位置,把传进来的特征按照记录的方式重新“摆放”,来近似pooling前的卷基层特征。如图中彩色部分
3.2Recitfication
通过ReLU函数变换unpooling特征。
3.3Filtering
利用卷积过程filter的转置(实际上就是水平和数值翻转filter)版本来计算卷积前的特征图;从而形成重构的特征。
从一个单独的激活值获得的重构图片类似原始图片的一个部分。
总是感觉这个过程好熟悉,利用SGD训练卷进网络时,误差的反向传递就是这么计算的,如果是mean-pooling就把残差平均分分配到pooling局域,如果是max-pooling只把残差反馈到记录的max-pooling最max的那个位置。
ZFNet的结构
ZFNet的网络结构是在AlexNet上进行了微调,其网络架构如下: