AlexNet:
( 2012 ILSVRC top 5 test error rate of 15.4%)
第一个成功展现出卷积神经网络潜力的网络结构。
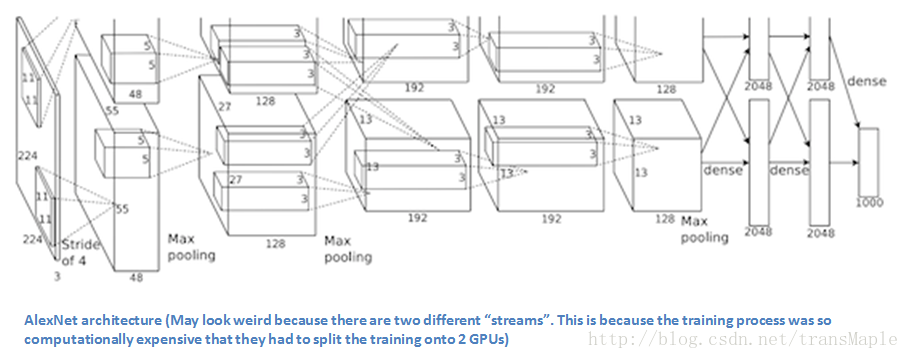
关键点:
- 通过大量的数据与长时间的训练得到最后的模型,结果十分显著(拿到2012分类第一)
- 使用两块GPU,分两组进行卷积。
- 自从Alexnet之后,卷积神经网络开始迅速发展
VGGnet:
(ILSVRC 2014 7.3% error rate)
自Alexnet开始,神经网络便渐渐流行起来,开始各种尝试,最经典的是VGGnet 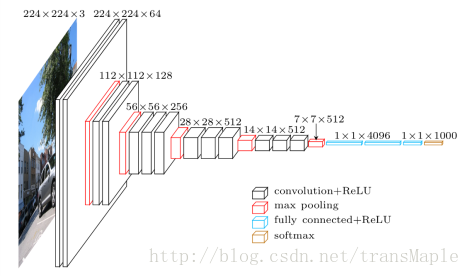
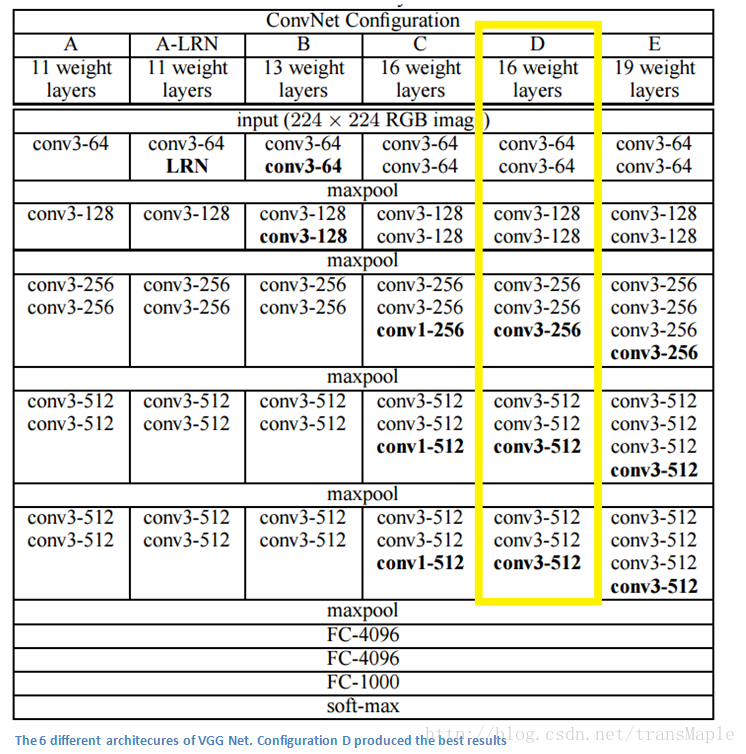
关键点:
- 使用了3x3的filter取代了5x5和7x7,在实测中展示了两个3x3与5x5相比有更好的效果并且参数更少
- 随着网络的深入,层数逐渐增大
- 可以注意到后一个卷积核层数是前一个的两倍,也是降低空间维度,增加深度
- 此网络在分类和定位的任务上都能有很好的变现。
- 训练时使用了数据增强方法
- 这个网络说明了深层的卷积神经网络有十分好的表现
GoogleNet:
(ILSVRC 2014 top 5 error rate of 6.7%)
神经网络除了纵向的扩展,是否能进行横向的拓展?所以出现了第一个使用相叠加的方式的卷积的网络结构,即可以横向扩展。
在传统的转换网络中,每个层从前一层提取信息,以便将输入数据变换成更有用的表示。然而,每个层类型提取不同种类的信息。5x5卷积核的输出告诉我们与3x3卷积核的输出不同的东西,这告诉我们与最大池内核的输出不同,等等。在任何给定的层面,我们如何知道什么转换提供了最有用的信息?
为什么不让模型选择?
于是Inception将1x1, 3x3, 5x5, max-pool结合起来,让网络选择
Inception模块:
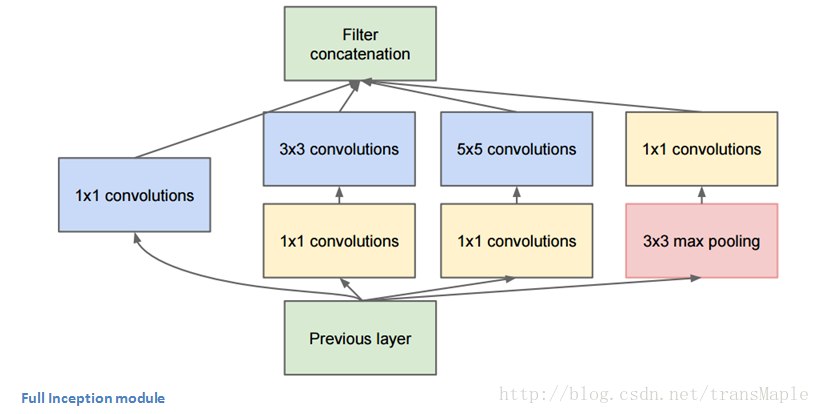
整个网络:
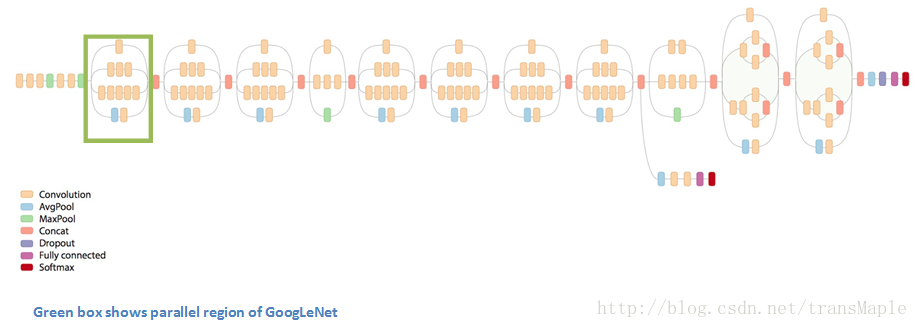
这种模块的意义是,你可能不清楚用一个小的感受野效果好还是大的感受野效果好,可以把这些放一起来评判
关键点:
- 横向扩展
- 使用了1x1的filter,可以很方便的改变卷积结果的层数(1x1的filter也被称为bottleneck)
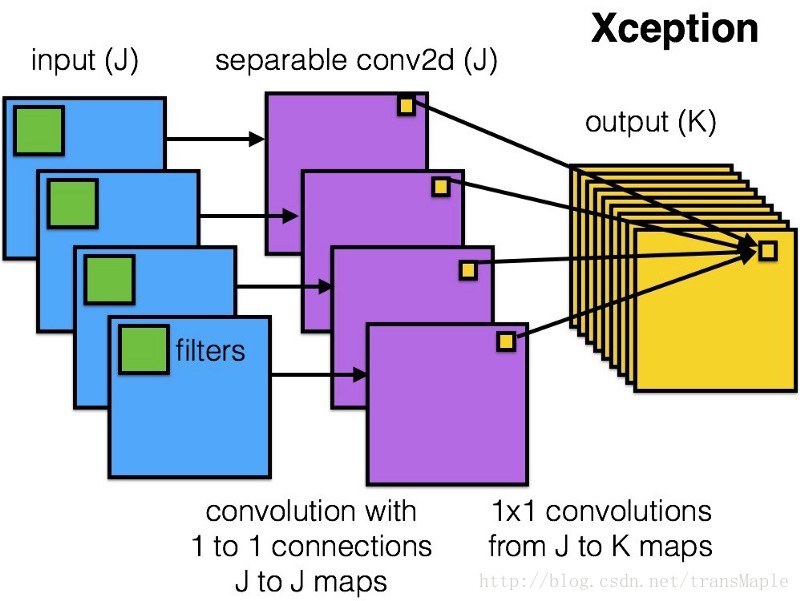
Xception:
Xception基于Inception做的新网络
作者提出一个假设:channel与空间的相关性是完全不相关的,所以最好不要共同映射它们
所以在Xception中采用了“深层可分离卷积”操作,首先每个channel做空间卷积,然后再一起做1x1卷积合在一起。
其效果与Inception v3相比较优,并且参数量不大
Resnet:
( ILSVRC 2015 3.6%)
简单的通过叠加卷积层的方式来增加网络深度,并不能提高模型效果,甚至还会使模型变得更差,更难训练。(Alexnet只有5个卷积层,)
因为此时梯度减缓和梯度消失的现象就会变得十分严重,由于梯度反向传播到较早的层,重复乘法可能使梯度无穷大。结果就是,随着网络的深入,其性能饱和甚至开始迅速恶化。 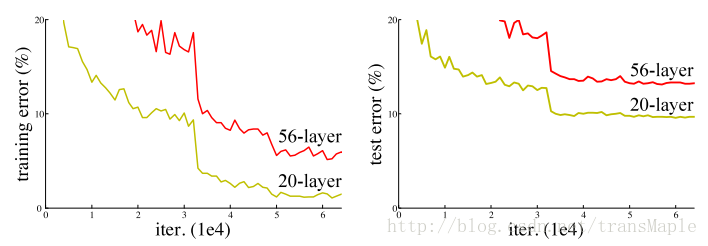
于是为了解决这个问题,MS尝试搭建一个快捷通道(shortcut connections)来传递梯度。
Resnet并不是第一个使用快捷通道(shortcut connections),其中还有Highway Network也由相似的想法,不过最终效果Resnet的比较好。
Residual Block:
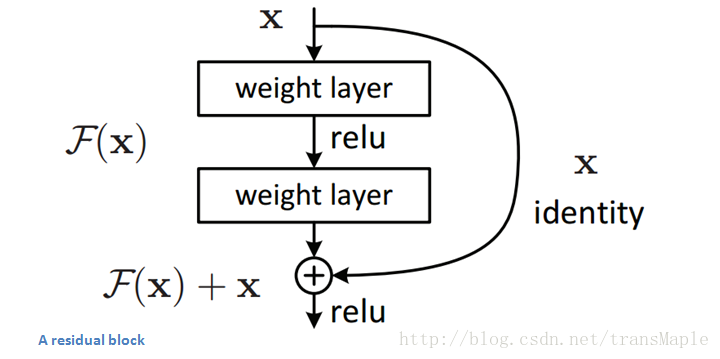
这个block的目的是,作者认为相比原来的网络,这种残差网络更加容易训练。其中的原因为在Residual Network中,当进行网络的反向传播时,梯度可以更加容易的向前传递,因为这个相加操作,可以更容易的传播梯度。
当网络结构变深时,普通的网络就会因为网络太深,出现梯度消失的情况,从而难以训练。

关键点:
- 前面的网络都不够深,而Resnet有152层
- 可以使用Residual block训练更加深层的网络
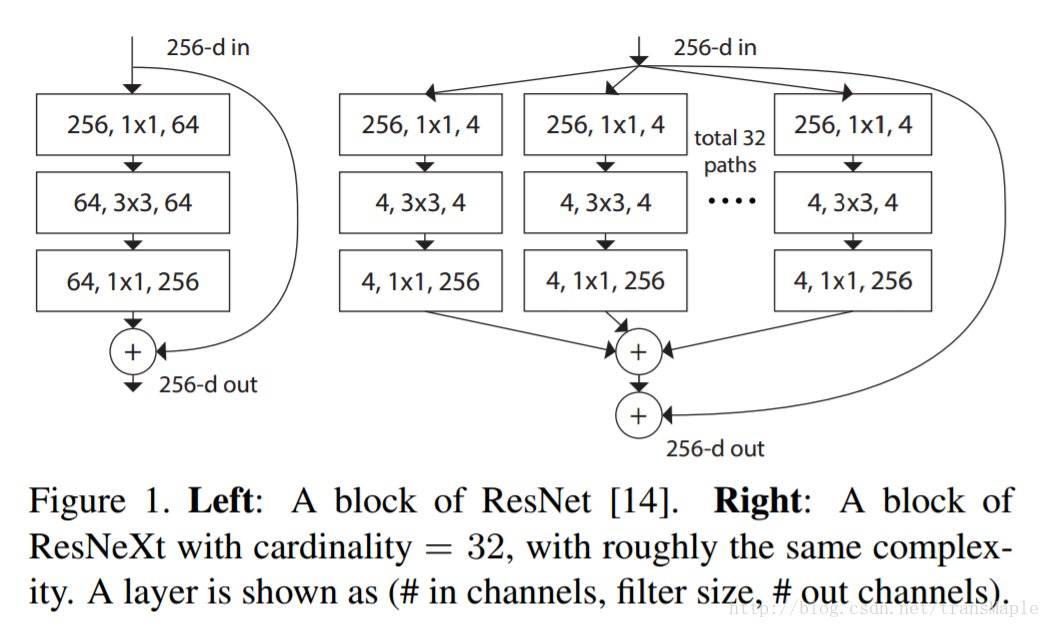
ResNeXt:
ResNeX是Resnet的改版,比Resnet更加有效
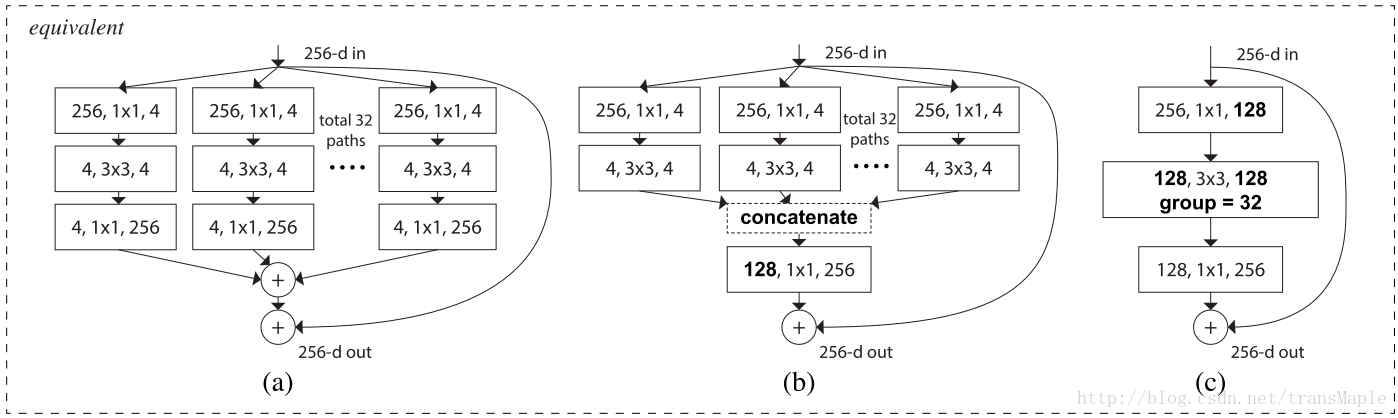
上述三种网络等价(equivalent)
ResNeXt是现在物体识别里 state-of-the-art ,其结合了Inception和Resnet的思想。其宽度十分宽,达到32个层,在论文中也说明,宽度的增加能够给模型更好的效果。与Inception相比,Inception中每个路径彼此不同(1x1, 3x3, 5x5的卷积),而ResNeXt中所有的路径相同,作者还提出了一个参数叫做cardinality——独立路径的数量(上述为32条路径),
DenseNet:Densely Connected CNN
在densenet之前其实就有其他的网络进行更多的跨层连接的尝试,但是densenet更加粗暴,直接将所有的模块连接起来
Dense Block
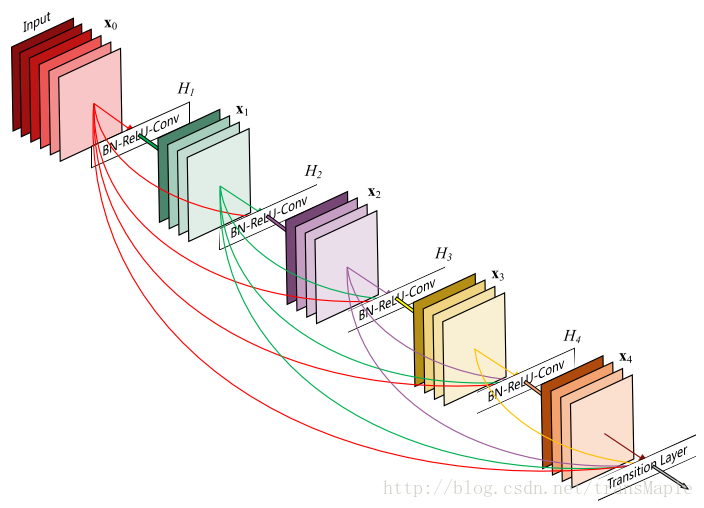
Densenet与Resnet比较: 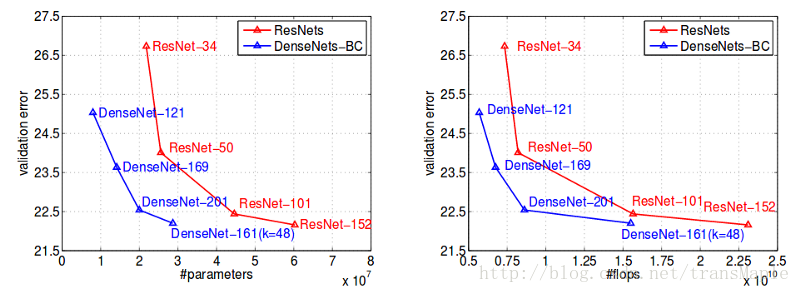
从图中可以看出,其效果较Resnet稍好,而且参数量下降许多,但densenet在训练时会消耗更多的内存,不过对于densenet消耗内存较多的问题已经有一些改进方法。

关键点:
- 组块内全连接
- 参数与Resnet比更少,但训练需要更多内存
Reference:
https://medium.com/towards-data-science/an-overview-of-resnet-and-its-variants-5281e2f56035
https://adeshpande3.github.io/adeshpande3.github.io/The-9-Deep-Learning-Papers-You-Need-To-Know-About.html
https://medium.com/towards-data-science/an-intuitive-guide-to-deep-network-architectures-65fdc477db41