一、Self-attention
[台大李宏毅]
1.1 向量序列的输入
一个序列作为输入:

多个向量输入举例:
一个句子:

声音信号:
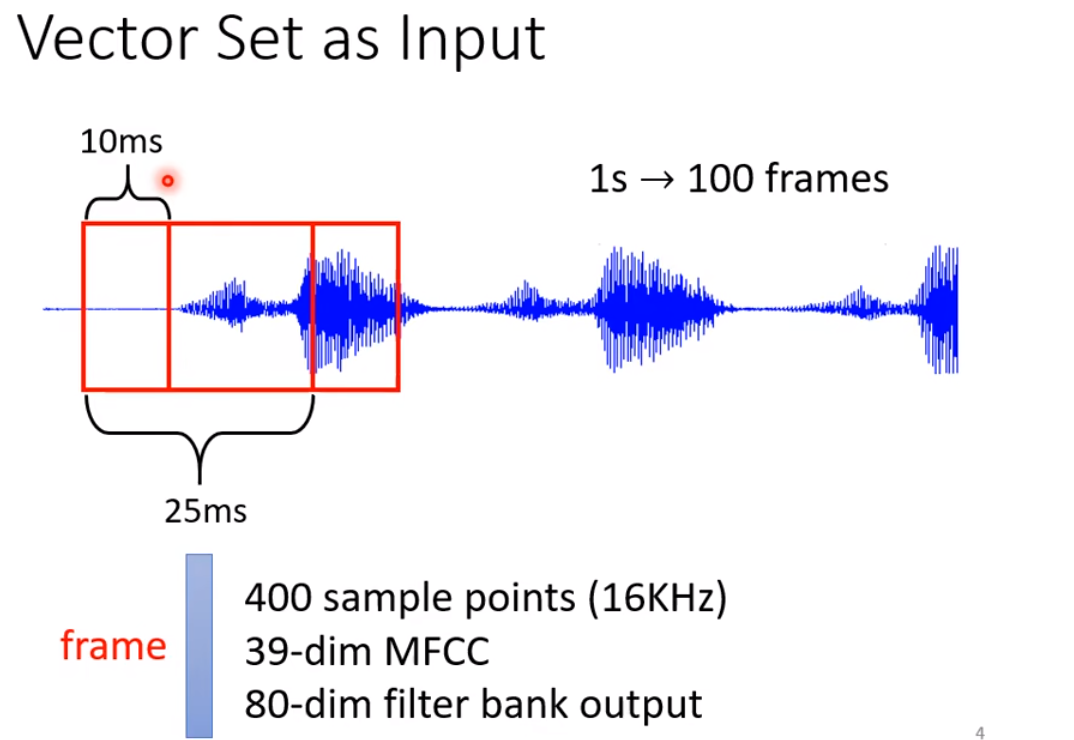
图:


1.2 输出



二、Sequence labeling
输入与输出一样多:Sequence labeling



窗口开的太大,对于每个FC network的参数量会变的很多,计算量很大,那怎么办?Self-attention
三、self-attention
self-attention可以得到一整个序列作为输入 ,输出的每个向量是考虑一整个句子的向量,然后输入到FC中:

self-attention可以叠加:

3.1 self-attention运作机制

找到a1和其他输入的相关性:

a1和a4的相关性是由谁确定的呢? 左边方法最常用

a1分别与其他向量输入做关联性:

a1也会与自己进行关联性计算:

得到α后,需要提取出基于注意力得分的信息:
乘以Wv得到新的向量
新的向量乘以α,然后相加


b1 ... b4是同时计算出来的

从矩阵乘法角度分析运作机制:





[参考]

输入X和三个矩阵相乘分别得到三个矩阵Q,K,V。Q是我们正要查询的信息,K是正在被查询的信息,V就是被查询到的内容
为什么求权重矩阵时候要开根号[参考]?
在我们的两个向量维度非常大的时候,点乘结果的方差也会很大,也就是结果中的元素差距很大,在点乘的值非常大的时候,softmax的梯度会趋近于0,也就是梯度消失。
在原文中有提到,假设q和k的元素是相互独立,维度为dk的随机变量,它们的平均值是0,方差为1,那么g和k的点乘的平均值为0,方差为dk;如果将点乘的结果进行缩放操作,也就是除以dk,就可以有效控制方差从dk回到1,也就是有效控制梯度消失的问题
3.2 multi-head self-attention
Attention机制又为什么需要多头?
原文里提到使用多头注意力的原因是让模型从多个子空间中关注到不同方面的信息。比如我们在学一门外语,现在有一个外语例句,我们去找不同的老师答疑,有的老师告诉了我们每个词的意思,另一个老师告诉我们哪个指代的是哪个词,还有一个老师给我们讲解了一下这句话的语法。我们把几位老师的回答进行一下总结,就可以比较全面地理解这个句子。当然,也不是问的人越多得到的信息就越准确。attention也不一定头越多效果越好。




在进入前馈层之前,我们还有个额外的小操作
现在的我们看到的示意图中,每个子层后面多了一个Add&Norm,它又是什么呢?




现在我们来看看decoder,它和encoder的结构基本一样,但是多了一个注意力层
在deceder的第一个注意力后比之前encoder中的注意力层还多了一个masked前缀,那么mask操作是什么呢?我们又为什么要使用mask ?
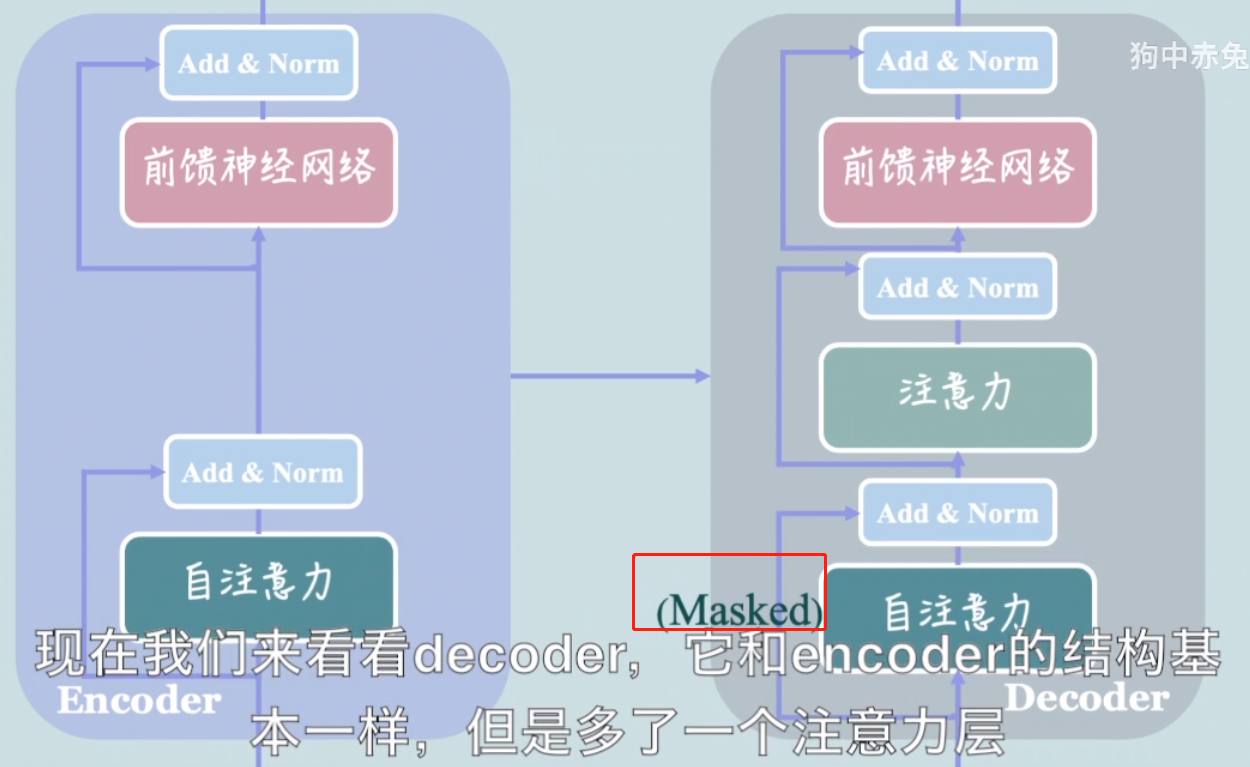
我们需要用到的有两种mask操作。
- 我们输入的序列长度是不一定相同的,对于长度超过我们期望的长度的序列,我们就只保留期望长度内的内容;
- 对于长度没有达到期望的长度的序列,我们就用0来填充它,填充的位置是没有任何意义的。我们不希望attention机制给它分配任何注意力,所以我们给填充过的位置加上负无穷;
因为在计算注意力的时候我们会用到softmax函数,加上过负无穷的位置会被softmax处理变成0这个操作叫做padding mask
在翻译一句话的时候,我们希望transformer按顺序来翻译它,先翻译完前i个单词,再去预测第i+1
个单词;这样的话,我们需要阻止它去注意还不该翻译到的单词,也就是每个单词只能注意到自己和自己之前的单词。

我们用这个矩阵表示计算出来的QK^T,那我们现在要怎么样去遮住每个词后面的单词呢?
如果我们有一个和它大小相同的矩阵,灰色的部分代表被遮住的信息. 和卷积操作很像,我们把它和QK^T对应的位置相乘,再将遮挡的位置加上负无穷. 和之前的padding mask一样得到的结果经过softmax处理之后被遮住的地方就会变成0.
除了在求权重矩阵之前需要和mask矩阵进行对位相乘,这个注意力层和其它的注意力层没有其它区别

它的Q来自上一层的masked attention的输出,K和V来自于encoder的输出
不知道大家还记不记得上一期视频的时候我强调过在机器翻译任务中,词序是很重要的
我咬狗和狗咬我这两句话,由相同的三个字组成但是表达的内容完全不一样,没有采用RNN的transformer好像没有捕捉序列信息的功能,它分不清到底是我咬了狗还是狗咬了我。啊这怎么办啊,transformer不是这块料 要不这样吧,学不会就别学了,放弃吧
Transformer学不会的话,我们可以在transformer外面把问题解决掉嘛
如果我们将输入的文字编码成词向量的时候结合单词的位置信息,它就可以学习词序信息了

Transformer 模型是深度学习领域的一个重要突破,它在自然语言处理和其他序列建模任务中取得了巨大的成功。以下是 Transformer 模型的一些主要特点:
1. **自注意力机制(Self-Attention)**:Transformer 引入了自注意力机制,允许模型在处理序列数据时动态地关注输入序列的不同部分,而无需使用传统的递归或卷积结构。自注意力机制允许模型计算每个输入位置对每个输出位置的重要性权重,从而捕获长距离依赖关系。
2. **并行计算**:由于自注意力机制的并行性,Transformer 模型可以有效地进行并行计算,加速训练过程。
3. **编码器-解码器结构**:Transformer 通常采用编码器-解码器结构,其中编码器用于将输入序列编码成固定长度的表示,而解码器则用于生成输出序列。这种结构在机器翻译等序列到序列任务中非常有用。
4. **多头注意力(Multi-Head Attention)**:Transformer 进一步扩展了自注意力机制,引入了多个注意力头,允许模型以多个不同的方式关注输入序列。这有助于模型学习更丰富和复杂的序列关系。
5. **位置编码(Positional Encoding)**:由于 Transformer 模型不包含任何序列顺序的信息,因此需要引入位置编码来将输入序列的位置信息引入模型。通常使用正弦和余弦函数来实现位置编码。
6. **残差连接和层归一化**:Transformer 使用了残差连接和层归一化来组织模型的层,以稳定训练、减轻梯度消失问题,并加速了训练过程。
7. **注意力掩码(Attention Masking)**:在自然语言处理中,Transformer 可以使用注意力掩码来限制模型在生成序列时的注意力范围,以确保模型不会看到未来的信息,从而保持因果关系。
8. **可扩展性**:Transformer 模型可以轻松扩展到处理不同长度的序列,并且可以适应各种自然语言处理任务,如文本生成、文本分类、问答等。
9. **预训练模型**:Transformer 架构启发了一系列预训练模型,如BERT(Bidirectional Encoder Representations from Transformers)和GPT(Generative Pretrained Transformer),这些模型在自然语言处理领域取得了巨大的成功。
总之,Transformer 模型的主要特点包括自注意力机制、并行计算、编码器-解码器结构、多头注意力、位置编码等,使其成为自然语言处理和其他序列建模任务中的重要工具。它的成功启发了许多后续架构的发展,并对深度学习领域产生了深远的影响。
位置编码的公式:

PE的计算结果是一个行数与序列数相等,列数和模型维度相等的矩阵
pos代表的是目前的token在序列的位置,dmodel代表模型的维度,我们现在先假设它是12吧
i是0到模型维度的二分之一减一之间的所有整数
那么2i和2i+1又代表什么呢?
2就是0到模型维度减一之间的所有偶数维度
2i+1是这个区间内的所有奇数维度
那就不难发现,这个公式用正弦函数sin来给偶数维度编码,用余弦函数CoS给奇数维度编码
是不是对示任意的相对距离K,PEpos+k可以用PEpos的线性函数表示
所以两命位置向量的点乘能够反映它们的相对距离,从而对注意力的计算产生影响
